2026.6.16
本文提出 PTCMIL,在 ViT 中用可学习提示 token 进行端到端、任务感知的切片内聚类与原型聚合,提升 WSI 分类、生存预测和跨域适应性能。
Title题目
01
PTCMIL:基于提示 token 聚类的全切片图像多实例学习分析
PTCMIL: multiple instance learning via prompt token clustering for whole slide image analysis
文献速递介绍
02
论文首先指出,组织病理学是癌症诊断、分型和预后评估的重要金标准,而数字病理中的 WSI 尺寸极大,通常需要切成大量 patch 后用多实例学习进行弱监督分析。核心难点在于,一张 WSI 内同时包含正常、肿瘤、间质、血管、血细胞等多种组织形态,并存在染色和形态差异,模型必须把这些异质 patch 聚合为有预测力的切片级表征。早期注意力 MIL 方法通常独立处理 patch,难以捕捉全局上下文;ViT 和 GNN 能建模交互关系,但在长 patch 序列上计算重、扩展性差或容易过拟合。近期聚类原型方法通过把 patch 聚成代表性原型来降低冗余,但往往采用先无监督全局聚类、再训练预测模型的两阶段流程,聚类不受下游任务指导,还可能因采样遗漏关键 patch,并且同一组全局中心难以适应不同切片的个体差异。基于这些问题,作者提出 PTCMIL,把可学习视觉提示 token、聚类、原型学习和下游预测整合到一个端到端框架中,使聚类由切片级预测目标反向引导,从而学习更任务相关、更适合 WSI 的原型。
相关工作
相关工作部分围绕三条线索展开。第一是多实例学习,WSI 被视为由许多 patch 实例构成的 bag,只有 bag 级标签可用,ABMIL、DSMIL、CLAM、TransMIL、图神经网络和多尺度 MIL 等方法分别尝试用注意力、双流结构、Transformer、图拓扑或多尺度信息完成弱监督聚合。第二是 MIL 中的特征聚合与原型学习,由于 WSI 中实例数量远大于标签数量,直接聚合容易受分布差异和冗余干扰,因此一些方法先根据形态或标签相关特征形成原型,再用原型构建切片表征;但这些方法多依赖额外预训练、全局聚类或任务无关聚类,不能让下游预测有效指导原型形成。第三是视觉提示学习,ViT 中的可学习 prompt tokens 能以少量参数帮助模型适应新任务,在自然图像和视觉语言任务中已有成功应用,但在 WSI 分析,尤其是用提示 token 引导聚类和原型聚合方面仍未充分探索。
Aastract摘要
03
全切片图像具有千兆像素规模和强组织异质性,弱监督多实例学习需要在只有切片级标签的条件下把大量 patch 聚合成可靠的切片表征。已有 ViT 方法能建模 patch 交互但计算代价高、易过拟合,传统聚类原型方法多采用两阶段流程,聚类与下游任务脱节且全局聚类成本昂贵。本文提出 PTCMIL,将可学习 prompt tokens 加入 ViT,通过投影式 token 聚类在每张 WSI 内形成任务相关簇,再用 token merging 生成紧凑、可解释的簇原型,并结合 cls token 做分类或生存分析。作者在乳腺、肺、结直肠、前列腺等 11 个基准数据集上验证,PTCMIL 在分类、生存预测和少样本域适应中整体优于多种 MIL 基线,并显示出较好的聚类可解释性与鲁棒性。
Method方法
04
PTCMIL 的整体框架包含三个组成部分:基于可学习 prompt token 的聚类、簇内 token 合并得到原型、以及面向下游任务的全局 pooling。模型先从 WSI 中提取 patch 特征,将 patch tokens、C 个可学习 prompt tokens 和一个 cls token 一起输入全局 Transformer 层,获得包含全局上下文的 token 表征。这里 C 是预设簇数,远小于 patch 数 N。聚类时,作者不计算所有 patch 两两相似度,而是把每个 patch token 投影到各个 prompt token 上,用内积和 softmax 得到 patch 属于每个簇的概率,再按最大概率分配簇。这样每个 prompt token 相当于一个可学习的簇代理,使聚类复杂度从昂贵的全局或二次复杂度降为与 N、C、特征维度 d 线性相关的形式。为防止多个 prompt 学到相同方向而发生簇塌缩,作者用正交初始化、prompt 正交正则项以及移动平均更新策略稳定 prompt 学习。得到簇分配后,PTCMIL 对每个簇内的 patch tokens 和对应 prompt token 输入共享参数的局部 Transformer,以学习簇内上下文。作者强调,prompt token 只是聚类代理,不一定等同于真实簇中心,因此最终用簇内 patch token 的可学习加权平均生成 prototype token,而不是直接拿 prompt token 作为原型。最后,模型把所有簇原型与 cls token 拼接为最终切片表征;分类任务使用交叉熵加正交正则训练,生存预测任务则把生存时间离散化,采用弱监督生存似然损失并加入同样的正则项。
实验设置
实验覆盖分类、生存分析、少样本跨域适应、复杂度分析、可视化解释和消融研究。分类数据集包括 Camelyon16 乳腺癌淋巴结转移检测、TCGA-NSCLC 肺癌亚型分类、TCGA-CRC 结直肠癌基因组亚型分类、BRACS-3 和 BRACS-7 乳腺病变粗粒度与细粒度分类、PANDA 前列腺 Gleason 分级,以及一个内部前列腺 WSI 数据集用于测试从 PANDA 训练到外部数据的域适应。生存分析使用 TCGA 的 LUAD、BLCA、BRCA 和 CRC 四类癌种。特征提取器采用 CTransPath 和 UNI,patch 为 20 倍倍率下非重叠 256×256 区域,特征维度分别为 768 和 1024。对比方法包括 ABMIL、DSMIL、CLAM、DTFD-MIL、TransMIL、ILRA、PANTHER、MambaMIL 和 DGR-MIL。分类指标主要为 AUC 和准确率,PANDA 使用 Cohen’s kappa,生存分析使用 c-index。多数无官方划分的数据集采用五折交叉验证,以更稳健地评估性能。
分类与生存预测结果
在七个分类设置上,PTCMIL 在 CTransPath 和 UNI 两种特征下都表现出很强竞争力。使用 UNI 特征时,PTCMIL 在 Camelyon16 达到 99.60 AUC 和 98.60 准确率,在 TCGA-NSCLC 达到 98.44 AUC 和 93.81 准确率,在 BRACS-3 达到 92.82 AUC,在 BRACS-7 达到 86.31 AUC,在 PANDA 上 Cohen’s kappa 为 0.937,并在 PANDA 到内部前列腺数据的适应测试中达到 92.64 准确率。使用 CTransPath 时也取得相似趋势,例如 Camelyon16 的 AUC 为 98.06,TCGA-NSCLC 的 AUC 为 97.31,内部前列腺适应准确率为 89.96。总体上,PTCMIL 在多数数据集和指标上达到最佳或接近最佳,说明端到端任务感知聚类对不同癌种、不同分类粒度和不同特征编码器均有效。生存分析中,PTCMIL 在 BLCA、BRCA、CRC 上获得最佳 c-index,分别为 0.630、0.745、0.738;在 LUAD 上达到 0.688,与最佳基线 ILRA 持平。作者将这种稳定提升归因于聚类原型学习与下游预测目标联合优化,使模型能够更好捕捉 WSI 异质性中与预后相关的模式。
跨域适应与计算复杂度
作者进一步研究了少样本域适应能力:在 TCGA-NSCLC 与 Camelyon16 之间相互预训练和 20-shot 微调。与只更新分类器的常规做法相比,PTCMIL 允许仅更新 prompt tokens 和分类器,增加极少参数就能更好迁移到新癌种或新数据域。例如从 TCGA-NSCLC 预训练到 Camelyon16 few-shot 时,PTCMIL prompt tokens 加分类器微调达到 69.49 AUC,高于各基线;从 Camelyon16 到 TCGA-NSCLC 时达到 85.73 AUC。复杂度分析表明,传统 K-medoids 需要 O(N²),K-means 和 GMM 还涉及迭代次数及全数据集 patch 数,PANTHER 等全局聚类往往需要采样来降低开销。PTCMIL 的投影式聚类复杂度为 O(CNd),在每张 WSI 内一次完成,使所有 patch 都能参与聚类,同时通过移动平均保留跨迭代的全局 prompt 信息。与 vanilla ViT 相比,PTCMIL 参数几乎不增加,UNI 特征下参数约从 1.58M 增至 1.59M,但 FLOPs 增加明显,例如 C=5 时为 735M、C=7 时为 960M,高于 ViT 的 279M;作者承认这是性能与效率之间的权衡,主要开销来自聚类和重排序。
可视化与解释性
可视化部分展示了 PTCMIL 在 WSI 上学到的簇分配图、簇比例柱状图以及每个簇的示例 patch,并由三位持证病理医师审阅确认。结果显示,不同簇可对应肿瘤细胞、肺泡、血管、间质、红细胞池等具有病理意义的形态区域,说明 prompt token 聚类不是任意分组,而能捕捉与任务相关的组织表型。同时,各簇在不同切片中的比例差异很大,这种差异更多来自切片取材和组织暴露范围,而不一定直接对应器官或标签类别;PTCMIL 能在比例变化下仍识别相似组织形态。与两阶段原型方法 PANTHER 的对比显示,在一些困难 WSI 上,PANTHER 可能出现聚类塌缩或组织区分度不足,而 PTCMIL 能学习更细致的聚类边界和更多组织细节,从而增强模型解释性和实际病理分析价值。
消融研究与超参数分析
消融实验围绕聚类、合并和 pooling 三个核心问题展开。与相同层数和维度的 vanilla ViT 相比,完整 PTCMIL 在 TCGA-NSCLC 分类上提升 0.73% AUC 和 1.30% 准确率,在 TCGA-CRC 生存预测上 c-index 提升约 0.033,说明引入 prompt clustering 有实际收益。合并方式方面,直接用 prompt token 作为原型不如用簇内 token merging 形成 prototype,因为 prompt 更像簇代理而不一定位于真实 patch 簇中心;采用合并原型后,TCGA-NSCLC 分类达到 97.31 AUC、92.17 准确率,TCGA-CRC c-index 达到 0.738。Pooling 方面,单独使用 prototype 或单独使用 cls token 都不如二者结合,表明原型负责异质组织模式,cls token 提供全局补充信息。簇数分析显示,在 3 到 9 的范围内 PTCMIL 均能优于强基线;prompt 相似度热图和 t-SNE 表明,不同簇数下 prompt tokens 仍保持较好正交性和分离度,但 C=9 会出现轻微冗余,因此主实验多选 C=5 或 C=7。正则权重和移动平均衰减因子的分析显示,适度正则与移动平均能提升稳定性,过小或过大都可能损害性能。
Discussion讨论
04
讨论部分总结了 PTCMIL 的主要意义:它把过去分离的聚类和预测过程合并到端到端弱监督学习中,使簇原型更受任务目标约束,从而在分类、生存分析和可视化解释上均取得收益。prompt token 的引入不仅帮助模型学习任务相关簇,也避免了昂贵的全局聚类,在 WSI 这种超长 patch 序列场景中更实际。作者特别强调少样本跨域适应能力,因为只微调 prompt tokens 和最后分类层即可适配新数据集,这对临床中标注稀缺、数据分布差异明显的场景很有吸引力。与此同时,作者也承认 PTCMIL 仍属于弱监督聚类,缺乏显式 patch 级标签时可能遗漏细粒度病理特征;最终聚类结果仍受 prompt 初始化、预设簇数、正则权重等超参数影响。未来方向包括自动选择簇数、层级聚类,以及引入临床先验或视觉语言模型来进一步指导聚类。
Conclusion结论
05
PHIVE为7T全脑MRSI代谢物定量提供了一种快速、无监督、物理可解释并带不确定性评估的谱拟合框架。它能在毫秒级处理完整全脑数据集,定量结果与LCModel总体相近,并输出CRLB、模型不确定性和数据不确定性地图,增强了结果解释和质量控制能力。条件基线机制进一步提高了对复杂谱基线的适应性。尽管仍需更大规模、多中心、跨序列和有真值数据验证,PHIVE展示了将实时MRSI量化纳入科研和临床工作流的潜在价值。
Results结果
06
本文提出 PTCMIL,一种基于 ViT 的端到端可学习聚类 MIL 聚合方法,面向 WSI 的巨大尺度和组织异质性问题。通过在 ViT 中加入可学习 prompt tokens,并用投影式聚类和 token merging 生成任务相关原型,PTCMIL 能同时学习原型表征和下游预测目标。大量实验表明,该方法在多种癌症 WSI 分类、生存预测和域适应任务中整体优于现有 MIL 基线,并在困难切片上提供更细致、可解释的聚类结果。作者认为,这验证了弱监督条件下同时学习组织原型与预测任务的可行性,并为发现可解释的病理模式或潜在生物标志物提供了新途径。
Figure图
07
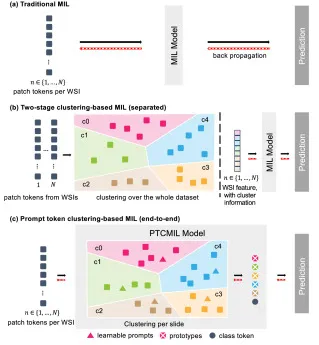
图1.该图对比了传统 MIL、两阶段聚类原型 MIL 与 PTCMIL。传统 MIL 直接把 WSI 的 patch tokens 输入聚合模型做预测,不显式建模组织簇;两阶段方法先在多个 WSI patch 上做全局聚类,再把带簇信息的表示交给 MIL 模型,聚类和预测相互分离;PTCMIL 则在每张 WSI 内用可学习 prompt tokens 引导聚类,并在同一模型中反向传播预测损失,使聚类、原型生成和切片级预测端到端联合优化。图中突出了本文的核心主张:相比任务无关的外部聚类,任务引导的切片内 prompt token clustering 更能形成适合下游诊断或预后任务的原型。