2026.3.10
本文提出MIRAGE框架,通过引入基于最优传输的对比损失和自适应梯度平衡策略,有效解决了医学图像-文本预训练中因数据噪声(假阳性与假阴性)导致的模型性能受限问题,在多项下游任务上取得了最先进的性能,并展现出强大的鲁棒性和泛化能力。
Title题目
01
MIRAGE: Medical image-text pre-training for robustness against noisy environments
MIRAGE:面向嘈杂环境下鲁棒性的医学图像-文本预训练
文献速递介绍
02
由于医疗数据收集和标注成本高昂且隐私法规严格,现有医学图像-文本数据集通常规模较小且存在噪声。特别是在自动提取的PMC-OA等数据集中,常出现图像与描述不匹配的假阳性(FP)和语义相关但被视为无关的假阴性(FN)问题。传统的InfoNCE损失在噪声环境下表现出过度自信,无法有效处理这些问题。现有噪声处理方法(如数据清洗)在医疗领域也因缺乏专家标注或领域差异而失效。本文提出MIRAGE框架,通过新颖的最优传输(OT)对比损失、跨模态最近邻(NN)噪声估计和自适应梯度平衡策略,首次同时解决了医学视觉-语言预训练中的FP和FN问题,旨在提升模型在嘈杂环境下的鲁棒性。
Aastract摘要
02
对比视觉-语言预训练模型在大规模通用多模态数据集上取得了显著成功,但在医疗领域,由于数据收集和专家标注的高成本,导致数据集规模小且噪声大,这严重限制了模型性能。为解决这一挑战,本文提出了MIRAGE框架,旨在处理医学图像-文本预训练中不匹配的假阳性(FPs)和语义相关的假阴性(FNs)。传统的基于交叉熵的优化方法在噪声对比设置中不足以区分噪声样本,从而导致次优表示。为此,我们引入了一种基于最优传输的对比损失,利用最近跨模态邻居先验有效地识别噪声样本,从而减少其不利影响。此外,我们提出了一种自适应梯度平衡策略来减轻噪声样本梯度带来的影响。大量实验表明,MIRAGE在六项任务和14个数据集上实现了卓越性能,显著优于现有最先进方法。对合成噪声数据进行的全面分析也清晰地展示了MIRAGE各组件的贡献。
Method方法
03
MIRAGE框架旨在通过最优传输对比损失和自适应梯度平衡策略解决医疗数据中的噪声问题。首先,为了缓解InfoNCE损失在噪声数据上的过度自信问题,我们引入了基于最优传输(OT)的对比损失,它通过计算预测概率分布与真实分布之间的瓦瑟斯坦距离,实现对噪声样本的鲁棒优化。我们提出的代价函数Cij量化了将一对图像-文本视为正样本所需的传输成本,从而有效捕捉FP和FN案例中的噪声。其次,我们提出了基于最近邻(NN)的噪声估计方法,该方法通过在记忆库中查询图像的最近邻文本(而非其原始配对文本)来评估图像-文本对的语义一致性。这种方法能够更可靠地区分干净和噪声样本,即使在L2距离收敛的情况下也能保持有效。最后,为了在噪声环境中实现稳定优化并减轻噪声数据的影响,我们引入了自适应梯度平衡策略。该策略根据样本的估计匹配分数动态调整InfoNCE损失中每个正样本的贡献,同时引入一个基于NN的鲁棒对比损失,并在两者之间进行凸插值,以避免启发式切换并稳定训练过程。
Discussion讨论
04
尽管MIRAGE在通用医学任务中表现出色,但在专门针对3D成像的单模态模型中仍存在性能差距,这主要源于2D预训练设置的架构和数据限制。目前MIRAGE缺乏明确的3D图像-文本语义理解,未来计划开发模态特异性适配和构建大规模3D图像-文本数据集。此外,由于现有数据集缺乏患者层面的人口统计或站点元数据,模型在公平性和偏见缓解方面的系统性子组分析仍面临挑战,未来将探索公平感知预训练策略。在多模态大语言模型(MLLMs)中,幻觉问题阻碍了临床部署。尽管本文初步探索了将MIRAGE作为RAG检索器,但由于预训练数据并非专为RAG设计,性能仍有提升空间。鉴于MIRAGE在检索任务上的卓越表现和对语义噪声的鲁棒性,其有望提升RAG系统在医学应用中的可靠性和事实准确性。最后,本研究仍停留在算法层面,距离实际临床部署尚有差距。未来工作将加强MIRAGE与临床任务的联系,探索其在基于智能体的工作流程、人机交互、多组学研究以及数据驱动AI模型的透明度和隐私保护方面的应用。
Conclusion结论
05
本文提出了一种无需数据过滤、鲁棒的医学领域对比视觉-语言预训练(VLP)框架MIRAGE。该框架引入了一种新颖的最优传输对比损失,以缓解InfoNCE损失的过度自信问题,并结合了跨模态最近邻噪声估计方法。此外,我们提出了一种自适应梯度平衡策略,以确保训练的稳定性。在真实世界和合成噪声数据上的广泛实验结果均证明了所提出的MIRAGE框架的有效性和鲁棒性。
Results结果
06
MIRAGE框架在广泛的实验中展示了卓越的性能和鲁棒性。预训练在PMC-OA数据集上,模型在零样本分类、KNN分类、图像-文本检索、视觉问答(VQA)和多模态检索增强生成(MM-RAG)六项下游任务和14个数据集上均超越了CLIP、PMC-CLIP、CoCa等现有最先进方法。消融研究证实,最优传输对比损失和自适应梯度平衡策略对性能提升至关重要。鲁棒性评估表明,MIRAGE在不同噪声水平下始终优于CLIP,且在训练过程中收敛更平稳,不易过拟合噪声数据。在代价函数评估中,基于最近邻文本的代价函数(NN-T)表现最佳。此外,自适应梯度平衡策略有效稳定了噪声样本的距离,防止模型过拟合。在最近邻搜索策略方面,软NN搜索通常优于硬NN搜索。记忆库大小的最佳选择为65536。计算效率方面,MIRAGE仅略微增加了GPU内存和训练时间,推理成本与基线CLIP相同。跨数据集分析显示,MIRAGE在更干净的PubMedVision数据集上表现更优,并能更好地保持长尾类别分布,降低赫林格距离,减轻偏见。MIRAGE还展现了对多种视觉编码器(如ViT、Swin Transformer、ConvNeXt等)的普遍适用性,并在对3D医学成像的探索性评估中超越了CoCa。可视化结果进一步验证了MIRAGE能有效识别FP和FN案例,并在训练过程中从低级到高级语义进行最近邻匹配,实现更精细的图像-文本相似度理解。
Figure图
07
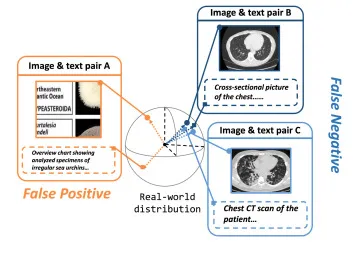
图1. PMC-OA数据集中代表性的假阳性(FP)和假阴性(FN)案例。
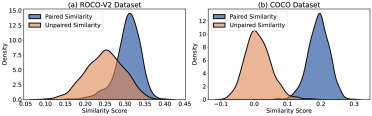
图2. 使用DFN模型(Fang et al., 2024)对(a) ROCO-V2(医学数据集)和(b) COCO(自然数据集)中配对和未配对图像-标题对的相似度分数分布。
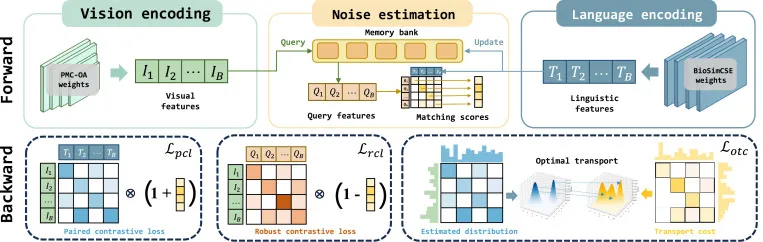
图3. 提出的MIRAGE整体框架。在前向传播过程中,记忆库为每张图像检索最近的文本嵌入,以估计整个批次中的噪声水平。在反向传播过程中,估计的噪声通过自适应梯度平衡策略整合到最优传输对比损失中。
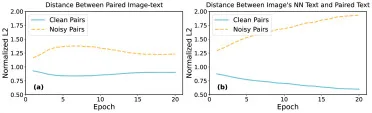
图4. 在30%图像-文本混洗训练时的归一化L2距离可视化:(a) 每张图像与其配对文本之间的距离;(b) 每张图像的最近邻(NN)文本与其配对文本之间的距离。
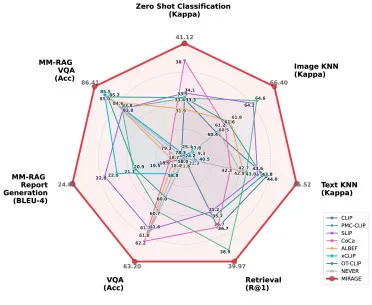
图5. MIRAGE与最先进方法在各种任务上的性能比较分析。
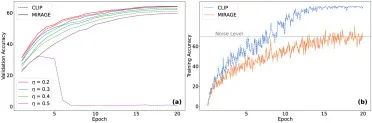
图6. MIRAGE和CLIP在噪声环境中的行为:(a) 不同噪声水平下的验证对比准确率;(b) 噪声水平η=0.3时的训练准确率收敛模式。
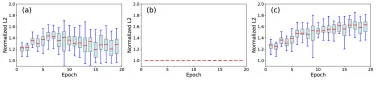
图7. 随机采样噪声图像-文本嵌入之间的归一化L2距离比较:(a) 大的InfoNCE权重(1.0),(b) 小的InfoNCE权重(0.01),以及© 自适应梯度平衡。

图8. 图像-配对文本相似度与图像-最近邻文本相似度在不同数据集上的散点图。噪声水平越高,两种相似度之间的相关性越低。

图9. 通过检索任务评估的MIMIC数据集中采样的类别分布图。从左到右依次为:MIRAGE检索到的报告标签;CLIP检索到的报告标签;以及真实报告标签。

图10. 基于在不同训练周期中匹配分数最高的前1%代表性样本,最近邻匹配在训练过程中的演变。红色高亮显示的单词表示不匹配,绿色高亮显示的单词表示一致匹配。
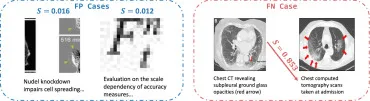
图11. MIRAGE检测到的代表性假阳性(FP)和假阴性(FN)案例可视化,其中S表示匹配分数。
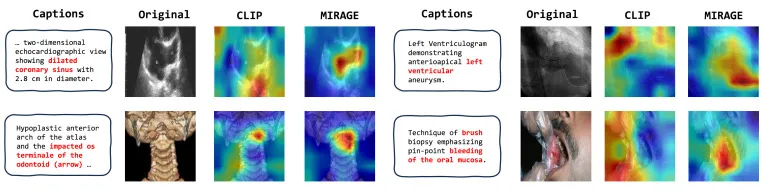
图12. CLIP和MIRAGE局部图像-文本相似度的比较可视化。标题中的关键词以红色高亮显示。