本笔记来源于B站Up主: 有Li 的影像组学系列教学视频
本节(39)主要介绍: 将训练集的标准化应用在测试集
视频中李博士详细介绍了先fit再transform和fit_transform的区别(就是没啥区别)
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
filePath = 'C:/Radiomics/RadiomicsWorld/data/featureTable/aa.xlsx'
data = pd.read_excel(filePath)
data_train, data_test = train_test_split(data,test_size = 0.3)
print(data_train.shape, data_test.shape)
scaler_fit = StandardScaler()
data_train_fit = scaler_fit.fit(data_train)
print(data_train_fit)
scaler_trans = StandardScaler()
scaler_trans.fit(data_train)
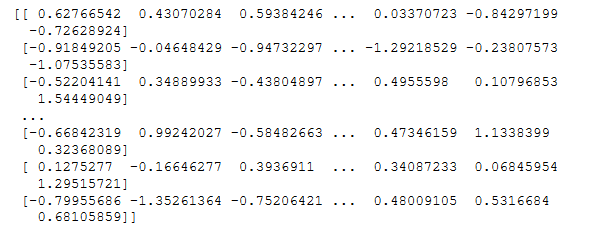
data_train_trans = scaler_trans.transform(data_train)
print(data_train_trans)
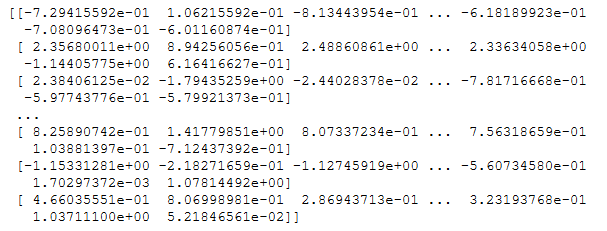
scaler_fit_trans = StandardScaler()
data_train_fit_trans = scaler_fit_trans.fit_transform(data_train)
print(data_train_fit_trans)
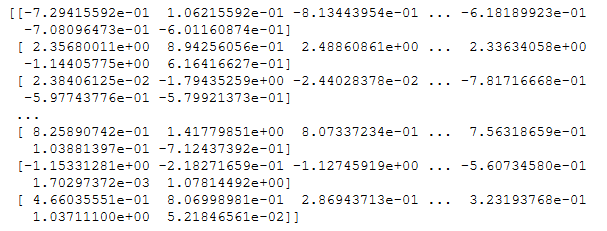
data_test_f_trans = scaler_fit.transform(data_test)
print(data_test_f_trans)
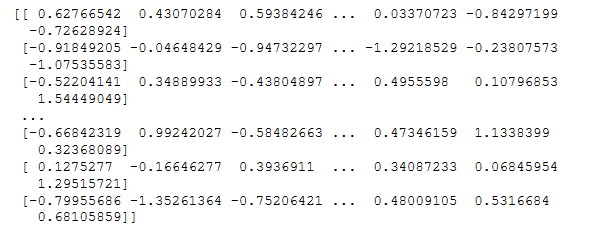
data_test_f_t_trans = scaler_fit_trans.transform(data_test)
print(data_test_f_t_trans)