2026.2.27
本研究提出一种基于条件去噪扩散概率模型生成合成2D MRI投影的中间策略,通过预训练2D模型并结合ACS卷积扩展至3D,在小规模真实数据上显著提升阿尔茨海默病诊断准确性,有效弥补了医疗影像领域数据稀缺和现有迁移学习方法的不足。
Title题目
01
Generating synthetic MRI scans for improving Alzheimer’s disease diagnosis
生成合成MRI扫描以改进阿尔茨海默病诊断
文献速递介绍
02
阿尔茨海默病(AD)是全球影响数百万人的进行性神经退行性疾病,MRI结合机器学习(ML)已被证明是其诊断的有力工具。然而,由于医学数据集通常小规模且异质,导致ML模型在实际临床应用中表现受限。为了应对这一挑战,目前主要有两种方法:一是开发需要大量数据的通用化模型,但在医疗领域数据获取困难且计算成本高昂;二是采用迁移学习(TL),通过在相关任务上预训练模型并在特定医院数据上微调。虽然在2D自然图像上预训练的模型结合轴位、冠状位和矢状位(ACS)卷积能改善性能,但与直接在3D MRI数据上预训练相比仍有差距。本研究旨在通过引入一种基于合成医学图像生成的中间策略来弥补这一差距,即提出一种条件去噪扩散概率模型(DDPM)生成2D MRI投影,用于预训练2D模型,再通过ACS卷积扩展至3D,并在小规模真实数据集上进行AD诊断微调。主要贡献包括:基于条件扩散的生成、面向诊断的合成数据集、低资源环境下的AD诊断微调以及详细的消融研究。
Aastract摘要
02
阿尔茨海默病(AD)是一种进行性神经退行性疾病,也是痴呆症的主要原因。磁共振成像(MRI)结合机器学习(ML)能够实现早期诊断,但ML模型在小规模、异质性医疗数据集上训练时往往表现不佳。迁移学习(TL)有助于缓解这一局限性,然而在2D自然图像上预训练的模型仍然不如直接在相关3D MRI数据上训练的模型。为了弥补这一差距,我们引入了一种基于合成数据生成的中间策略。具体而言,我们提出了一种条件去噪扩散概率模型(DDPM),用于合成三种临床组(认知正常(CN)、轻度认知障碍(MCI)和AD)的脑部MRI扫描的2D投影(轴位、冠状位、矢状位)。总共9000张合成图像被用于2D模型的预训练,这些模型随后通过轴位、冠状位和矢状位卷积扩展到3D,并在真实小数据集上进行微调。我们的方法在3T ADNI数据集上的二分类(CN vs. AD)任务中实现了91.3%的准确率,在三分类(CN/MCI/AD)任务中实现了74.5%的准确率,优于从零开始训练的模型以及在ImageNet上预训练的模型。我们的2D ADnet模型在OASIS-2数据集上达到了最先进的性能(59.3%的准确率,57.6%的F1分数),超越了所有竞争模型,证实了合成数据预训练的鲁棒性。这些结果表明,基于合成扩散模型的预训练是连接自然图像迁移学习与医学MRI数据之间有前景的桥梁。
Method方法
03
本研究提出了一种基于合成MRI数据的生成式迁移学习管道,用于AD诊断。首先,使用来自ADNI 1.5T和AIBL数据集的MRI扫描训练一个类别条件DDPM,生成2D MRI切片。DDPM采用U-Net架构,通过平方余弦噪声调度、Adam优化器以及FID和KID分数进行性能评估,并评估了模型的记忆化问题。训练后,为每个临床组和投影平面生成了1000张2D MRI切片。其次,这些合成切片用于预训练多个2D架构(2D ADnet、ResNet18和ResNet101),这些模型被训练来预测2D MRI扫描的投影平面。其中,ResNet模型还进行了ImageNet与合成数据相结合的两阶段预训练。然后,通过ACS卷积将这些2D模型转换为3D模型。最后,这些3D模型在3T ADNI和OASIS-2数据集上进行微调,以执行CN/AD二分类、CN/MCI/AD三分类和ND/C/D分类任务。为了评估预训练和微调数据集大小对模型性能的影响,还进行了两项消融研究,并与LVM-Med和ViT等竞争模型进行了比较。
Discussion讨论
04
本研究选择生成2D平面投影而非完整3D MRI体积,是基于计算资源限制和现有高质量3D医疗数据集稀缺的实际考量。2D图像生成允许更快速的实验和更高质量的合成。尽管这导致部分体积和空间连续性信息丢失,但通过多个正交投影和ACS卷积策略部分弥补了这一问题。实验结果表明,本方法有效且优于ImageNet预训练及SOTA模型,在ADNI数据集上实现了高诊断准确率。ADnet模型在有限数据集上表现尤为突出,甚至优于ResNet架构。在OASIS-2数据集上,虽然性能有所下降,但这是由于任务复杂性、类别不平衡以及跨队列域偏移所致。即便如此,本研究提出的合成预训练策略仍比其他竞争方法更有效地缓解了这些影响。这表明,即使存在域偏移挑战,利用更接近AD影像分布的预训练数据也能产生更具可迁移性和判别性的表示。本研究还提供了一个可用于其他类似医学影像场景的预训练医学模型,具有重要应用价值。
Conclusion结论
05
本研究提出了一种利用合成MRI数据生成来解决真实MRI数据可用性限制的新方法。它采用条件去噪扩散概率模型生成9000张2D MRI扫描,涵盖不同的脑部视图和AD阶段。这些合成图像用于预训练2D模型,随后通过ACS卷积适应到3D。这一流程——合成图像生成、2D到3D模型转换和微调——在AD诊断中实现了高准确率,为医学影像领域的机器学习提供了一个可扩展且数据高效的解决方案。未来的工作方向包括生成3D合成MRI体积,探索混合2D-3D生成框架,整合临床约束以提高合成图像的标签保真度和诊断真实性,以及在更多大规模3D数据集上进行域特定预训练,进一步评估不同自监督预训练策略在AD诊断背景下的权衡,并将其专业化应用于帕金森病、多发性硬化症或脑肿瘤等其他神经系统疾病的跨疾病泛化。
Results结果
06
本研究首先通过定性(图2)和定量(表1、表2)分析评估了合成MRI图像的质量。结果显示,合成图像具有高真实感,且记忆化问题不明显,最高相关性(0.79)甚至低于AIBL与真实ADNI数据集之间的相关性(0.8)。在AD诊断任务中,在3T ADNI数据集上,基于合成数据预训练的2D ADnet模型在CN/AD二分类任务中取得了91.3%的准确率,优于基线模型28.8个百分点,并比最先进方法高8.8个百分点。在CN/MCI/AD三分类任务中,2D ADnet达到了74.5%的准确率和74.2%的F1分数,同样显著优于基线模型和ImageNet预训练模型。值得注意的是,使用合成数据预训练的模型性能与使用真实数据预训练的“Oracle”模型(数据量是合成数据的四倍)仅有0.3个百分点的差距。在OASIS-2数据集的ND/C/D分类任务中,我们的最佳模型达到了59.3%的准确率和57.6%的F1分数,超越了所有竞争模型。消融研究进一步表明,合成数据预训练在不同数据集大小下均能保持稳定的高性能,并且始终优于使用真实数据进行的预训练;同时,预训练的模型在不同微调数据集大小下都表现出更高的鲁棒性,并持续优于从零开始训练的模型。
Figure图
07
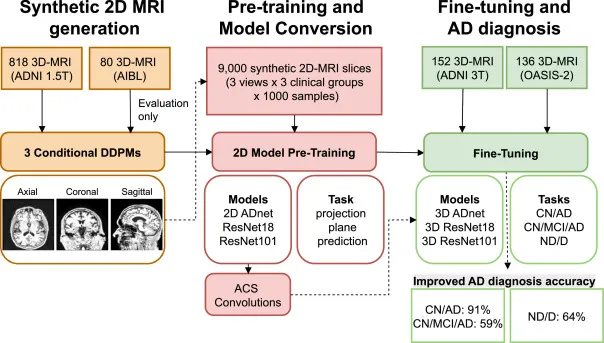
图1.提出的流程图:轴位、冠状位和矢状位MRI生成(橙色),2D模型预训练和转换为3D(粉色),以及AD诊断的微调(绿色)。
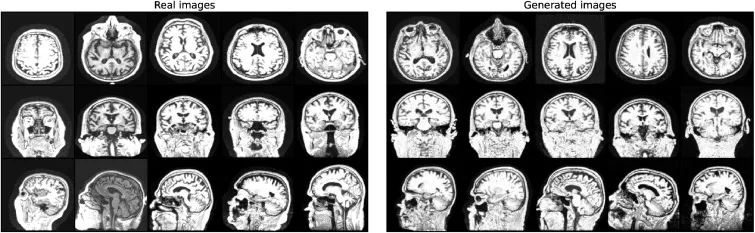
图2.真实(左)和生成(右)的MRI切片在三个解剖视图中的比较:轴位(顶部)、冠状位(中部)和矢状位(底部)。
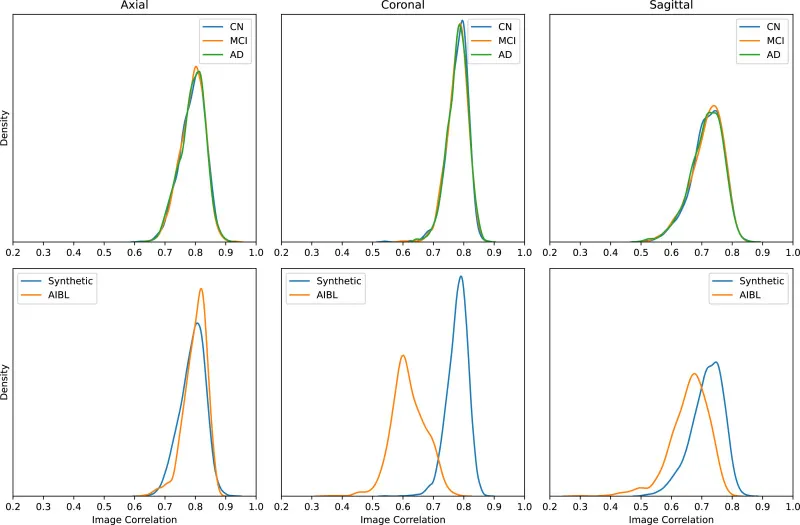
图3.不同解剖视图中最高相关性分布的比较。每列对应一个特定的MRI视图:轴位(左)、冠状位(中)和矢状位(右)。 (上排)合成图像与1.5T ADNI之间的相关性分布,按诊断类别(CN、MCI、AD)分组。(下排)合成图像与1.5T ADNI图像(蓝色)以及AIBL与1.5T ADNI数据(橙色)之间的相关性比较。
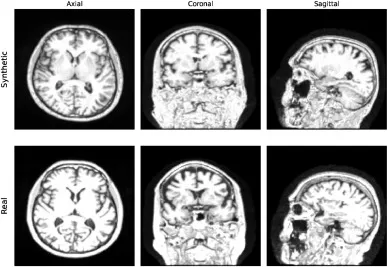
图4.不同解剖视图中最高相关性分布的比较:合成图像(顶行)和最相关的真实图像(底行)。
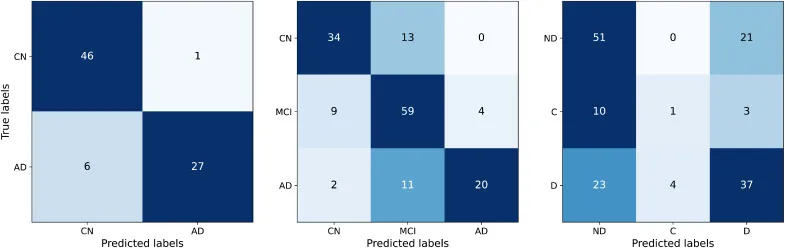
图5.最佳模型:CN/AD(左)、CN/MCI/AD(中)和ND/C/D(右)分类的混淆矩阵。
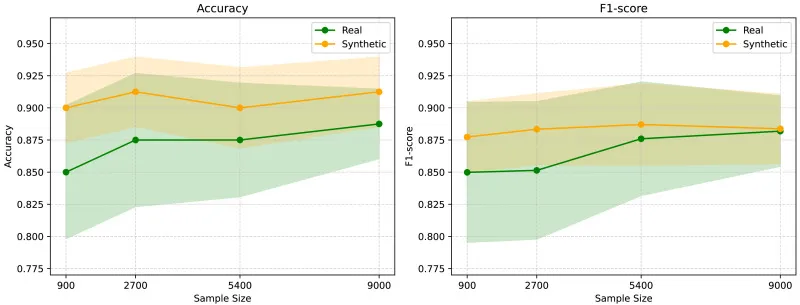
图6.不同预训练数据集大小下的AD诊断性能。使用真实(绿色)与合成(橙色)预训练数据时模型的准确率(左)和F1分数(右)。
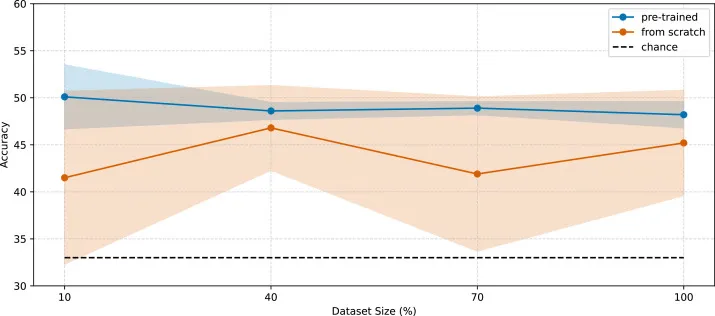
图7.不同数据集大小下CN/MCI/AD分类准确率的比较,包括预训练(蓝色)和从零开始训练(红色)。