2026.6.22
本文提出CFR-SAM,用参数高效微调、层级特征融合和边界引导精炼,将SAM改造为无需复杂后处理的细胞核实例分割框架。
Title题目
01
通过协同细粒度精炼将SAM适配到细胞核实例分割与分类
Adapting SAM to nuclei instance segmentation and classification via Cooperative Fine-Grained Refinement
文献速递介绍
02
论文从全切片病理图像分析的实际需求出发,说明细胞核分割与分类对癌症诊断、肿瘤分级、治疗规划和生存分析具有基础意义。传统人工分析耗时、依赖病理专家经验且一致性有限,CNN方法虽然能捕获局部纹理和细粒度形态,但受限于感受野,难以充分建模全局上下文和长距离关系。SAM等视觉基础模型具有强大的全局建模和跨域泛化能力,因此有潜力用于细胞核实例分割;然而,直接全量微调SAM不仅参数量和存储成本巨大,还容易在有限医学标注数据上过拟合,而且Transformer骨干对细胞核边界、弱对比结构和密集粘连目标的局部感知不足。作者据此提出CFR-SAM,以自动中心点提示结合参数高效SAM适配,实现无需复杂后处理的细胞核实例分割。核心思想是分层补偿SAM的三个缺陷:用MALA增强局部结构感知,用HMFM利用浅层空间细节,用BGMR显式强化边界精炼。
相关工作
相关工作部分首先回顾了细胞核实例分割的发展。传统方法如分水岭和水平集依赖手工特征,对噪声、染色变化和图像质量敏感;深度学习方法如Mask R-CNN、HoVer-Net、STARDIST、CPP-Net等显著提升了性能,但许多方法需要先做语义分割或形态场预测,再通过复杂后处理分离实例,且CNN在全局上下文建模上仍有不足。随后论文讨论了SAM在医学图像中的使用:SAM原本依赖提示,在自然图像上泛化强,但在医学场景中存在领域差异、细结构敏感性不足和手动提示依赖等问题。已有方法如SPPNet、CellViT等尝试将SAM用于细胞核分割,但或无法输出实例信息,或没有充分利用SAM完整的提示编码器和掩膜解码器,或仍依赖复杂后处理。最后,论文梳理了参数高效微调方法,包括Adapter、LoRA和医学SAM Adapter等,并指出现有PEFT策略多在通道维度调整特征,缺少对多尺度局部结构和精确边界的显式建模。
Aastract摘要
03
细胞核实例分割与分类是计算病理中癌症诊断、预后分析和形态学量化的基础任务,但病理图像中细胞核密集、边界模糊、形态差异大,使精确分割十分困难。论文指出,SAM虽然具备强大的全局建模和泛化能力,但直接用于细胞核分割时存在局部结构感知不足、全量微调成本高、浅层细节利用不充分和上采样导致边界模糊等问题。为此,作者提出CFR-SAM框架,先用Prompt Learner自动预测细胞核中心点和类别,再通过MALA、HMFM和BGMR三个模块协同适配SAM,实现细粒度实例掩膜生成。实验在PanNuke、CPM-17和MoNuSeg三个数据集上表明,该方法在bPQ、mPQ、AJI和PQ等指标上达到或超过已有SOTA,同时Ours-H只需训练74.2M参数,约为CellViT-H全量训练参数的10.6%。
Method方法
04
方法部分首先介绍SAM的基本结构,包括ViT图像编码器、提示编码器和掩膜解码器。SAM将输入图像编码为低分辨率特征,提示编码器将点、框或掩膜转化为提示嵌入,掩膜解码器通过双向交叉注意力融合提示与图像特征,并输出低分辨率掩膜后再上采样。CFR-SAM整体分为两个阶段。第一阶段是Prompt Learning,使用轻量级卷积网络预测每个细胞核的中心点坐标和类别标签,从而自动生成点提示;第二阶段是SAM Adaptation,将点提示输入适配后的SAM,由MALA增强骨干局部感知,HMFM融合多层编码器特征,BGMR对初始掩膜做边界引导精炼,最终得到每个细胞核的实例掩膜。分类标签完全由第一阶段产生,并通过点提示顺序与第二阶段输出的掩膜对应。
自动点提示生成
为避免手动提示并提升密集细胞核场景下的定位稳定性,作者设计了Prompt Learner来预测中心点提示。该模块以ConvNeXt-S为骨干的FPN提取多尺度特征,并初始化一组均匀分布的可学习锚点。锚点先经偏移网络得到初步位置,再从多尺度特征图中双线性采样对应特征,随后通过回归头进一步预测到真实细胞核中心的偏移,通过分类头预测细胞核类别或背景。训练时采用匈牙利匹配,将预测锚点与真实细胞核中心建立一对一对应,匹配分数同时考虑类别置信度和空间距离。总损失由分类损失、回归损失和辅助前景分割损失组成。推理时,模型丢弃背景锚点,保留前景锚点作为点提示,同时保存对应类别标签。论文还比较了点提示和框提示,点提示在mPQ和bPQ上明显优于框提示,说明在密集、重叠细胞核中,中心点比边界框提供更干净、更准确的实例定位信息。
多尺度自适应局部感知适配器MALA
MALA是论文最核心的参数高效微调模块,被插入到冻结的SAM Transformer块中。不同于LoRA或普通Adapter主要通过线性映射调整通道特征,MALA在低秩空间中引入自适应多尺度卷积,用少量可训练参数补足SAM对局部核结构的感知能力。具体做法是先将输入特征降维,然后针对3、5、7三种卷积核尺度,根据输入特征动态生成逐位置的深度卷积核,并通过unfold提取对应局部图像块进行深度卷积。多尺度结果平均融合后与原特征残差相加,再通过1×1卷积补充跨通道交互,最后升维回原通道。这样,模型能根据不同区域的细胞核大小、密度和纹理条件自适应选择合适感受野,在保留SAM全局先验的同时增强边界、形状和局部形态特征。消融结果显示,移除MALA会导致mPQ和bPQ下降;与Adapter、LoRA相比,MALA也取得更好分割质量,说明局部多尺度建模是细胞核分割中比单纯增加参数更关键的因素。
层级调制融合模块HMFM
SAM编码器不同层包含不同粒度的信息:浅层保留边缘、纹理和空间位置等细节,深层则更强调语义和全局上下文。原始SAM掩膜解码器主要使用最终编码特征,容易忽略浅层细节,这对边界模糊、目标密集的细胞核分割不利。HMFM通过通道注意力式的自适应调制,将来自SAM编码器多个层级的特征有效融合。作者选取四个层级的输出特征,分别经过1×1卷积、全局平均池化和Sigmoid生成通道权重,再以残差门控方式调制各层特征,最后将调制后的多层特征求和得到融合表示。与简单相加、平均或拼接相比,HMFM能缓解不同层语义不对齐问题,使浅层空间细节与深层语义信息更协调地进入掩膜解码器。消融实验表明,虽然HMFM带来的绝对提升不如MALA和BGMR显著,但其稳定优于常规融合策略,是完整框架中的有效补偿模块。
边界引导掩膜精炼BGMR
BGMR针对SAM掩膜解码器低分辨率预测再上采样所导致的边界模糊问题。模块首先将HMFM输出的语义特征与SAM解码器产生的粗掩膜特征对齐并融合,再上采样到原图分辨率,为后续精炼提供语义基础。随后,MCBE从原始图像中提取多上下文边界特征:输入图像经过卷积得到基础浅层特征,再通过逐步平均池化和卷积形成不同平滑程度的上下文特征,利用特征与局部平滑结果之间的差异增强边缘响应。由于浅层边界特征语义不足,论文进一步设计BGFF,将边界增强特征与上采样语义特征通过普通卷积、可变形卷积和空间注意力进行对齐融合,并用显式边界分割损失监督融合过程。最后,边界导向特征被转化为空间权重,增强语义特征中的边界区域,经瓶颈层和掩膜头输出精炼掩膜。消融实验显示,去除BGMR会使mPQ和bPQ显著下降,去除MCBE、BGFF或边界监督也都会损害性能,说明边界提示、特征对齐和显式监督缺一不可。
训练目标与实现细节
CFR-SAM的第二阶段训练采用多任务损失,同时监督SAM初始掩膜、BGMR精炼掩膜和边界预测。掩膜损失由Focal Loss、Dice Loss和IoU预测误差构成,边界损失使用BCE,并通过权重控制贡献。实现上,作者基于SAM-Base和SAM-Huge分别构建Ours-B和Ours-H。Ours-H用于探索性能上限并与SOTA比较,Ours-B则用于消融和效率对比。训练分两阶段进行:第一阶段训练Prompt Learner,第二阶段冻结SAM主体并训练适配模块和精炼模块。作者解释采用两阶段训练的原因是点提示筛选是离散过程,会阻断从分割损失到Prompt Learner的梯度,若端到端联合训练,在早期提示不稳定时容易导致SAM接收无效输入,因此分离训练更稳定。实验在单张NVIDIA RTX 3090上使用PyTorch实现,优化器为Adam,学习率为1e-4。
实验设置
论文在三个公开细胞核分割基准上验证方法。PanNuke包含7904张H&E染色图像,覆盖19种组织类型和5类细胞核,共189744个标注细胞核,采用三折交叉验证;CPM-17包含64张H&E图像和7570个细胞核标注,训练测试各32张;MoNuSeg包含44张多器官H&E图像,只提供细胞核分割标注而不含分类。评价指标包括AJI、二分类Panoptic Quality即bPQ、多类别Panoptic Quality即mPQ,以及分类任务中的Precision、Recall和F1-score。作者还对PanNuke进行了五次独立运行和统计显著性检验,以证明改进并非随机波动。
主要实验结果
在PanNuke上,CFR-SAM取得最强总体表现。表1显示,Ours-B已超过此前最优模型,Ours-H进一步提升,平均bPQ达到约0.6956,mPQ达到约0.5115;相较CellViT-H,Ours-H在bPQ和mPQ上分别提升约1.63%和1.35%。更重要的是,CellViT-H需要训练699.7M参数,而Ours-H只训练74.2M参数,约为其10.6%。五次独立运行结果显示,Ours-H在mPQ、bPQ和AJI上方差很小,且相对于最强基线的t检验p值均小于0.001,说明性能提升具有统计显著性。分类方面,Ours-H总体检测F1达到约83%,在Neoplastic、Epithelial、Inflammatory、Connective和Dead等类别上的F1存在差异,其中Dead细胞F1较低,反映了稀有类别仍是难点。跨数据集泛化方面,Ours-H在CPM-17上AJI约72.5%、PQ约71.9%,在MoNuSeg上AJI约66.8%、PQ约66.2%,均超过已有方法或复现基线。视觉结果显示,CFR-SAM在密集重叠区域和弱边界场景中能产生更平滑、更准确的细胞核轮廓。
消融实验与效率分析
消融实验系统验证了各模块贡献。与全量微调SAM和只训练头部相比,CFR-SAM以更少可训练参数取得更好结果。移除MALA会使mPQ下降约0.66%、bPQ下降约0.88%,说明局部感知适配至关重要;动态卷积核优于静态卷积核,即使静态核增加参数仍不能追平自适应设计。HMFM优于简单相加、平均和拼接,证明调制式层级融合比朴素融合更合理。BGMR的作用也很突出,若直接使用上采样粗掩膜,mPQ和bPQ分别下降约0.56%和0.83%;进一步移除MCBE、BGFF或边界监督都会降低性能。不同PEFT策略对比中,MALA优于Adapter和LoRA,表明细胞核分割需要显式局部结构建模。低秩维度实验显示64效果最好,过低容量不足,过高可能稀释预训练先验。效率方面,Ours-B训练参数63.4M、总参数153.1M、MACs为89.5G,Ours-H训练参数74.2M、总参数650.5M、MACs为299.7G。作者强调其效率主要是适配阶段的参数效率,而非推理速度最优;由于MALA包含多尺度卷积,FPS并非最高,但换来了更高精度。
讨论与局限
讨论部分强调,CFR-SAM的核心价值在于以参数高效方式弥合SAM全局先验和医学图像局部精度需求之间的差距。MALA将自适应多尺度局部卷积注入冻结骨干,HMFM使浅层细节参与解码,BGMR通过显式边界监督纠正低分辨率掩膜上采样带来的模糊。作者还指出,精确边界和更可靠的实例分离可支持后续的细胞核形态量化,如形状、大小、方向和结构分布,从而可能促进肿瘤分级和预后模型构建。局限方面,首先,稀有细胞类型如Dead细胞的分类性能仍明显低于常见类别,可能与类别不平衡有关。其次,整体性能受第一阶段Prompt Learner限制,在极端密集区域中,中心点偏差可能导致实例合并或漏分。第三,病理图像中的真实细胞核边界本身存在标注不确定性,边界更锐利并不总是意味着生物学上更准确,模型仍受到训练标签质量和观察者差异的约束。
Conclusion结论
05
论文提出CFR-SAM,将Segment Anything Model通过协同细粒度精炼适配到细胞核实例分割与分类任务。该框架明确识别了SAM在该领域的三个核心短板:局部结构敏感性不足、浅层特征利用不充分、解码器上采样导致边界模糊,并分别用MALA、HMFM和BGMR进行针对性补偿。结合自动点提示生成,CFR-SAM能够直接输出高质量实例掩膜,不依赖传统复杂后处理流程。在PanNuke、CPM-17和MoNuSeg上的结果表明,方法在多个指标上达到SOTA,同时显著减少可训练参数。该研究展示了参数高效适配大型视觉基础模型服务专用医学图像任务的可行路径,未来可进一步改进稀有类别学习和极密集区域的提示生成鲁棒性。
Figure图
06
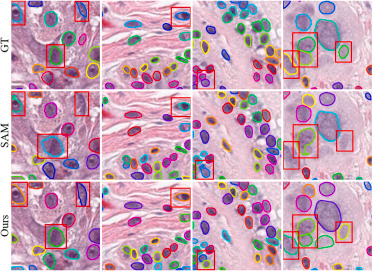
图1.
该图对比真实标注、全量微调SAM和CFR-SAM在细胞核实例分割上的结果。可以看到,全量微调SAM在弱边界、粘连细胞核和密集目标区域仍会出现轮廓不准、漏分或混淆,而CFR-SAM能够更好地捕捉细小边界并区分相邻核。该图直观说明,仅依赖SAM的全局建模和全量微调不足以解决细胞核精细分割问题,需要额外增强局部结构与边界感知。
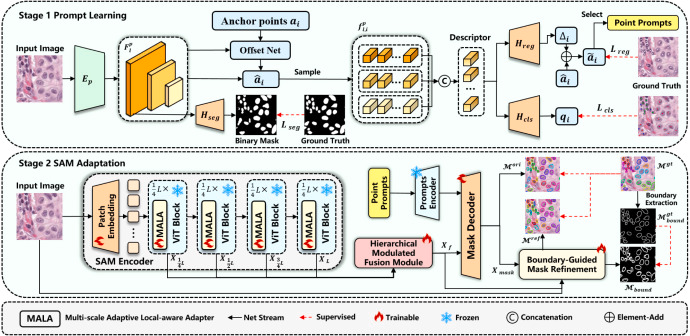
图2.
该图展示了CFR-SAM的完整流程。第一阶段Prompt Learner从输入病理图像中预测细胞核中心点和类别,经过锚点回归、分类和辅助前景分割得到点提示;第二阶段将点提示输入适配后的SAM,图像编码器中插入MALA,编码器多层特征经HMFM融合,掩膜解码器产生初始掩膜,再由BGMR结合边界监督进行精炼。该图是理解整篇论文方法设计的核心框架图。
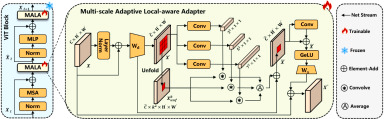
图3.
该图详细展示了MALA如何插入冻结的SAM Transformer块中。MALA先将特征降维到低秩空间,然后动态生成3、5、7三种尺度的逐位置卷积核,对局部图像块进行深度卷积,再通过多尺度平均融合、1×1卷积和残差连接恢复特征。该设计使SAM在保持预训练全局先验的同时获得对细胞核大小、形态和边界的自适应局部感知能力。
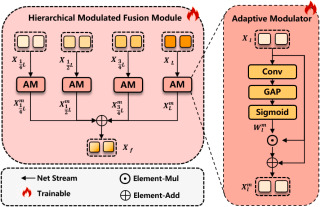
图4.
该图说明HMFM如何从SAM编码器多个层级提取特征,并通过Adaptive Modulator生成通道级权重来调制不同层的表示。浅层特征提供边缘和纹理细节,深层特征提供语义信息,HMFM用残差门控和加和融合将它们整合为解码器输入。该图体现了论文对SAM忽略浅层空间细节问题的针对性补偿。
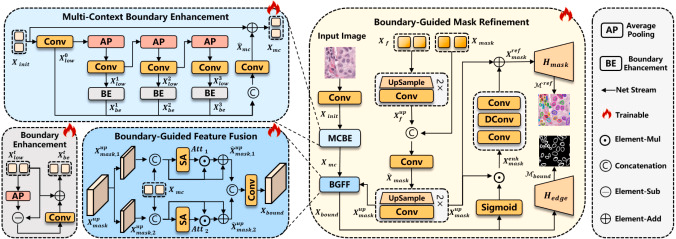
图5:
该图展示BGMR的三个关键环节:MCBE从原图提取多上下文边界增强特征,BGFF将边界特征与上采样语义掩膜特征对齐融合并接受边界监督,最终用边界导向特征增强语义特征并输出精炼掩膜。该模块针对SAM低分辨率掩膜上采样导致的边界模糊问题,帮助模型在密集细胞核区域形成更清晰的分割轮廓。
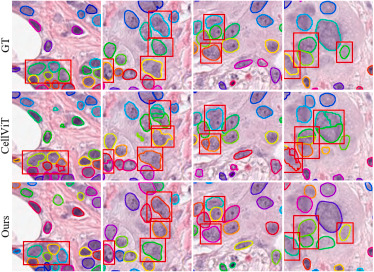
图6:
该图比较了真实标注、CellViT和CFR-SAM在PanNuke上的实例分割结果。红框区域显示,CFR-SAM在相邻细胞核分离、轮廓完整性和边界平滑性方面更接近真实标注,尤其在拥挤和重叠区域能减少实例粘连与边界偏移。该图支持论文关于CFR-SAM优于现有SOTA方法的定性结论。
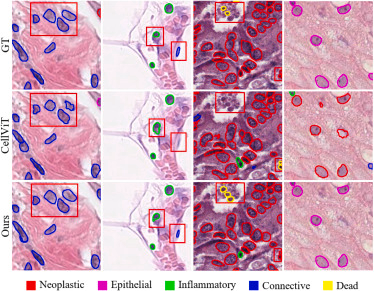
图7.
该图用不同颜色边界表示不同细胞核类别,对比CellViT和CFR-SAM的分类与分割结果。CFR-SAM在若干红框区域中能更准确地定位细胞核并保持类别边界一致,说明第一阶段中心点与类别预测配合第二阶段掩膜生成,可以较好地完成实例级分类关联。该图也显示分类性能仍依赖Prompt Learner质量。
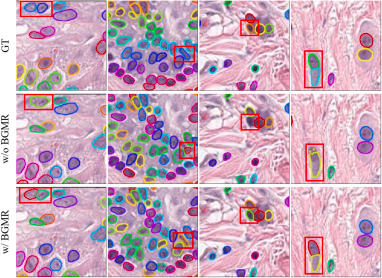
图8.
该图比较去除BGMR和使用BGMR时的实例分割结果。没有BGMR时,细胞核边界更容易模糊、断裂或与邻近细胞核混淆;加入BGMR后,边界更锐利,实例之间分隔更清楚。该图从视觉上验证了边界增强、边界引导融合和显式边界监督对最终掩膜质量的重要作用。
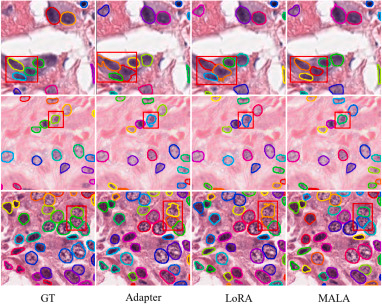
图9.
该图比较Adapter、LoRA和MALA在细胞核分割中的视觉表现。Adapter和LoRA虽然能进行参数高效迁移,但在复杂纹理、弱边界和不同大小细胞核上更容易出现边界不准或实例混淆;MALA由于引入自适应多尺度局部卷积,能更好地捕捉细粒度结构。该图直观支持MALA优于通道线性调整型PEFT方法的结论。