2026.6.5
本文发布并分析IUGC产时超声视频挑战,比较多任务深度学习方法并指出视频ViT、预训练模型、数据增强和域泛化是未来关键。
Title题目
01
Beyond benchmarks of IUGC: Rethinking requirements of deep learning method for intrapartum ultrasound biometry from fetal ultrasound videos
超越IUGC基准:重新思考从胎儿产时超声视频进行深度学习自动生物测量的需求
文献速递介绍
02
论文首先指出,约45%的孕产妇死亡、新生儿死亡和死产发生在产时阶段,尤其集中于中低收入国家。产时超声因成本较低、无创、可用于评估胎头下降和分娩进展而具有重要临床价值,但在资源受限地区,熟练超声医师不足限制了其常规使用。临床上需要从产时经会阴超声视频中识别标准切面,分割胎头FH和耻骨联合PS,并测量进展角AoP和头耻距离HSD。作者强调,这一流程存在图像伪影、散斑噪声、声影、胎儿运动、组织形变、边界模糊、标准与非标准切面差异小等困难,而且分类、分割和测量之间存在误差传播。基于这些需求,IUGC被提出,用多中心视频数据推动面向临床工作流的自动化多任务算法研究。
相关工作部分回顾了妇产超声图像分析中的公开挑战和基准。以往挑战多集中于产前超声,如胎头、股骨、腹围、宫颈、羊水和胎盘等任务,而产时超声相关挑战较少,且多数集中在单张图像的分割或测量。与PSFHS等图像级挑战相比,IUGC的特点是同时覆盖胎儿结构和母体解剖结构,同时包含标准切面分类、FH和PS分割以及AoP和HSD测量,并且提供大规模多中心视频数据。作者还总结了已有产时超声生物测量算法的发展,从早期阈值、形态学和跟踪方法,到UNet、多任务网络、SAM、半监督学习和知识蒸馏等深度学习方法。总体来看,既有研究多为单中心、单图像或半自动流程,距离真实临床中的视频级全自动多任务应用仍有明显差距。
材料与实验设置
IUGC由产时超声图像分析合作组及多个临床学会共同推动,并与MICCAI 2024联合举办。挑战要求参赛者提交Docker封装的全自动算法,在隐藏测试集上完成标准切面分类、FH和PS分割、AoP与HSD测量。数据集包含774名孕妇的774段经会阴超声视频,共68,106张图像,来自暨南大学附属第一医院JNU、中山大学附属第三医院SYSU和南方医科大学珠江医院SMU三家机构。训练集和验证集来自JNU,测试集包含JNU、SYSU和SMU数据,因此能检验跨中心、跨设备鲁棒性。图像统一裁剪为512×512像素,视频采集设备包括ObEye、Voluson P8和Esaote MyLab。标注由有经验的超声医师和产科医师完成,包括标准切面判断、PS和FH手工分割,以及根据临床定义测量AoP和HSD。评价指标方面,分类使用ACC、F1、MCC和AUC,分割使用DSC、ASSD和95% Hausdorff Distance,生物测量使用自动值与人工值的绝对差ΔAoP和ΔHSD。排名采用指标级、任务级和综合级三层体系,并用ChallengeR工具进行显著性检验、bootstrap排名稳定性和多种排名方法鲁棒性分析。
Aastract摘要
03
本文围绕产时超声自动生物测量问题,系统介绍MICCAI 2024 Intrapartum Ultrasound Grand Challenge,即IUGC。该挑战构建了目前最大的公开多中心产时经会阴超声视频数据集,包含774段视频和68,106张图像,并设计标准切面分类、胎头与耻骨联合分割、AoP与HSD生物测量三个关联任务。论文评估了官方基线和七支优胜团队的方法,从预处理、数据增强、学习策略、网络结构和后处理等方面进行综述,并用分类、分割和测量指标进行多层级排名。结果显示,T1的Video Swin Transformer端到端视频多任务框架综合排名第一,T2在分割任务上最佳,T3在生物测量任务上表现突出;但标准切面识别仍低于人工水平,跨设备域偏移、标注不确定性、误差级联和模型部署复杂度仍是临床转化的核心障碍。
Method方法
04
论文详细比较了官方基线T0和七支优胜团队T1至T7的方法。T0使用UNet分割分支和基于下采样特征的分类分支,先训练分割再冻结编码器训练分类,并通过分割轮廓计算AoP和HSD。T1,即Ganjie团队,采用Video Swin Transformer和小波Transformer,构建视频端到端多任务空间时间网络,同时处理分类、分割和测量,是唯一显式利用视频片段时序信息的综合优胜方法。T2使用ResNet进行分类、DeepLabV3进行分割,并结合AutoAugmentation、外部PSFHS数据和测试时增强,在分割任务中表现最佳。T3在基线基础上引入nnUNet伪标签和弱监督,用大量未标注阳性帧扩展训练数据,并通过动态损失缩放平衡分类与分割,在生物测量任务中领先。T4提出DSSAU-Net,通过双稀疏选择注意力提升FH和PS分割效率。T5使用多模型集成、稀疏采样和复杂后处理,包括最大连通域、椭圆拟合和边缘检测,以增强泛化性。T6提出MFA-UNeXt,用频域注意力增强超声图像特征。T7采用ResNet-50分类和MobileNetV2-LinkNet分割,强调轻量化和结构化后处理。作者进一步从预处理、网络结构与损失函数、数据增强、学习过程和后处理五个方面归纳参赛方案,指出深度学习架构选择、适度增强、预训练权重、半监督伪标签、测试时增强和合理的后处理都会影响最终性能。
Discussion讨论
04
讨论部分首先分析了标注一致性。150个测试样本的多专家标注比较显示,分类和PS分割一致性较高,而FH分割和AoP、HSD测量只达到中等一致性,反映出产时超声中胎头边界、遮挡、运动和探头压迫造成的内在不确定性。随后作者分析跨数据源鲁棒性,发现T1相对T0在JNU、SYSU和SMU上总体更强,但所有方法在SMU,即Esaote MyLab设备来源的数据上均明显退化,说明设备差异、采集协议、操作者习惯和患者群体会造成显著域偏移。训练策略方面,作者比较先分割后分类与先分类后分割,认为先学习解剖结构分割特征再用于标准切面识别更合理;同时,T1和T3的一阶段多任务训练也显示出潜力。数据增强实验表明,Elastic、Affine、Dropout、Unsharp Mask和CLAHE等增强能不同程度改善分割性能。架构分析进一步纳入17种深度模型,发现TransUnet、MambaUnet、Fatnet和SAM等在分割上很强,其中SAM在分割和测量综合表现中可作为重要基准,但模型较大。后处理实验显示,椭圆拟合并非总是有益;对于HSD,直接使用原始轮廓往往优于椭圆拟合,因为错误分割或离群轮廓会被全局几何拟合放大。临床影响方面,AoP和HSD具有强线性关系,联合使用有助于提高胎头位置评估可靠性,但仍需大规模临床验证。局限性包括标准切面分类准确率尚低于人工水平,未标注数据利用不足,视频时序信息挖掘不充分,强模型难以边缘实时部署,多中心数据仍不够平衡,以及级联流程存在误差传播。
Conclusion结论
05
论文总结认为,IUGC是产时超声自动分析领域的重要基准,首次以大规模多中心视频数据将标准切面分类、FH-PS分割和AoP、HSD测量统一在一个面向临床的多任务框架中。挑战结果表明,视频导向的ViT架构、预训练模型、任务特异性数据增强和合理后处理能够显著提升性能,T1的Video Swin Transformer端到端方法综合表现最佳。然而,标准切面识别仍是最大瓶颈之一,分类准确率低于专家人工标注;未标注数据和视频时序结构尚未充分利用;多中心域偏移和误差级联仍限制临床部署。未来研究应重点发展更鲁棒的标准切面检测、半监督或自监督学习、轻量化端到端视频模型、跨设备域泛化以及直接关键点检测或直接回归式测量框架,从而减少人工依赖并推进产时超声AI的临床转化。
Results结果
06
总体结果显示,在八个挑战方法中,T1、T2和T3分别在分类、分割和测量方面表现最突出。分类任务中,T1取得ACC 0.7441、F1 0.7555、AUC 0.7802和MCC 0.3648,显著优于其他方法,并在多种排名方案中保持第一。分割任务中,T2取得DSC 0.8857、ASSD 9.4349和HD 28.4152,是挑战参赛方法中最佳分割方案。生物测量任务中,T3取得最小ΔAoP 9.1557,而T2取得最小ΔHSD 10.3878;综合稳定性分析显示T3和T2在不同排名策略下均有较强竞争力。综合排名中,T1、T2和T3位列前三,其中T1综合排名最稳定,反映了端到端视频多任务学习在该任务中的优势。论文还指出部分方法,尤其T6和T7,在分割和测量上性能明显落后,说明网络设计、训练策略和后处理对该任务影响很大。
Figure图
07
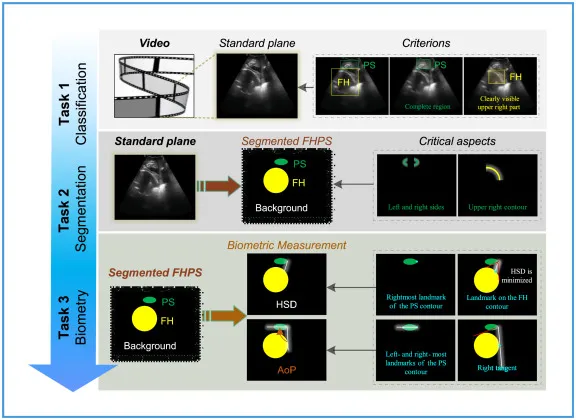
图1.该图概括了IUGC中标准切面分类、FH和PS分割、AoP与HSD生物测量三项任务的技术难点。分类受到同类内差异大和类间差异小的影响;分割受到产时解剖形变、PS尺寸小、超声噪声、声影和边界模糊影响;测量则依赖精确几何关系,多个可能的轮廓点和碎片化分割会导致关键点选择不确定。它奠定了整篇论文的问题定义。
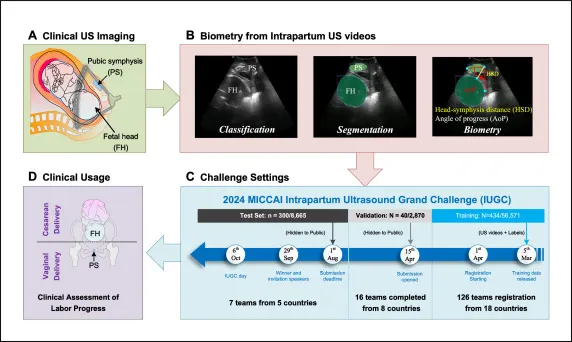
图2.该图展示从经会阴超声采集,到人工完成标准切面判别、FH和PS分割、AoP和HSD测量,再到IUGC中训练、验证和测试集划分以及算法排名的整体流程。图中说明数据集包含774段视频和68,106张图像,挑战目标是以自动化方法替代繁琐且依赖专家的临床测量流程。
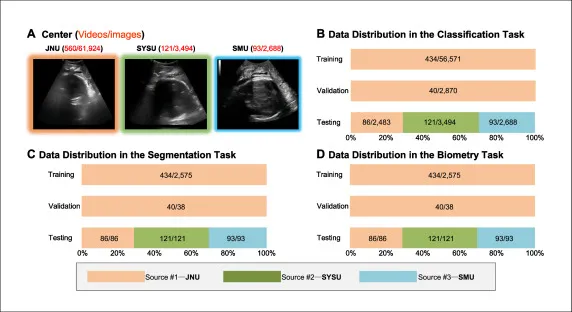
图3.该图展示JNU、SYSU和SMU三家医院的数据规模、代表性图像以及分类、分割和测量任务中的训练、验证、测试分布。它突出训练与验证主要来自JNU,而测试包含三个中心和不同设备,因此该基准能够检验算法在跨中心、跨设备条件下的泛化能力。
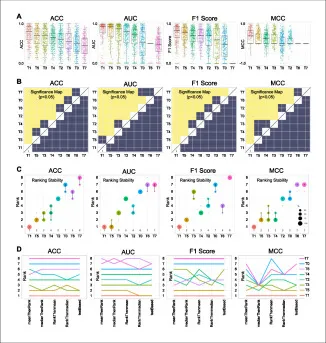
图4. 该图用箱线图、显著性图、bootstrap排名稳定性和多种排名方法比较八个团队在ACC、AUC、F1和MCC上的表现。结果显示T1在分类任务中最强且排名稳定,说明Video Swin Transformer对视频时序和全局上下文的建模有利于区分标准与非标准切面。
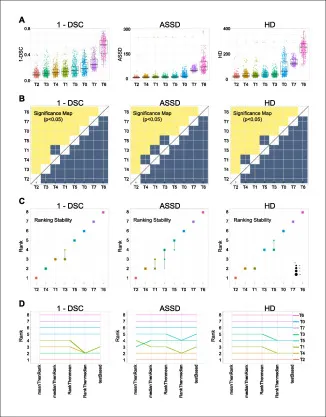
图5该图比较八个团队在DSC、ASSD和HD上的分割性能。T2在挑战参赛方法中取得最高DSC和最低边界误差,说明ResNet分类、DeepLabV3分割、外部数据和测试时增强的组合能有效提升FH与PS轮廓提取质量。
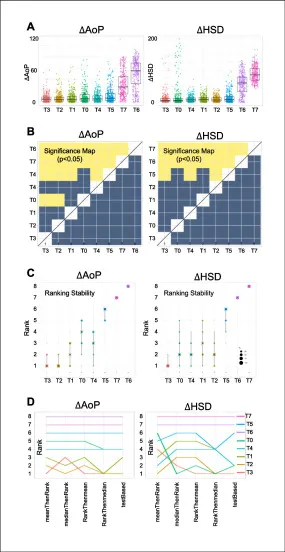
图6该图比较各方法在ΔAoP和ΔHSD上的误差分布、显著性和排名稳定性。T3在ΔAoP上最佳,T2在ΔHSD上最佳,且T1、T2、T3、T4之间在部分测量指标上差异接近,说明下游测量不仅取决于分割精度,还受到关键点提取、后处理和标注不确定性的共同影响。
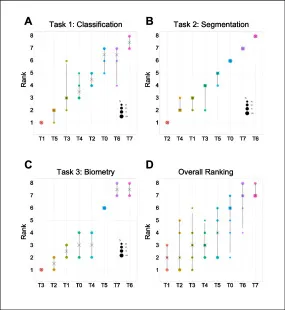
图7该图总结分类、分割、测量和总体挑战排名。T1分类第一并综合第一,T2分割第一,T3测量第一;综合排名中T1最稳定,说明端到端视频多任务方法在整体临床工作流上更具优势,而单一任务最优并不必然带来综合最优。
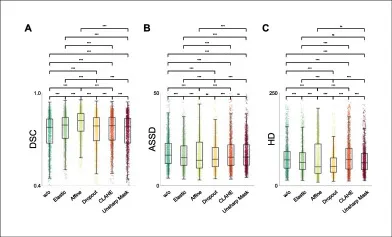
图8该图分析Elastic、Affine、Dropout、Unsharp Mask和CLAHE等增强策略对DSC、ASSD和HD的影响。结果表明几何变换与强度增强能在不同程度上提升分割鲁棒性,说明在超声图像标注有限、噪声和形变明显的场景中,任务合适的数据增强是提升泛化能力的关键。
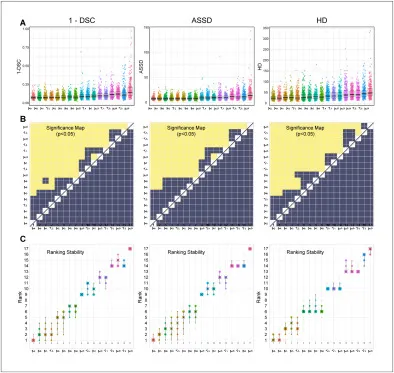
图9该图将挑战前五方法与多种额外架构进行分割性能比较。结果显示TransUnet在DSC和ASSD上表现突出,SAM在HD上表现优秀,MambaUnet、Fatnet等也具有较强竞争力。这说明更强的长程依赖建模、预训练和基础模型能力可能优于传统UNet式架构。
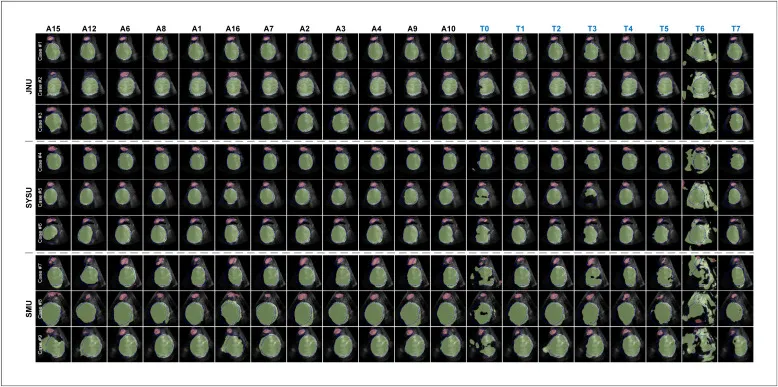
图10该图展示20种方法在JNU、SYSU和SMU样本上的分割结果,红色为PS预测、绿色为FH预测、蓝色为真值。JNU样本多数方法表现较好,SYSU和尤其SMU样本中出现更多边界泄漏、PS漏分割和FH轮廓碎片化,直观证明跨设备和跨中心域偏移是当前方法的重要瓶颈。
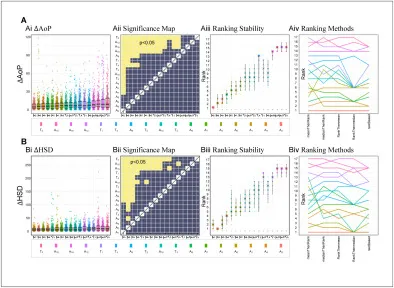
图11该图比较17种方法在ΔAoP和ΔHSD上的表现。SAM相关方案在AoP和综合测量稳定性上非常突出,MambaUnet在HSD上表现优秀,说明基础分割模型和全局上下文建模能改善下游临床参数估计,但仍需考虑模型复杂度和部署成本。
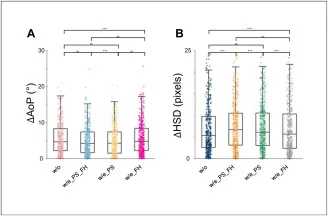
图12该图比较不进行椭圆拟合、对PS和FH都拟合、仅拟合PS、仅拟合FH四种后处理策略对ΔAoP和ΔHSD的影响。结果表明椭圆拟合对AoP平均有轻微帮助但收益有限,而对HSD可能显著变差,提示在动态噪声超声图像中,强行施加全局几何形状可能放大分割错误。
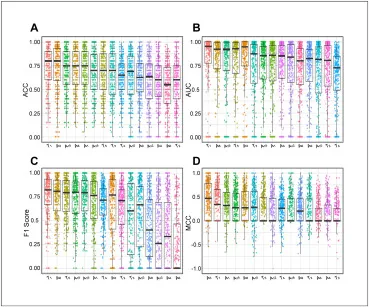
图13该图展示不同数据来源中AoP和HSD之间的关系,说明两者作为胎头下降程度的指标存在明显线性相关。该结果支持在临床自动评估中联合使用AoP和HSD,以提高产程进展判断的可靠性。
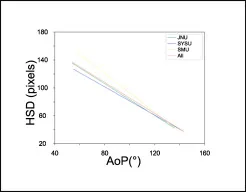
图14该图扩展比较17种深度学习方法在ACC、AUC、F1和MCC上的分类表现。没有方法达到80%以上的标准切面识别准确率,低于人工标注一致性水平,凸显标准切面自动识别仍是IUGC流程中最重要的瓶颈。