ltp0810 谢谢,可以使用,引号需要改成英文,在您的基础上给出我的
import pingouin as pg
import pandas as pd
import numpy as np
import os
folderPath = r"E:\CT_ICGR15\feeature_selection\delete"
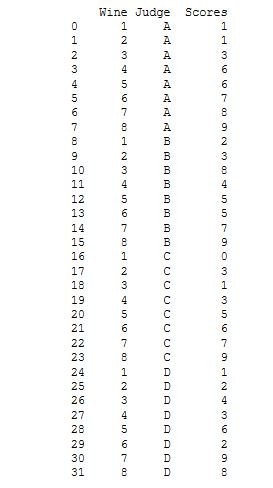
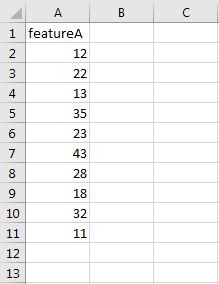
data1 = pd.read_csv(os.path.join(folderPath, “10.csv”))
data2 = pd.read_csv(os.path.join(folderPath, “11.csv”))
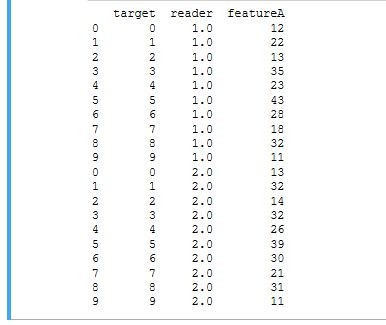
data1.insert(0,“reader”,np.ones(data1.shape[0]))
data2.insert(0,“reader”,np.ones(data2.shape[0])*2)
data1.insert(0,“patient”,range(data1.shape[0]))
data2.insert(0,“patient”,range(data2.shape[0]))
data_inter = pd.concat([data1, data2]) ###组间
print(data_inter.columns)
ICC_inter = [] ##组间ICC
for colName in data_inter.columns[3:]:
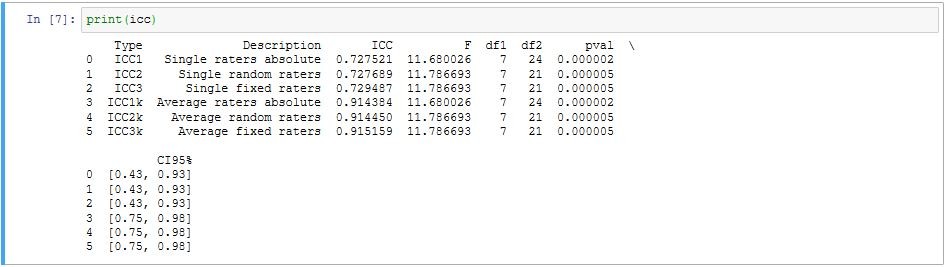
ICC = pg.intraclass_corr(data=data_inter, targets="patient", raters="reader", ratings=colName)
ICC = ICC.iloc[2, 2] ##选择 ICC3 ##选择ICC1时为[0,1], 选择ICC2时后面为[1,2]…
ICC_inter.append(ICC)
print(ICC_inter)
df=pd.DataFrame(ICC_inter)
df.to_csv(‘E:\\ICC_inter.csv’)