2026.6.15
本文提出 PASS-Tr,通过逐块跨切片 Swin 注意力融合相邻 CT 切片,并接入二维视觉基础模型,以提升通用病灶检测及其他 CT 任务的泛化能力。
Title题目
01
基于逐块 Swin 切片注意力的二维大视觉模型泛化增强通用病灶检测
PASS-Tr: PAtch-wise swin slice attention to leverage generalization of 2D large vision model to universal lesion detection
Multimodal medical endoscopic image analysis via progressive disentangle-aware contrastive learning
文献速递介绍
02
本文从 CT 图像的伪三维特性出发,讨论通用病灶检测中二维网络与三维网络的长期取舍。CT 由连续二维切片组成,但切片间距通常为 1 到 5 mm,因此并非理想的各向同性三维体数据。三维网络能够直接建模体积上下文,但通常需要大量显存,训练时还常被迫裁剪成小块,且缺乏成熟的三维预训练模型。二维网络效率更高,也能直接利用 SAM、ViT、MedSAM 等强大的二维预训练模型,但单切片输入难以理解病灶在相邻层面的连续变化。多切片融合因此成为折中方案,即用关键切片及其上下邻近切片共同输入二维编码器,再在特征层面融合近似三维上下文。作者指出现有方法主要存在三个问题:整张切片级融合粒度过粗,容易引入冗余或无关信息;虽然基于二维网络,却很少系统利用二维大视觉基础模型;评价通常局限于 DeepLesion 病灶检测,缺乏跨 CT 任务验证。为解决这些问题,作者提出 PASS-Tr,通过基于 Swin Transformer 的逐块窗口注意力在局部区域内融合相邻切片信息,并进一步验证其在 COVID 病灶分割和 104 器官分割中的泛化能力。
相关工作
相关工作首先回顾了 CT 通用病灶检测。许多方法借鉴放射科医生阅读相邻切片的临床习惯,将关键切片与邻近切片共同输入二维 CNN 检测器,例如中间层特征融合、A3D 非对称三维上下文融合、MVP-Net、多任务病灶分析网络以及基于 Transformer 的 SATr。尽管这些方法证明了多切片上下文的重要性,但大多仍在整切片或较粗粒度上融合,可能混入无关组织信息。作者还强调 DeepLesion 原始标注不完全,因此部分实验也使用修订测试集以提高比较可靠性。其次,论文讨论了 CT 通用器官分割,特别是 TotalSegmentator 数据集覆盖 104 个结构,任务跨度从头到脚,解剖结构差异极大。现有 TotalSegmentator 基线通常依赖多个针对不同结构类别的 nnU-Net 模型,部署复杂且推理成本高,而 PASS-Tr 尝试用单一端到端模型完成多结构分割。最后,论文回顾 COVID CT 病灶分割,指出许多方法把它当作二维分割问题,忽略 CT 自带的层间上下文;PASS-Tr 可以作为二维网络的跨切片上下文增强模块插入 U-Net 和 nnU-Net 等基线。
Aastract摘要
03
本文关注 CT 中通用病灶检测面临的二维网络缺乏三维上下文、三维网络计算开销大且难以利用二维预训练模型的问题。作者提出 PASS-Tr,即 PAtch-wise Swin Slice Attention Transformer,在二维多切片框架中以窗口级、逐块的方式对关键切片与相邻切片特征进行注意力融合。该方法将关键切片、相邻切片和所有切片分别映射到不同的 q-k-v 输入,并可融合 SAM、SAM2、ViT、MedSAM、SAM-Med2D 等二维大视觉模型特征。实验显示,PASS-Tr 在 DeepLesion 通用病灶检测上优于 SATr 和多种 SOTA ULD 方法,在 Seg-C19 COVID 病灶分割与 TotalSegmentator 104 器官分割上也能带来稳定增益。研究表明,细粒度多切片融合是兼顾二维模型效率、二维预训练能力和 CT 三维上下文建模的一条有效路径。
Method方法
04
方法部分以三切片输入为代表说明 PASS-Tr,但实际实验可扩展到七切片等设置。输入包括关键切片及其上下相邻切片,模型只预测关键切片的标签,相邻切片仅作为上下文辅助。编码器由多个二维 CNN 编码块组成,每个切片通过相互独立的子编码路径提取特征,使不同切片在融合前保持独立表示。这一点不同于直接将切片堆叠成三维体数据,也使方法能够较容易地迁移到其他二维主干网络。特征融合模型包含两条路径:一条是使用 3×1×1 的三维卷积进行直接跨切片融合,另一条是本文核心 PASS-Tr block。最终两条路径的输出拼接后送入解码器或检测头。PASS-Tr block 由 Patch Embedding Generation 和 Slice Feature Attention 两阶段组成。前者将每个切片的特征图按 Swin Transformer 风格划分为标准窗口和 shifted window,但与标准 Swin 顺序执行不同,PASS-Tr 将两类窗口并行处理,以保持各切片特征隔离并减少冗余扩散。窗口化后,作者构造三类嵌入:关键切片嵌入、相邻切片嵌入以及所有切片嵌入。后者进入注意力模块时分别承担不同角色:相邻切片特征作为 query,关键切片特征作为 key,所有切片特征作为 value。这样的设计意图是让关键切片保持主导地位,同时让邻近切片提供三维上下文信息。PASS-Tr 还可以接入二维大视觉模型:每个 CT 切片可独立经过 LVM 编码器提取外部特征,这些特征可单独使用,也可与 ULD 主干编码器特征逐元素相加后进入融合模块。解码器部分保持与原二维网络兼容,通过三维卷积和 CNN 解码模块生成关键切片预测,因此 PASS-Tr 可以作为插件插入多种现有二维检测或分割框架。
实验设置
实验覆盖三个 CT 任务。DeepLesion 用于通用病灶检测,包含 4427 名患者、10594 次 CT 研究、32120 张轴向切片和 32735 个病灶,病灶类型和大小差异很大。作者遵循官方 70%、15%、15% 的训练、验证、测试划分,并额外在 25% 和 50% 训练数据设置下评估低数据场景,还在修订测试集上验证稳定性,检测指标为不同 FPPI 下的 sensitivity。Seg-C19 用于 COVID 病灶分割,包含 35 名患者的 908 张标注 CT 切片,作者使用 72、352、724 张训练图像比较不同数据量下的表现。TotalSegmentator 用于 104 个解剖结构分割,包含 1204 个 CT 检查,作者划分 1082、57、65 例训练、验证、测试,并报告五折交叉验证平均结果。所有实验在四张 NVIDIA RTX 3090 GPU 上进行,batch size 总计为 8,典型输入 patch 大小为 512×512×7。为公平比较,PASS-Tr 被插入现有二维网络时保持原网络学习率、损失函数、优化器和训练配置一致。
DeepLesion 通用病灶检测结果
在 DeepLesion 上,PASS-Tr 被集成到多种 SOTA ULD 方法中进行比较。结果显示,不引入 LVM 特征时,PASS-Tr 已能为所有测试的 ULD 基线带来性能提升。以 A3D 为例,A3D+PASS-Tr 在完整训练数据和官方测试集上达到 88.29% 平均 sensitivity,超过此前 A3D+SATr 的 87.92%,说明逐块 Swin 切片注意力优于原先标准 Transformer 式的 SATr 融合。低数据量场景下,PASS-Tr 的增益更明显,因为切片注意力能在训练样本不足时补充更有效的层间上下文。关于 LVM 特征,SAM 和 SAM2 这类自然图像基础模型在 25% 数据下可带来轻微提升,但在 50% 和 100% 数据下可能略微降低 ULD 性能,作者将其归因于自然图像与 CT 的域差异。SAM-Med2D 作为医学图像模型,在低数据条件下提供更稳定的小幅收益,但由于其主要面向分割而非检测,提升也有限。作者进一步通过对 SAM 在 TotalSegmentator 上微调的对照实验验证了域差异解释:原始 SAM 低于微调 SAM,微调 SAM 又低于 SAM-Med2D。总体而言,LVM 对最终检测精度的帮助取决于域匹配和数据量,但几乎都能加速早期训练收敛。
COVID 病灶分割结果
在 Seg-C19 COVID 病灶分割任务中,作者将 PASS-Tr 插入 U-Net 和 nnUNet 两个二维分割基线。与只处理单张 CT 切片的二维基线不同,PASS-Tr 利用目标切片周围的相邻切片提供上下文,但不要求邻近切片有额外分割标注。实验显示,PASS-Tr 对 U-Net 在 72、352、724 张训练切片设置下分别带来 1.41%、3.16%、2.06% 的提升,对 nnUNet 分别带来 1.42%、1.45%、2.03% 的提升,并且优于 SATr 的对应表现。引入 LVM 特征后,SAM、SAM2 和 SAM-Med2D 均能进一步改善分割,其中 SAM-Med2D 的收益最大。与 nnUNet+PASS-Tr 结合时,SAM-Med2D 在三种训练数据规模下取得 68.44%、73.55%、74.87% 的 Dice,成为整体最佳结果。这说明对分割任务而言,医学域二维基础模型的表征与病灶分割目标更一致,因此比自然图像模型更有帮助。
TotalSegmentator 器官分割结果
在 TotalSegmentator 104 器官分割任务中,作者比较了 U-Net 2D、U-Net 3D、nnUNet 2D、nnUNet 3D 及其加入 PASS-Tr 后的表现,并报告 2D Dice 和 3D Dice。结果表明,PASS-Tr 能显著提高二维模型对三维结构的理解:U-Net-2D 加入 PASS-Tr 后,2D Dice 提升 4.97%,3D Dice 提升 11.40%;nnUNet-2D 加入 PASS-Tr 后,2D Dice 提升 5.85%,3D Dice 提升 7.51%。更重要的是,加入 PASS-Tr 的二维模型甚至超过纯 3D 版本,例如相对 U-Net-3D 在 2D 和 3D Dice 上分别高 0.97% 和 1.80%,相对 nnUNet-3D 分别高 2.13% 和 3.12%。这说明在 CT 各向异性和显存受限场景中,精心设计的 2.5D 多切片融合可以比直接三维建模更实用。与 DeepLesion 类似,SAM 和 SAM2 的自然图像域特征对器官分割帮助有限甚至有负面影响,而 SAM-Med2D 与 PASS-Tr 结合取得最佳总体性能,2D Dice 为 92.33%,3D Dice 为 84.51%。
消融实验与设计分析
网络设计消融验证了 PASS-Tr 两个核心部件的必要性。对于 Patch Embedding Generation,作者比较了无窗口的 naive Transformer、加入标准窗口、顺序加入 shifted window 以及完整并行窗口设计。结果呈现逐步提升,完整 FPE 取得最佳性能,说明局部窗口化和并行 shifted window 有助于在减少冗余的同时捕获有效上下文。对于 Slice Feature Attention,作者比较了多种 q-k-v 输入配置,最终使用相邻切片作 query、关键切片作 key、所有切片作 value 的设计最好。这一结果支持作者的假设:关键切片应作为判别主轴,相邻切片应主要承担上下文查询与补充作用。超参数消融显示,8×8 窗口在 DeepLesion 上最优;过小窗口难以覆盖完整病灶区域,过大窗口会引入冗余信息并增加训练难度。通道数方面,64 通道表达不足,256 通道计算成本更高而性能收益很小,因此 128 通道是较平衡选择。切片数方面,3、5、7 切片性能依次提升,但更多切片会增加计算负担。作者还比较了平均池化、3D 卷积、特征拼接、CQformer、CSA-Net 等跨切片融合策略,发现简单融合虽优于单切片基线,但明显不如注意力式融合,而 PASS-Tr 在高复杂度注意力方法中表现最好。
二维到三维主干转换分析
作者还专门讨论了为什么不直接把二维预训练主干转换为三维主干。实验以 TotalSegmentator 的 104 器官分割为例,将 2D nnU-Net 权重用 I3D 卷积核膨胀、Depth-wise Adapter、Slice-wise Distillation 等方式迁移到 3D nnU-Net。结果显示,I3D 能带来一定提升但有限;Depth-wise Adapter 因冻结大部分膨胀权重,难以适应二维和三维特征分布差异,表现较差;Slice-wise Distillation 通过额外伪标签预训练能显著提高初期效果,但在总训练轮数相当时优势减弱,且伪标签质量不如人工标注。作者据此认为,二维模型通常在完整或较大范围的切片上学习,而三维模型多在小三维 patch 上训练,二者特征分布和空间感受野差异较大,直接权重迁移并不理想。PASS-Tr 的思路是保留二维模型处理关键切片的优势,同时通过相邻切片特征融合弥补三维上下文缺失,因此比直接 2D-to-3D 转换更适合利用成熟二维预训练权重。
可视化结果与计算效率
可视化部分展示了 PASS-Tr 在检测结果、CAM 激活图和训练收敛方面的优势。在示例检测中,A3D 容易产生较多假阳性,SATr 能减少部分错误但仍可能把正常组织误判为病灶,A3D+PASS-Tr 则能更准确聚焦病灶并减少误检。CAM 结果显示,多切片融合比单切片方法减少了冗余激活,而 PASS-Tr 相比卷积融合和 SATr 更能在窗口内捕获相关依赖,并抑制空气区或无关组织的激活。雷达图显示,将 SAM 或 SAM-Med2D 特征加入 PASS-Tr 后,虽然最终精度未必总是提升,但训练早期正 ROI 数量增加,说明 LVM 特征有助于更快、更稳定地收敛,且 SAM-Med2D 在医学任务上加速更明显。失败案例主要集中在少数类别、大层厚和微小病灶,提示模型仍受类别不平衡、切片间距变化和小目标检测难度影响。计算效率方面,A3D+PASS-Tr 参数量从 A3D 的 21.93M 增至 41.26M,显存从 4435 MB 增至 7539 MB,推理速度从 10.7 cases/s 降至 8.8 cases/s,但平均性能从 86.54 提升到 88.29。与 FasterRcnn 3D 的 11231 MB 显存和 7.4 cases/s 相比,PASS-Tr 仍更高效。离线使用 SAM 或 Med-SAM 预计算特征时开销较小,而在线执行基础模型会显著降低速度。
Conclusion结论
05
论文总结认为,三维 CT 分析中二维网络与三维网络各有优势和短板。三维网络擅长体积上下文建模,但显存占用高、预训练资源不足;二维网络高效且可借助大量二维预训练模型,但天然缺少层间信息。PASS-Tr 通过多切片融合在两者之间建立折中:保持二维网络和二维基础模型的可用性,同时用逐块 Swin 切片注意力捕获局部三维上下文。实验覆盖 DeepLesion 病灶检测、Seg-C19 COVID 病灶分割和 TotalSegmentator 104 器官分割,说明该模块不仅能提升 ULD,还能推广到其他 CT 分析任务。整体上,PASS-Tr 被定位为一种可插拔、较高效且具有跨任务泛化潜力的 CT 多切片融合模块。
未来工作
作者计划在未来进一步开展分布外测试,使用来自不同机构、扫描仪和临床协议的外部 CT 数据集评估 PASS-Tr 的鲁棒性和域泛化能力。这一点很重要,因为本文主要实验仍集中在 DeepLesion、Seg-C19 和 TotalSegmentator 这些相对固定的数据集上,真实临床场景中的扫描参数、病灶类型、图像噪声和人群分布可能更加复杂。作者还计划探索与更多大规模医学基础模型结合,并研究向 MRI、PET-CT 等其他模态迁移的可能性。如果这些方向得到验证,PASS-Tr 的逐块跨切片注意力思想可能从 CT 病灶检测扩展为更通用的医学体数据分析范式。
Figure图
06
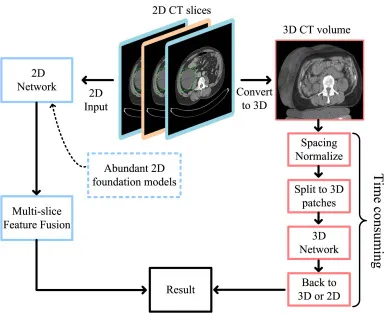
图1.该图从整体上说明本文的问题背景。左侧展示多切片融合路线:保留二维网络输入形式,通过关键切片和相邻 CT 切片提取近似三维上下文,并可利用 SAM、SAM2、SAM-Med2D 等二维基础模型。右侧展示传统三维网络路线:需要将连续切片转换成三维体数据,再进行 spacing 归一化、三维 patch 切分和三维网络推理,显存消耗和流程复杂度更高。这张图解释了 PASS-Tr 选择 2.5D 多切片融合而非纯 3D 建模的动机。
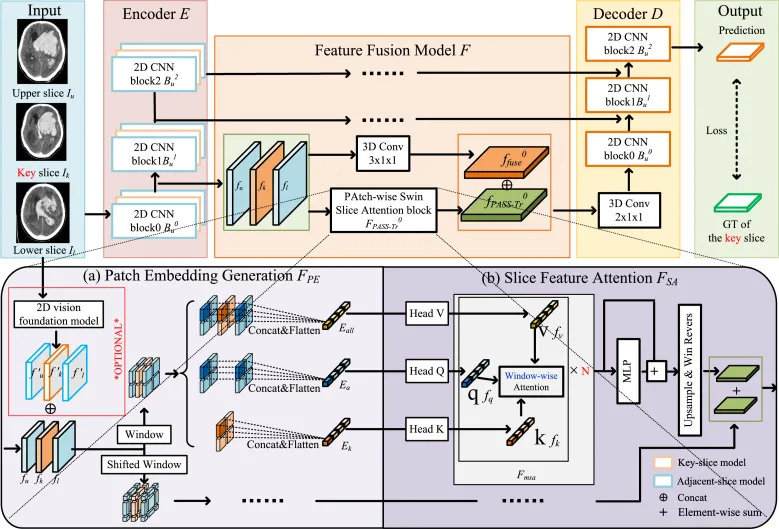
图2.该图是论文最核心的方法图。上半部分展示多切片方法的五个组成:输入、编码器、特征融合、解码器和输出;PASS-Tr 被插入特征融合模块,并与 3D 卷积分支共同形成双路径融合。下半部分详细展示 PASS-Tr block:先在 Patch Embedding Generation 中对关键切片、相邻切片和所有切片生成窗口化嵌入,并可选接入二维 LVM 特征;再在 Slice Feature Attention 中将所有切片作为 value、相邻切片作为 query、关键切片作为 key,通过窗口级注意力完成逐块跨切片融合。该图体现了 PASS-Tr 的关键创新,即以局部窗口而非整切片为粒度融合三维上下文。
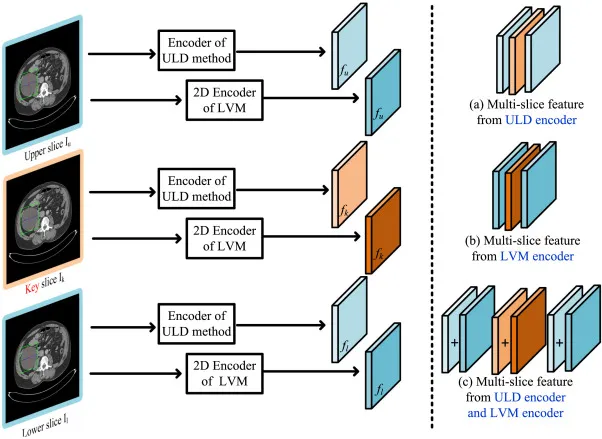
图3.该图说明 PASS-Tr 如何利用二维 LVM。每个 CT 切片既可以经过 ULD 主干编码器,也可以经过 SAM、SAM2、SAM-Med2D 等二维 LVM 编码器。右侧给出三种特征组合方式:只用 ULD 编码器特征,作为常规监督模型;只用 LVM 特征,类似基于 LVM 的微调;将 ULD 特征与 LVM 特征相加,使监督模型继承 LVM 的泛化表征。该图解释了为什么 PASS-Tr 能在二维预训练模型和多切片 CT 上建立连接。
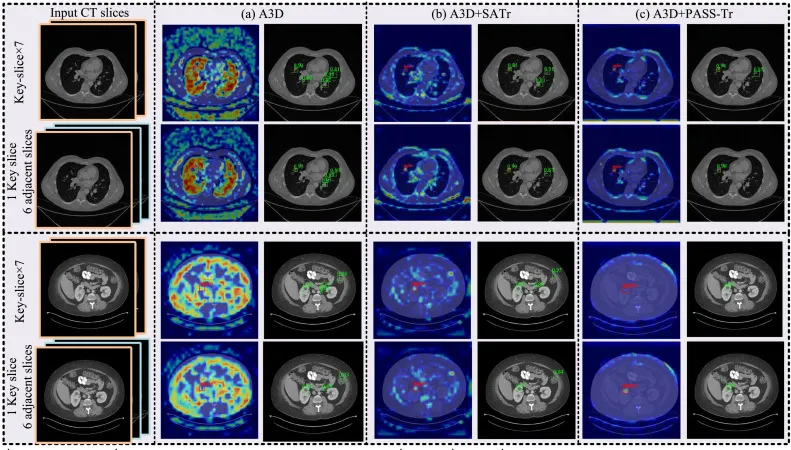
图4.该图比较 A3D、A3D+SATr 和 A3D+PASS-Tr 在两个 CT 病例中的检测框和 CAM 激活。A3D 的激活区域较分散,检测中存在较多假阳性;SATr 能减少部分冗余激活,但仍可能关注到类似病灶的正常组织;PASS-Tr 的 CAM 更集中于病灶区域,预测框更接近真实标注并减少误检。图中还显示加入相邻切片后检测质量普遍提升,进一步支持多切片上下文的有效性。
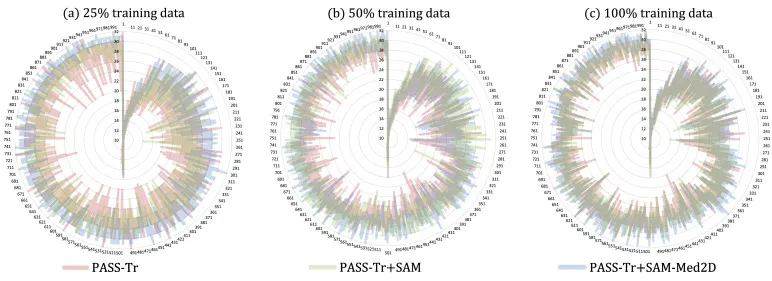
图5:该图用雷达图展示不同训练数据比例下,PASS-Tr、PASS-Tr+SAM 和 PASS-Tr+SAM-Med2D 在训练迭代过程中的正 ROI BBox 数量。整体趋势表明,加入 LVM 特征后模型在训练早期产生更多正样本候选,收敛更快且更稳定。SAM-Med2D 的加速效果通常强于 SAM,尤其在 25% 和 50% 训练数据等数据较少的场景中更明显。这说明医学域预训练特征对提升训练效率和低数据泛化有价值。
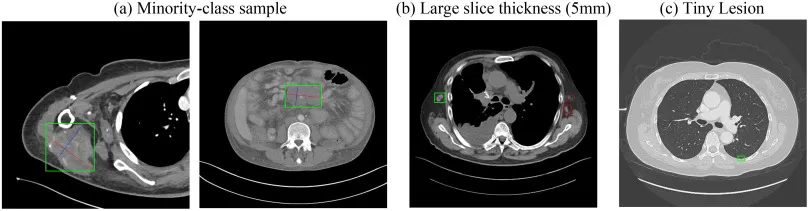
图6:该图展示 PASS-Tr 的四类典型失败情况,主要包括少数类别样本、大层厚 CT 和微小病灶。绿色框为真实标注,红色框为预测结果,可以看到模型在不常见病灶、层间间距较大导致上下文不连续、以及目标极小难以定位时仍会漏检或误检。该图揭示了方法的边界条件,也为未来引入不确定性建模、类别重采样或更细粒度小目标注意力提供依据。