2026.3.25
本研究提出CKRA模型,通过动态过滤上下文相关医学知识、引入知识-图像对比学习和设计双流引导注意力机制,有效解决了医学视觉问答中的知识冗余和跨模态语义偏差问题,并在SLAKE和VQA-RAD数据集上取得了最先进的性能。
Title题目
01
Beyond Static Knowledge: Dynamic Context-Aware Cross-Modal Contrastive Learning for Medical Visual Question Answering
越静态知识:医学视觉问答中动态上下文感知跨模态对比学习
文献速递介绍
02
医学视觉问答(Med-VQA)是结合计算机视觉和自然语言处理的人工智能任务,旨在通过分析医学图像和文本查询生成准确答案,以提高诊断效率并减少误诊。然而,Med-VQA面临两大挑战:一是问题往往缺乏足够的上下文细节而图像包含丰富的临床信息,导致语义不对称,阻碍了有效的图像-文本对齐和推理;二是现有方法集成外部医学知识时,常不加区分地引入,忽略了知识的任务特异性相关性,导致冗余和噪声。为解决这些问题,本文提出了上下文知识感知动态感知跨模态推理与对齐模型(CKRA),其灵感来源于临床诊断过程,通过动态知识感知、知识-图像对比学习和双流引导注意力机制实现多模态协作推理,旨在解决知识冗余和跨模态语义不匹配问题。
Aastract摘要
02
医学视觉问答(Med-VQA)旨在分析医学图像并准确回答自然语言查询,从而优化临床工作流程并改善诊断和治疗结果。尽管医学图像包含丰富的视觉信息,但相应的文本查询通常缺乏足够的描述内容。这种信息不平衡和模态差异导致了显著的语义偏差。此外,现有方法虽然整合外部医学知识以增强模型性能,但它们主要依赖静态知识,缺乏对特定输入样本的动态适应性,导致信息冗余和噪声干扰。为解决这些挑战,我们提出了一个上下文知识感知动态感知跨模态推理与对齐(CKRA)模型。为减轻知识冗余,CKRA采用动态感知机制,利用查询中的语义线索选择性地过滤与当前样本上下文相关的医学知识。为缓解跨模态语义偏差,CKRA通过知识-图像对比学习缩小视觉和语言特征之间的距离,优化知识特征表示并引导模型关注关键图像区域。此外,我们设计了一个双流引导注意力网络,促进跨模态多维度交互和对齐。实验结果表明,CKRA模型在SLAKE和VQA-RAD数据集上优于现有最先进方法。此外,消融研究验证了每个模块的有效性,而Grad-CAM图谱进一步证明了CKRA在医学视觉问答任务中的可行性。模型源代码和权重可在https://github.com/cloneiq/CKRA-MedVQA获取。
Method方法
03
CKRA模型包含三个核心模块:(1)上下文知识的动态感知:该模块将医学知识图谱(MKG)中的实体投射到多个语义子空间,并通过问题引导的注意力机制自适应地过滤出与当前任务相关的上下文知识,同时抑制噪声。引入可微主成分分析(PCA)模块进行降维和融合,确保端到端训练和梯度传播。(2)知识-图像对比学习:采用预训练的ResNet-152提取图像特征,并通过三元组损失实现知识与图像特征的对比学习。该机制旨在最小化正样本对距离,最大化负样本对距离,从而增强跨模态对齐并保持语义一致性。它还通过掩码矩阵处理同一图像对应多个问题的情况,以优化对比损失。(3)双流引导注意力:该网络通过问答引导的图像-知识交互和图像引导的问答-知识交互,将上下文知识作为语义锚点融入双向密集跨模态注意力,促进异构模态间的理解和推理。模块堆叠多层以实现深度交互和对齐,确保信息在模态间流动的完整性。最后,将整合后的问题、知识和图像特征输入分类器进行多类分类,并结合交叉熵损失、对比损失和相关性损失构成总损失函数进行优化。
Discussion讨论
04
本文提出的CKRA模型通过动态过滤相关上下文知识,有效缓解了知识冗余问题,并利用知识辅助跨模态推理和对齐,显著减轻了跨模态语义偏差。消融研究揭示了各模块间的强大互补性,例如,未经过滤的全部知识反而会分散注意力,影响对齐效果。对比学习不仅对齐知识与视觉,还能跨语义空间传播监督信号,与动态感知模块协同工作以提升输入质量。Grad-CAM可视化结果进一步支持了这些发现,CKRA在病灶定位和知识特征可分离性上表现优异。双流注意力机制也被证实是性能提升的关键,单模态引导无法充分利用上下文感知和对比对齐的优势。然而,CKRA也存在局限性,例如在SLAKE数据集的封闭式问题上,移除对比学习(CKRA(NC))反而表现更好,这表明模型性能受任务特异性影响。开放式任务可能更受益于知识引导推理,而封闭式任务则更依赖局部视觉对齐,可能受对比学习约束的负面影响。未来的工作应侧重于开发自适应平衡策略,根据任务特点动态调整视觉对齐和知识引导推理的贡献,以增强模型在不同临床场景下的鲁棒性和泛化能力。
Conclusion结论
05
本文提出了CKRA模型,一个上下文知识感知动态感知模型,用于医学诊断中的跨模态推理与对齐。与以往依赖整个知识库的方法不同,CKRA动态识别并整合多个语义空间中与上下文相关的知识,从而减轻不相关干扰并利用问题、图像和领域知识之间的内在关联。通过促进其核心模块之间的协同交互,模型有效缩小了医学图像和临床查询之间的语义鸿沟。在两个基准数据集上的综合实验不仅证实了每个模块的单独功效,也验证了它们的互补作用,CKRA在多个评估指标上持续超越现有最先进的基线方法。尽管取得了这些有前景的成果,但仍观察到任务特异性差异,这强调了开发自适应策略以确保在不同临床场景中更灵活和鲁棒地利用外部知识的必要性。
Results结果
06
本节在SLAKE和VQA-RAD数据集上评估了CKRA模型的性能,并通过消融实验验证了各模块的有效性和协同作用。实验采用准确率、加权F1-score和BLEU-1作为评估指标。通过详细的消融研究,结果显示,CKRA的每个核心模块(动态上下文知识感知、知识-图像对比学习、双流引导注意力)都对模型性能有显著贡献。特别是,未经动态过滤的知识(CKRA(NK))和缺少对比学习(CKRA(NC))均导致性能下降,证实了动态过滤和跨模态对齐的重要性。可微PCA模块(CKRA(NP))在知识表示和梯度传播中也发挥关键作用。统计显著性分析表明,CKRA相对于其所有消融变体均有显著性提升。在动态知识过滤策略的对比中,CKRA始终优于其他先进的过滤方法。参数敏感性研究确定了知识范围、对比学习约束和注意力层数的最佳配置。与现有最先进的Med-VQA模型相比,CKRA在SLAKE和VQA-RAD数据集上均取得了最佳的整体性能,展现出在分类和生成式任务上的均衡和鲁棒性。定性分析通过Grad-CAM激活图谱展示了CKRA在视觉注意力定位和上下文知识对齐方面的优势,并揭示了模型在面对不相关文本干扰时的鲁棒性。效率评估显示,CKRA在训练时间和参数数量上与LaPA相似,推理延迟增加可忽略不计,且由于动态知识过滤降低了内存消耗。
Figure图
07
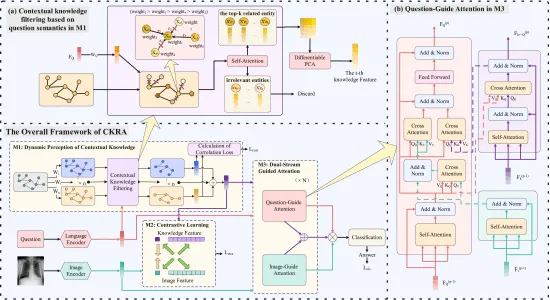
图1. 所提出的CKRA模型的整体框架和核心模块的详细设计。展示了CKRA的整体框架,其中绿色、红色和紫色通道分别代表图像、问题和知识模态。三个黄色框对应于主要方法模块:M1:上下文知识动态感知模块,M2:知识-图像对比学习模块,M3:双流引导注意力模块。(a) 此子图显示了如何在第t个语义空间中根据问题的语义含义过滤和整合上下文知识,颜色越深表示知识节点的权重越高。(b) 此子图显示了第p层基于问题的注意力网络。基于图像的注意力网络具有相同结构,它们共同形成一个双流引导注意力网络。在M3的问题引导注意力中,Q、K和V分别代表查询、键和值,下标表示它们分别来自问题、上下文知识和图像特征。
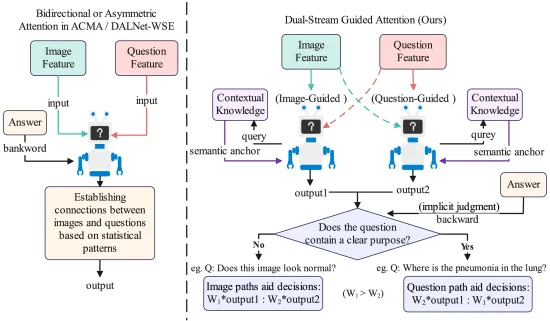
图2. 多模态交互推理机制的说明性比较。左侧描绘了传统方法,主要依赖统计相关性而缺乏外部基础。右侧显示了我们提出的机制,它将上下文知识作为语义锚点进行动态引导,从而减轻语义漂移并增强对齐的鲁棒性。
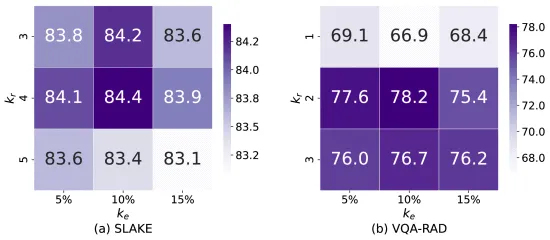
图3. SLAKE和VQA-RAD数据集中知识范围的选择。
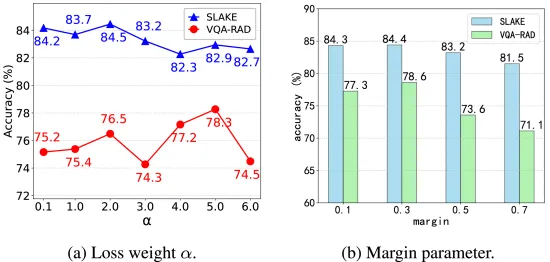
图4. 对比学习约束对模型性能的影响。
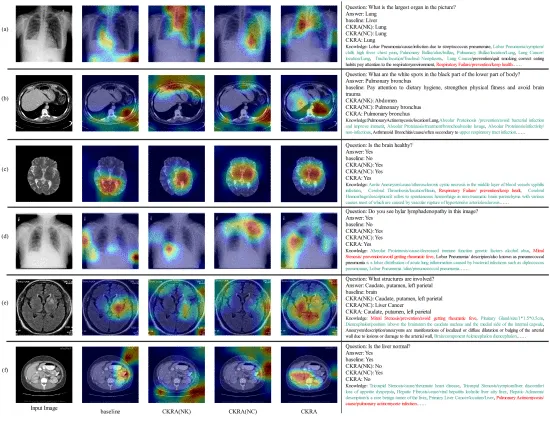
图5. CKRA模型中Grad-CAM激活图和上下文知识的可视化分析。从左到右依次显示原始图像、基线模型、CKRA(NK)、CKRA(NC)和完整CKRA模型的Grad-CAM图。最右侧显示了示例问题、正确答案、基线预测、CKRA及其两种变体的预测以及CKRA过滤出的上下文相关知识。由于知识量大,仅显示了代表性子集。知识以三元组形式呈现,实体和关系用“/”符号分隔。与样本高度相关的知识以绿色突出显示,边缘知识以红色突出显示。

图6. 语义投影和对比学习效果的可视化。(a) 不同语义空间中知识投影的可视化。不同颜色表示来自不同案例的知识特征,而圆形和三角形分别表示在两个独立语义空间中投影的特征。(b) 对比学习效果的可视化。左侧显示了带有对比学习的CKRA模型,右侧显示了没有对比学习的CKRA(NC)模型。正向知识-图像对由红色实线连接,负向对由绿色虚线连接。
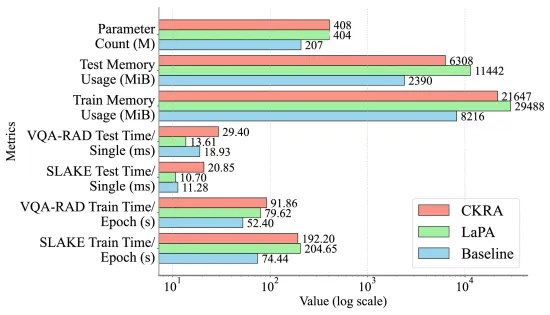
图7. CKRA、基线和LaPA在时间效率和资源消耗方面的比较。该图报告了SLAKE和VQA-RAD数据集上每轮训练的平均时间(秒)和每个测试样本的平均推理时间(毫秒),以及训练和推理期间的模型参数数量(百万)和GPU内存使用量(MiB)。