2026.2.5
本研究提出了一种结合注意力机制、单元法线计算块和跨任务一致性损失的多任务学习方法Col3D-MTL,用于结肠镜图像的单目深度和表面法线估计,并在新数据集C3VD上显著提高了深度估计精度和模型泛化能力。
Title题目
01
Multi-task learning with cross-task consistency for improved depth estimation in colonoscopy
结合跨任务一致性的多任务学习在结肠镜深度估计中的应用与改进
文献速递介绍
02
结直肠癌是全球第三大常见癌症,结肠镜检查是诊断和治疗的金标准,但受限于复杂解剖环境和操作者经验,存在漏检问题。结肠镜检查中3D计算机视觉技术(如深度估计)因难以获取真实标签而发展受限。C3VD数据集通过硅胶模型提供了高保真度3D真值数据。单目深度估计在结肠镜中更具吸引力,但其泛化性受限。多任务学习结合几何相关辅助任务可增强特征提取。本文提出Col3D-MTL框架,通过共享编码器、独立解码器和跨任务一致性损失,共同进行单目深度和表面法线预测,并引入注意力机制和自监督学习提升性能和泛化性。
Aastract摘要
02
结肠镜筛查是评估结肠直肠异常的金标准,但由于结肠复杂的拓扑结构和多变的生理条件,单目深度估计极具挑战性。现有计算机视觉深度估计算法在自然场景中表现良好,但在结肠镜数据上的效果尚未广泛验证。本文提出了一种新颖的多任务学习(MTL)方法Col3D-MTL,该方法包含一个共享编码器和两个解码器(表面法线解码器和深度估计解码器)。深度估计器融入了注意力机制以增强全局上下文感知,并通过表面法线预测来改进几何特征提取。此外,本研究在表面法线和相机深度这两个几何相关任务之间应用了跨任务一致性损失。实验结果表明,该方法在C3VD数据集上将相对误差降低了15.75%,并将δ1.25精度提高了10.7%,优于现有最先进方法,并为该数据集提供了首次基准。
Method方法
03
本研究利用公开的C3VD结肠镜3D视频数据集,该数据集通过高保真硅胶模型生成,包含像素级深度和表面法线真值。提出的Col3D-MTL框架基于BTS单目深度估计网络,采用ResNet-50编码器和空洞空间金字塔池化模块。为增强特征提取,深度解码器集成了卷积块注意力模块(CBAM)。为利用几何信息,增加了独立的表面法线解码器,包含新颖的单元法线计算(UNC)块。模型通过深度(SILog)和表面法线(MAE)的加权损失优化。此外,引入了跨任务一致性(X-TC)损失,通过深度到表面法线(D2SN)模块将预测深度转换为法线,以强制任务间一致性。为提升模型对真实患者数据的泛化能力,编码器通过架构无关的掩膜图像建模(A2MIM)进行自监督预训练。
Discussion讨论
04
本文通过引入CBAM模块增强全局上下文感知,有效改善了单目深度估计的视觉线索提取,但可能导致局部模糊。为解决此问题,集成了表面法线估计辅助任务和UNC块,显著提升了几何特征提取能力,减少了模糊区域。跨任务一致性损失与D2SN模块的引入,通过强制深度和表面法线预测之间的一致性,进一步精化了高深度变化区域的预测。最终的Col3D-MTL+SSL框架在C3VD数据集上建立了新的基准,超越了现有最先进方法,尤其在未见过的大肠段表现出色。与NDDepth等方法相比,Col3D-MTL在复杂结肠拓扑结构中表现更优。自监督预训练(A2MIM)显著提升了模型对真实患者数据的泛化能力,避免了传统域适应方法的几何失真问题,从而生成了更清晰、更真实的3D场景重建和深度图。
Conclusion结论
05
结肠镜筛查仍是诊断炎症性肠病金标准,但其操作依赖性导致高漏诊率。恢复3D场景深度信息对定量评估至关重要。本文针对结肠镜单目深度估计的挑战,提出了Col3D-MTL框架。该框架结合了CBAM注意力机制以增强全局上下文感知,引入了带有新型单元法线计算块的表面法线解码器以提升3D表示,并采用了跨任务一致性方案来显式地强制深度和表面法线预测之间的一致性。全面的实验验证了Col3D-MTL网络的有效性,并引入了自监督掩膜图像建模方法,以提高模型在真实患者结肠镜数据集上的泛化能力。定量和定性结果均表明,所提出的网络优于现有最先进方法,尤其在训练阶段未见的结肠段表现显著改进,能生成更清晰的边界、更准确的小突起形状和更少的视觉伪影。未来工作将关注解决低光照和高方向变化小区域的预测不准确问题。
Results结果
06
消融研究显示,集成CBAM模块、多任务学习和跨任务一致性损失逐步提升了模型性能,其中L1损失函数在多任务学习中表现最佳。超参数研究确定了最佳损失权重配置,使Col3D-MTL框架在SILog、RMSE和δ1.25指标上相对于基线模型有显著改进。在C3VD数据集上的基准测试中,Col3D-MTL + SSL在所有深度评估指标上均优于现有最先进方法。按结肠段分析,Col3D-MTL + SSL在训练集中未见的降结肠段表现出卓越的泛化能力。定性结果表明,Col3D-MTL相比基线生成了更清晰的边界和更少的视觉伪影,3D投影更真实,并且自监督预训练显著提升了模型对真实患者数据的泛化性。
Figure图
07
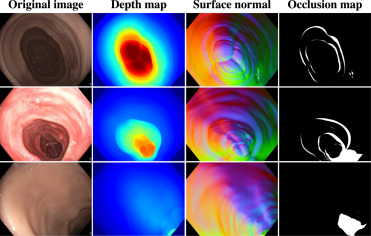
图1.C3VD数据集。示例数据包括原始RGB图像及其对应的真实深度图、表面法线图和遮挡图(Bobrow et al., 2023)。

图2.结合跨任务一致性的多任务学习(Col3D-MTL)。我们提出的框架遵循编码器-解码器方案,其中编码器由共享主干(θ)和空洞空间金字塔(ASPP)模块组成,用于在不同扩张率下提取上下文信息。解码器阶段包括一个主要的深度估计解码器(底部)和一个辅助的表面法线解码器(顶部)。我们的单元法线计算块(UNC块)使用两个特征通道(FC)来计算单元法线向量(nx、ny和nz)的元素。局部平面引导深度估计块(LPG块)还使用第三个FC来计算到相机的垂直距离,该距离与单元法线一起通过射线-平面交点(参见公式(2))提供局部深度信息c̃k×k。CBAM模块(Att)被引入到跳跃连接以及深度解码器的卷积层之后,以增强全局上下文感知。深度到表面法线(D2SN)模块接收预测深度并输出一个扭曲的表面法线图,该图与表面法线预测进行比较,以强制任务之间的一致性。表面法线解码器和D2SN模块可以很容易地与其他深度估计器结合,实现端到端的MTL-X-TC。A2MIM(参见第3.3节)用于通过基于掩膜图像建模的自监督学习方法,在模型和患者结肠镜数据上预训练我们的编码器θ。

图3.基线模型与我们提出的框架在最佳、平均和最差表现案例上的定性比较。我们展示了两种方法的绝对误差图,以观察最具挑战性的区域以及我们的BTS-CBAM-MTL-X-TC的影响。前两行展示了最佳表现案例(绿色),其中两种方法都产生了较低的绝对误差图。第三行和第四行展示了平均表现案例(蓝色),其中基线方法受纹理缺失和高深度变化区域影响,而我们的BTS-CBAM-MTL-X-TC框架解决了这些问题。在预测的表面法线图上可以观察到一致性,这有助于恢复场景的形状,例如结肠的褶皱和小息肉状突起。最后两行代表了挑战性案例(红色),其中两种方法都产生了不太准确的深度估计。通常位于场景最远部分的低光照区域对两种方法都构成了挑战。

图4.我们不同网络配置之间的定性比较。我们展示了输入图像、其对应的真实深度图、每种网络配置的深度预测及其对应的绝对误差图。白色箭头显示了每种网络配置相对于前一种的积极影响。添加CBAM模块部分减少了基线方法的平滑过渡。利用我们的MTL方法减少了过渡区域的绝对误差,但在纹理较低的区域未能恢复准确的估计。明确强制任务之间的一致性实现了增强的深度估计。
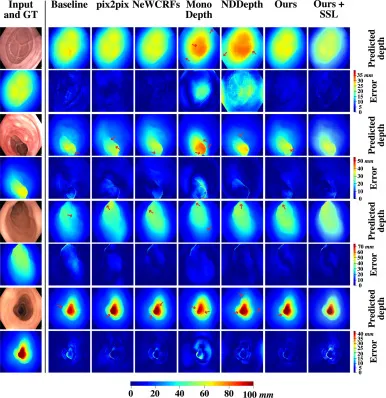
图5.本研究中所有评估方法之间的定性比较。测试集中提供了每个结肠段的一个样本及其对应的真实深度图。每种方法的深度预测及其对应的绝对误差图也一并提供。红色箭头指示了每种方法的挑战区域,例如结肠褶皱、息肉、遮挡区域、低纹理区域和低光照条件区域。

图6. 不同结肠段评估方法生成的3D投影定性比较。每个3D投影由50个深度图预测组成,这些预测根据C3VD数据集提供的真实相机轨迹投影到世界坐标空间中。在第一行(盲肠),我们的方法在胃肠道褶皱处实现了最锐利的边界(红色箭头)。第二行(降结肠)显示,与分析的其他网络相比,我们的方法能更好地投影息肉的形状(蓝色箭头)。在第三行(乙状结肠),结肠场景的整体几何形状受我们框架的扭曲程度较小(绿色箭头)。第四行(横结肠)表明,我们的网络在保持场景整体形状和减少伪影(绿色、蓝色和红色箭头)的同时,以更真实的细节恢复了内部结构。可视化使用Open3D库(Zhou et al., 2018)执行。

图7在真实患者结肠镜样本上的定性评估。我们评估了我们的基线方法和提出的方法在CVC-ColonDB-300(Bernal et al., 2012)和PolypGen(Ali et al., 2023)数据集中五个样本上的表现。来自两个数据集的前两行展示了Col3D-MTL方法在测试具有不同光度属性(例如对比度变化和镜面反射)的帧时的鲁棒性。每个数据集的第三个样本检查了所有方法在不同纹理和颜色细节(例如息肉边界和褶皱形状)上的性能。在每个数据集的最后两个样本中,我们比较了在由息肉和褶皱引起的遮挡区域帧上的预测。值得注意的是,Col3D-MTL+SSL实现了遮挡区域的精细边界,并减轻了Col3D-MTL在突起内部的错误深度预测。