Title
题目
ARDMR: Adaptive recursive inference and representation disentanglement for multimodal large deformation registration
ARDMR:面向多模态大变形配准的自适应递归推理与表征解纠缠
01
文献速递介绍
图像配准是在浮动图像与固定图像之间建立空间对应关系的基础技术,能够将二者对齐到统一坐标系中,以便后续进行定量分析(Chen等人,2021a;Zou等人,2022)。在医学影像领域,可变形配准技术广泛应用于手术路径规划(Han等人,2021)、辅助诊断(Xiao等人,2021)和治疗效果评估(Mok和Chung,2022)。目前,图像可变形配准的研究大多集中在单模态领域,而针对多模态、大变形的可变形配准研究仍相对有限。 在CT引导下肝癌介入消融手术中,围手术期通常需要对存在大位移的多模态肝脏图像进行可变形配准(Wei等人,2020)。具体而言,由于磁共振(MR)图像对血管、肿瘤等软组织的成像效果更优,术前通常会采集MR影像;而计算机断层扫描(CT)成像速度更快、设备要求更低,因此术中更受青睐。鉴于CT对软组织的成像效果较差,需要将术前MR图像与术中CT图像进行可变形配准,以帮助医生识别病灶并辅助规划穿刺路径(Carriero等人,2021;Glielmo等人,2024)。此外,消融术后可将术前MR图像与术后CT图像配准,助力医生评估治疗效果。 然而,多模态肝脏图像的可变形配准主要面临两大挑战(Haskins等人,2020)。第一个挑战源于不同模态图像的成像原理差异和采集设备不同,导致其强度差异显著,这对模型的学习能力提出了较高要求。第二个挑战是患者体位、呼吸等因素的变化会导致器官和软组织之间产生较大的非线性位移,这些因素大幅增加了图像可变形配准的空间复杂性。 传统多模态配准方法(Rueckert和Aljabar,2015;Avants等人,2008)依赖于优化配准损失,通常通过迭代优化算法实现。但在涉及多模态图像和大变形的复杂场景中,这些方法存在诸多局限性(Zhou等人,2023;Pielawski等人,2020)。首先,传统多模态图像配准采用迭代方式进行,每输入一幅新图像都需要重新优化,过程耗时(Pham等人,2024)。其次,传统方法难以捕捉不同模态之间复杂的语义关系(Han等人,2022),尤其是在图像强度和结构不一致的情况下。此外,基于优化的多模态配准方法易受图像噪声和大变形影响,往往会陷入局部最优解,导致配准结果不稳定。 近年来,基于深度学习的方法为多模态图像的快速、精准可变形配准开辟了新方向(Litjens等人,2017)。这些基于学习的方法利用神经网络强大的表征能力,能够更好地捕捉不同模态之间复杂的强度和空间关系(Song等人,2022)。许多配准模型采用基于UNet的架构作为变形场预测网络,其核心是将待配准的一对图像沿通道维度拼接后输入配准网络,网络输出预测的变形场,再通过变换模块根据该变形场对浮动图像进行空间变换,最后利用相似度度量指标对比变形后的浮动图像与固定图像以计算损失,从而指导模型训练。但这些模型在从拼接的多模态图像中提取特征以及处理固定图像与浮动图像之间的大变形方面能力有限(Ma等人,2024)。 部分研究者提出采用双输入模型对不同模态的特征进行编码(Song等人,2022;Kang等人,2022)。这些模型采用特征金字塔策略捕捉输入图像的多尺度特征,以从粗到细的渐进方式在每个尺度上进行配准。该方法允许对不同模态分别编码,且多尺度配准过程有助于应对大变形挑战(Ma等人,2023)。但该方法也存在一些局限性:首先,从粗到细的配准过程通常是在不同尺度上逐步应用变形场,缺乏各尺度特征之间的交互;其次,双分支编码旨在帮助模型更好地学习图像的固有特征以用于后续配准,但现有实现缺乏有效的约束机制,难以确保模态特异性特征与模态不变特征的有效解纠缠。 本文提出了一种新型表征解纠缠多模态配准模型,并引入创新的自适应递归推理配准策略,以进一步提升模型性能。具体而言,针对基于UNet的配准网络对多模态图像特征提取不足的问题,我们设计了参数不共享的双流输入特征编码器,使模型能够分别学习不同模态的内在特征;为引导双流编码器学习模态不变的图像特征,我们提出通过多层对比损失(MCLoss)实现模态表征解纠缠,该损失约束模型编码图像的内在特征,同时抑制图像强度等模态特异性特征。 肝脏易受呼吸等生理运动和患者体位变化引发的大变形影响。为应对大变形问题,我们采用多尺度可变形配准框架,并引入多尺度特征配准(MSFR)模块,该模块同时传播配准特征和变形场,以从粗到细的方式进行渐进式配准,在大变形配准任务中取得了更优效果。最后,为充分挖掘在数据集上经过长期训练的配准模型潜力,我们提出自适应递归推理配准策略,该策略根据不同尺度的配准状态自动确定多尺度配准的迭代次数。 综上,我们首先提出基准的解纠缠多模态配准模型(DMR),该模型将新型MCLoss和MSFR组件集成在统一的网络架构中,训练与推理过程中网络架构保持不变;在DMR的基础上,我们在测试阶段应用自适应推理策略(不修改已学习的权重),得到ARDMR模型。据我们所知,这是首个提出采用自适应递归推理提升多尺度多模态配准性能的研究。 本文的主要贡献总结如下: 1. 提出MSFR模块,该模块融合多尺度特征,突破了传统多尺度变形场传播的局限性,显著提升了模型对复杂变形的感知能力; 2. 提出新型MCLoss,使不同编码器深度下的跨模态特征分布保持一致,从而提升配准性能和模型泛化能力; 3. 引入自适应递归推理策略,无需重新训练网络即可提升性能,该模块能够针对每个病例在多尺度配准过程中自适应调整配准递归次数; 4. 在多个医疗中心的多模态肝脏数据集上,将所提模型与其他最先进(SOTA)模型进行对比评估,结果表明我们的模型不仅配准精度更优,还具备更强的泛化能力。
Aastract
摘要
Deformable registration of multimodal medical images constitutes a fundamental task in many medicalimage analysis applications, particularly in the diagnosis and treatment of liver cancer where differentmodality images are frequently employed. Despite the emergence of various learning-based registration models,multimodal registration remains a challenging task due to pronounced intensity differences and significanttissue deformations. To address these challenges, we approach the problem from two perspectives—mitigatingmodality discrepancies and enhancing the model’s capacity to handle large deformations. We propose amultimodal deformable registration model based on adaptive recursive inference and representation disentanglement (ARDMR). Specifically, to enhance the model’s ability to learn features from different modalities, weintroduce a modality representation disentanglement method, incorporating Multi-layer Contrastive Loss (MCL)to enforce the learning of modality-invariant features. To address the challenge of large complex deformations,we propose a Multi-Scale Feature Registration module (MSFR), which integrates features and deformation fieldsfrom different scales during the registration process. Finally, to further exploit the registration potential of thetrained model, we propose an adaptive recursive inference strategy. This strategy automatically determines theoptimal recursive registration scale and the number of iterations based on the image’s real-time registrationperformance. We conducted experiments on multimodal datasets collected from multiple medical centers andcompared our method with several state-of-the-art registration models. The results indicate that our proposedARDMR model outperforms others in both qualitative and quantitative evaluations. Specifically, comparedwith the baseline VoxelMorph model, ARDMR improves the DSC metric by 2.5%–5% across different datasets.Furthermore, tests on distribution-shifted data demonstrate that our model exhibits the best robustness andgeneralization.
多模态医学图像的可变形配准是许多医学图像分析应用中的基础任务,尤其在肝癌的诊断和治疗中,不同模态的图像被频繁使用。尽管已出现多种基于学习的配准模型,但由于显著的强度差异和明显的组织变形,多模态配准仍然是一项具有挑战性的任务。为解决这些问题,我们从两个角度入手——减轻模态差异和提升模型处理大变形的能力,提出了一种基于自适应递归推理与表征解纠缠的多模态可变形配准模型(ARDMR)。具体而言,为增强模型学习不同模态特征的能力,我们引入模态表征解纠缠方法,并融入多层对比损失(MCL)以促使模型学习模态不变特征;为应对复杂大变形的挑战,我们设计多尺度特征配准模块(MSFR),在配准过程中融合不同尺度的特征和变形场;最后,为充分挖掘训练后模型的配准潜力,我们提出自适应递归推理策略,该策略能根据图像的实时配准性能自动确定最优递归配准尺度和迭代次数。我们在多个医疗中心收集的多模态数据集上进行了实验,并与多种最先进的配准模型进行了对比。结果表明,所提ARDMR模型在定性和定量评估中均优于其他模型;与基准模型VoxelMorph相比,ARDMR在不同数据集上的骰子相似系数(DSC)指标提升了2.5%–5%。此外,在分布偏移数据上的测试证明,我们的模型具有最佳的鲁棒性和泛化能力。
Method
方法
Inspired by related research and aiming to address the challengesencountered in multimodal deformable registration for liver interventional therapy, we propose a multiscale multimodal registration modelthat incorporates representation disentanglement, along with an enhanced version employing adaptive recursive inference, as shown inFig. 2.Let 𝐼**𝑀 and 𝐼**𝐹 denote the moving image and fixed image, respectively, defined in an N-dimensional space 𝛺 ⊂ 𝑛 (with 𝑛 = 3). The goalof the registration model is to find the spatial transformation function𝜙𝑀→𝐹* , such that the moving image can be mapped to align with thefixed image 𝛺𝑀 → 𝛺𝐹 .
3.1. Dual-stream encoding branch*
The main function of this module is image feature extraction, withthe ideal goal of extracting modality-invariant features to facilitatesubsequent multi-scale registration. We use a convolutional neuralnetwork (CNN) as the backbone to perform image feature extraction.Since the model is designed to encode images from different modalities,the weight parameters of the two branches are independent, with eachbranch encoding features for moving and fixed images, respectively.The structural design of both branch encoders is identical, and onebranch is described as an example.The encoder branch consists of four encoding blocks. The first blockprimarily increases the feature channels without changing the imagefeature dimensions. The following three encoding blocks have the samestructure, as shown in Fig. 3a. These include convolutional downsampling and convolutional processes (instance normalization and activation functions applied after each convolution). After each encodingblock, the number of channels in the features doubles, while the spatialdimensions are reduced by half. In the last three layers of the encodingmodule, the image features are output denoted as 𝐹**𝑚 𝑖 , 𝐹𝑓 𝑖 for 𝑖 = 1, . . . ,4.
受相关研究启发,同时为解决肝脏介入治疗中多模态可变形配准面临的挑战,本文提出一种融合表征解纠缠的多尺度多模态配准模型,以及采用自适应递归推理的增强版本,如图2所示。设(I_M)和(I_F)分别表示浮动图像和固定图像,定义于N维空间(\Omega \subset \mathbb{R}n)(其中(n=3))。配准模型的目标是寻找空间变换函数(\phi_{M \to F}),使浮动图像能映射并对齐至固定图像所在空间(\Omega_M \to \Omega_F)。 ### 3.1 双流编码分支 该模块的核心功能是图像特征提取,理想目标是提取模态不变特征,为后续多尺度配准提供支持。采用卷积神经网络(CNN)作为骨干网络执行图像特征提取。由于模型需对不同模态的图像进行编码,两个分支的权重参数相互独立,分别负责对浮动图像和固定图像进行特征编码。两个分支编码器的结构设计完全一致,以下以其中一个分支为例进行说明。 编码器分支包含四个编码块。第一个编码块主要用于增加特征通道数,不改变图像特征维度;后三个编码块结构相同(如图3a所示),包含卷积下采样和卷积处理(每次卷积后均应用实例归一化和激活函数)。经过每个编码块后,特征通道数翻倍,空间维度减半。在编码模块的最后三层,输出的图像特征记为(F_mi)、(F_fi)(其中(i=1,\dots,4))。
Conclusion
结论
We propose a novel multimodal deformable registration modelARDMR, which effectively addresses the challenges of multi-modalregistration, large deformations, and model generalizability. We propose a multiscale feature registration mechanism and a multi-layermodality-invariant contrastive loss constraint to address the challengesof large deformations and multimodal registration, respectively. Additionally, we introduce an adaptive recursive inference strategy thatfurther enhances the model’s performance. Experiments on multimodaldatasets from multiple medical centers validate the superiority of ourmodel. The proposed model has demonstrated significant potential formultimodal image registration in liver cancer ablation therapy. Thecomponents and algorithmic strategies proposed in this study can serveas a reference and inspiration for researchers in related fields.
本文提出一种新型多模态可变形配准模型ARDMR,有效解决了多模态配准、大变形及模型泛化性三大核心挑战。针对大变形问题,设计了多尺度特征配准机制;针对多模态配准难题,提出了多层模态不变对比损失约束;同时引入自适应递归推理策略,进一步提升模型性能。基于多个医疗中心的多模态数据集开展实验,验证了所提模型的优越性。该模型在肝癌消融治疗中的多模态图像配准任务中展现出显著应用潜力,研究中提出的组件及算法策略可为相关领域研究者提供参考与启发。 要不要我帮你整理一份论文核心贡献提炼清单,聚焦ARDMR模型的创新点、技术优势及应用价值,方便快速梳理研究核心成果?
Results
结果
In this section, we present the experimental results of our proposed model, comparing their performance with that of other baselinemodels. Furthermore, we conduct ablation studies to examine thecontributions of the key modules within our model.
5.1. Multi-center liver dataset
Table 3 presents the quantitative registration evaluation metrics ofdifferent models on multimodal, multi-center datasets. According tothe DSC, HD95, and ASSD metrics, our proposed DMR and ARDMRmodels exhibit superior performance. The recursive inference-enhancedARDMR further improves upon DMR in terms of evaluation metrics.Specifically, compared with the baseline VM model, the ARDMR modelachieved improvements of 2.5% and 3.1% percentage points in the DSCmetric on the HB and HC datasets, respectively.From the results in Table 3, several conclusions can be drawn. (i)Almost all models perform better on the HB dataset than on the HCdataset. This is expected, as the models were trained on the HA andHB datasets, while the HC dataset exhibits a domain shift relativeto the model. Despite this, the results on the HC dataset show thatboth ARDMR and DMR still achieve the best performance. This indicates that our proposed multi-layer modality-independent contrastiverepresentation constraint effectively alleviates the impact of imagemodality, enabling the model to learn modality-invariant features. Thismethod not only enhances the model’s performance in multi-modalimage registration but also strengthens its ability to address domainshift issues in datasets. (ii) Analyzing the evaluation metrics basedon the model structure, we observe that models based on multi-scaleregistration generally perform better than those based on the singlestep deformation field prediction model. This suggests that using amulti-scale strategy to perform registration from coarse to fine caneffectively enhance the model’s performance.The last two columns of Table 3 report the inference times andmodel parameters for the evaluated models. In terms of inference time,most models complete processing in under 0.1 s, thereby meetingclinical requirements for intervention ablation. Notably, our proposedARDMR increases inference time by only 0.04 s compared to DMR,while delivering significant performance improvements. This demonstrates that our adaptive recursive inference method yields substantialperformance gains with minimal overhead. Regarding model parameters, the VIT-V and TM models exhibit the largest parameters, whereasthe VM model has the fewest. Our proposed ARDMR and DMR modelsfall into a medium-range parameter category. Overall, considering theevaluation metrics, inference time, and model parameters, our modelsachieve a superior trade-off between efficiency and accuracy.Fig. 6 presents the visualization results of different models on themultimodal multi-center liver dataset. The first two rows correspondto the visualization results on the private dataset. The first row showsthe registered images, while the second row displays the correspondingdeformation fields.Upon visual inspection of the registered images, our proposed modelexhibits superior performance in multimodal image registration. Moreover, the qualitative patterns observed in the images align closely withthe trends indicated by the quantitative metrics.Specifically, models based on multiscale registration (such as PIVIT,RDP, ModeT, DMR, and ARDMR) outperform models that output asingle-step deformation field (such as VM, TM, VIT-V, and LKU) inhandling larger deformations. This conclusion is intuitively illustratedin the yellow-boxed regions of the first row in Fig. 6. Further analysisof the deformation fields in the second row reveals that the amplitudeof the deformation fields for multiscale registration-based models islarger, enabling more effective alignment of different structures withinthe images and thus achieving more accurate registration.In the comparative analysis within the multiscale registration models, we found that PIVIT, RDP, and ModeT exhibit over-registrationissues at the organ edges (as shown in the yellow-boxed regions ofthe second row in the first row of Fig. 6), leading to some organtissues being erroneously deformed into parts of the ribs. In contrast, our proposed models, DMR and ARDMR, effectively address thischallenge. After registration, they maintain the smoothness of organboundaries, thereby demonstrating higher robustness and accuracy inthe registration of complex structures.
实验结果与分析 本节将呈现所提模型的实验结果,并与其他基准模型进行性能对比,同时通过消融实验验证模型中关键模块的贡献。 ## 5.1 多中心肝脏数据集 ### 5.1.1 定量结果分析 表3展示了不同模型在多模态、多中心数据集上的配准定量评估指标。基于骰子相似系数(DSC)、95%豪斯多夫距离(HD95)和平均对称表面距离(ASSD)指标,所提DMR和ARDMR模型表现更优,经递归推理增强的ARDMR在各项评估指标上进一步优于DMR。具体而言,与基准模型VoxelMorph(VM)相比,ARDMR在HB数据集和HC数据集上的DSC指标分别提升了2.5和3.1个百分点。 从表3结果可得出以下结论: 1. 几乎所有模型在HB数据集上的表现均优于HC数据集。这一结果符合预期,因为模型在HA和HB数据集上训练,而HC数据集与训练数据存在域偏移。尽管如此,ARDMR和DMR在HC数据集上仍取得最佳性能,表明所提多层模态无关对比表征约束有效缓解了图像模态差异的影响,使模型能够学习模态不变特征,既提升了多模态图像配准性能,又增强了模型应对数据集域偏移问题的能力。 2. 基于模型结构的评估指标分析显示,多尺度配准模型的表现普遍优于单步变形场预测模型。这表明采用从粗到细的多尺度配准策略,可有效提升模型性能。 表3最后两列报告了各模型的推理时间和参数量: - 推理时间方面,多数模型处理时间均在0.1秒以内,满足介入消融手术的临床需求。值得注意的是,所提ARDMR相较于DMR,推理时间仅增加0.04秒,却实现了显著的性能提升,表明自适应递归推理方法能以极小的开销获得大幅性能增益。 - 参数量方面,VIT-V和TM模型参数量最大,VM模型参数量最少,所提ARDMR和DMR模型处于中等参数量级别。综合评估指标、推理时间和参数量来看,所提模型在效率与精度之间实现了更优的平衡。 ### 5.1.2 定性结果分析 图6展示了不同模型在多模态多中心肝脏数据集上的可视化结果,前两行对应私有数据集的可视化结果,第一行是配准后的图像,第二行是对应的变形场。 通过视觉观察配准图像,所提模型在多模态图像配准中表现更优,且图像呈现的定性规律与定量指标反映的趋势高度一致: 1. 基于多尺度配准的模型(如PIVIT、RDP、ModeT、DMR、ARDMR)在处理大变形时,性能优于输出单步变形场的模型(如VM、TM、VIT-V、LKU)。这一结论在图6第一行的黄色框区域中得到直观体现。进一步分析第二行的变形场可见,多尺度配准模型的变形场幅值更大,能够更有效地对齐图像中的不同结构,从而实现更精准的配准。 2. 在多尺度配准模型的对比分析中发现,PIVIT、RDP和ModeT在器官边缘存在过配准问题(如图6第一行第二列的黄色框区域所示),导致部分器官组织被错误变形到肋骨区域。相比之下,所提DMR和ARDMR模型有效解决了这一问题,配准后仍能保持器官边界的平滑性,在复杂结构配准中展现出更高的鲁棒性和准确性。 要不要我帮你整理一份模型性能核心对比表,清晰汇总各模型在定量指标、推理效率、参数量及定性表现上的差异,方便快速梳理关键结论?
Figure
图

Fig. 1. Deformable registration models based on different network architectures. (a) Single-step deformation field prediction registration model; (b) Multi-scalepyramid architecture registration model; © Cascaded architecture registration model; (d) Proposed multi-scale modality-invariant and feature fusion registrationmodel (training stage); (e) Proposed adaptive recursive inference process(testing stage). In the multi-scale registration processes in (d) and (e), black arrowsindicate the propagation of the deformation field, while pink arrows denote the transmission of the registration feature
图1 基于不同网络架构的可变形配准模型 (a) 单步变形场预测配准模型;(b) 多尺度金字塔架构配准模型;© 级联架构配准模型;(d) 所提多尺度模态不变与特征融合配准模型(训练阶段);(e) 所提自适应递归推理过程(测试阶段)。在(d)和(e)的多尺度配准过程中,黑色箭头表示变形场的传播,粉色箭头表示配准特征的传递。
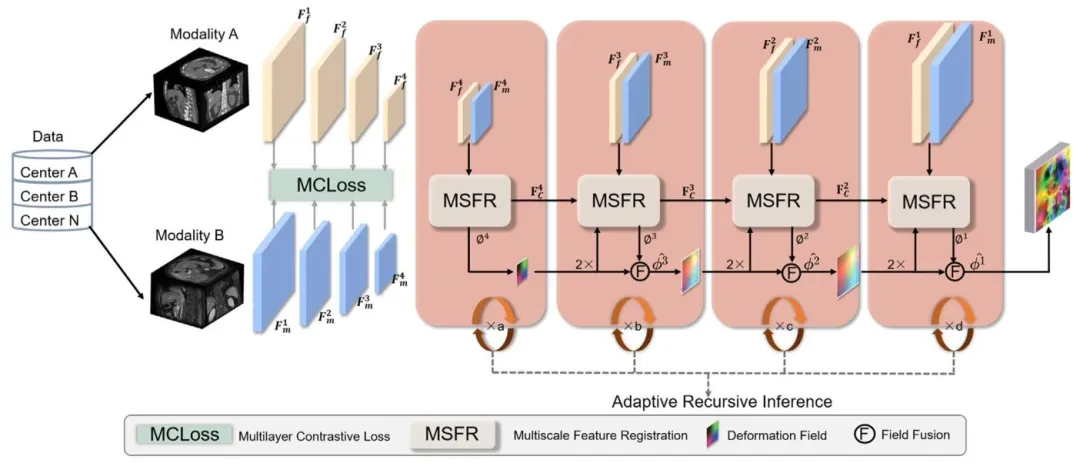
Fig. 2. Schematic diagram showing the overall structure of the ARDMR. From left to right, the figure illustrates the following: (i) multi-center, multi-modal datainput; (ii) image feature extraction process constrained by a multi-layer modality-invariant contrastive loss; (iii) the multi-scale fusion of deformation fields andfeatures during registration; (iv) testing enabled represents adaptive recursive inference registration.
图2 ARDMR模型整体结构示意图 从左至右依次展示以下内容:(i) 多中心、多模态数据输入;(ii) 受多层模态不变对比损失约束的图像特征提取过程;(iii) 配准过程中变形场与特征的多尺度融合;(iv) 支持自适应递归推理的测试阶段配准流程。
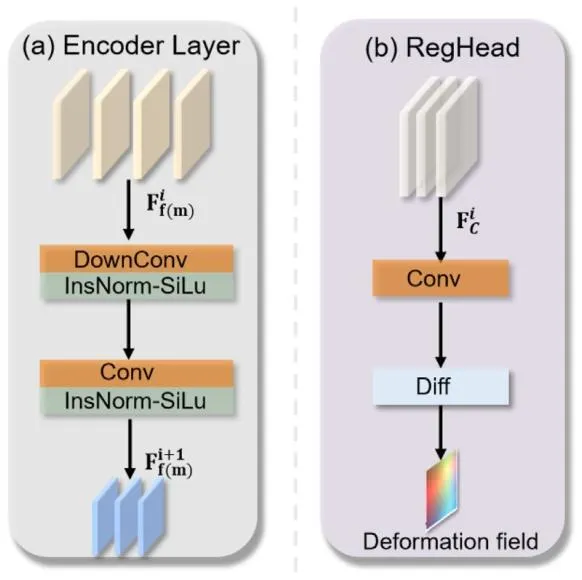
Fig. 3. (a) Details of the encoder block architecture. (b) Details of the RegHead architecture.
图3 核心模块架构细节 (a) 编码器块(encoder block)架构细节;(b) 配准头(RegHead)架构细节。
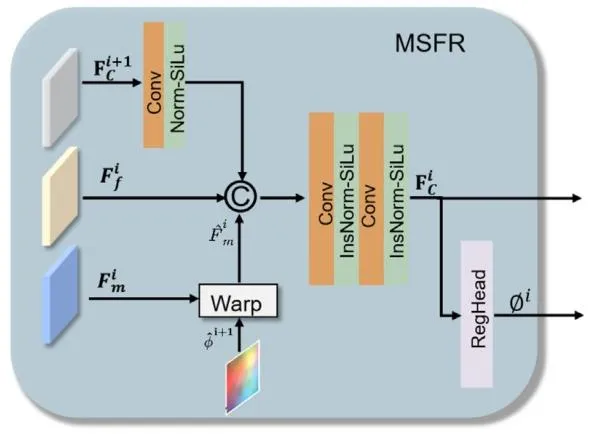
Fig. 4. Schematic diagram showing the overall structure of the MSFR
图4 多尺度特征配准(MSFR)模块整体结构示意图

Fig. 5. Schematic diagram showing the MCLoss. When using MR and CTimages of the same patient as positive pairs, the encoded feature vectors shouldbe closely clustered in high-dimensional space. Conversely, for negative pairscomprising images from different patients, the encoded vectors should remainwell separated. In the high-dimensional vector diagram, distinct shapes denotedifferent patients, while distinct colors correspond to different modalities
图5 多层对比损失(MCLoss)示意图 以同一患者的磁共振(MR)图像和计算机断层扫描(CT)图像作为正样本对时,其编码后的特征向量在高维空间中应紧密聚集;反之,对于由不同患者图像构成的负样本对,其编码向量应保持良好的分离状态。在高维向量图中,不同形状代表不同患者,不同颜色对应不同模态。

Fig. 6. Visual registration results for different models. The first row displays the registration outcomes on the private dataset, with the corresponding deformationfields in the second row. The third row presents the results on the AMOS dataset, and the fourth row shows the corresponding deformation fields. The fifth rowpresents the results on the multi-modal MRI dataset, and the sixth row shows the corresponding deformation fields.
6 不同模型的配准可视化结果
第一行:私有数据集上的配准结果,第二行:对应私有数据集的变形场;第三行:AMOS 数据集上的配准结果,第四行:对应 AMOS 数据集的变形场;第五行:多模态磁共振(MRI)数据集上的配准结果,第六行:对应多模态 MRI 数据集的变形场。

Fig. 7. The continuous deformation visualization results for the DMR model. 𝜙 4 , 𝜙3 , 𝜙2 , and 𝜙 1 denote the deformation fields at different scales, while 𝜙 𝑖◦ Mindicates the corresponding deformed moving image. This visualization illustrates the gradual deformation process applied to the moving image.
图7 DMR模型的连续变形可视化结果 $\phi_4$、$\phi_3$、$\phi_2$、$\phi_1$ 分别表示不同尺度下的变形场,$\phi_i \circ M$ 表示对应尺度下经变形后的浮动图像。该可视化结果展示了浮动图像的渐进式变形过程。 要不要我帮你整理一份连续变形过程解读清单,明确各尺度变形场的作用、图像变形的关键阶段及与配准精度的关联,方便快速理解渐进式配准的优势?

Fig. 8. The figure presents the continuous deformation visualization results of the ADMR model employing adaptive recursive inference. Each row correspondsto the deformation process at a specific scale. Compared with the DMR model, the ADMR model produces more natural deformations and better preserves details,as highlighted by the yellow box in the image.
图8 采用自适应递归推理的ARDMR模型连续变形可视化结果 每行对应特定尺度下的变形过程。与DMR模型相比,ARDMR模型的变形更自然,且能更好地保留细节(如图像中黄色框标注部分所示)。 要不要我帮你整理一份ARDMR与DMR变形效果对比清单,明确两者在变形自然度、细节保留及配准精度上的核心差异,方便快速凸显自适应递归推理的优势?

Fig. 9. The disentanglement effect is shown by t-SNE visualization. Panel Apresents results without MCL, and Panel B presents results with MCL. Yellowtriangles denote moving images, and blue circles denote fixed images.
图 9 t-SNE 可视化展示的表征解纠缠效果图 A 为未使用多层对比损失(MCL)的结果,图 B 为使用 MCL 的结果。黄色三角形代表浮动图像,蓝色圆形代表固定图像。
Table
表

Table 1The MR acquisition parameters at different centers include repetition time(TR), echo time (TE), and series.
表 1 不同中心的磁共振(MR)采集参数该表包含重复时间(TR)、回波时间(TE)及序列(series)等核心采集参数信息。

Table 2The CT acquisition parameters at different centers.
表2 不同中心的计算机断层扫描(CT)采集参数
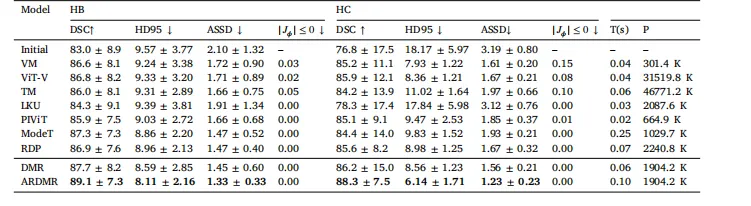
Table 3Quantitative results for different models on the HB and HC datasets. Here, T(s) denotes the inference time, and P denotes themodel parameters. The boldface indicates the best performance for each metric
表3 不同模型在HB和HC数据集上的定量结果 注:T(s) 表示推理时间,P 表示模型参数量;粗体数据为各项指标的最优性能。 要不要我帮你整理一份定量结果核心对比清单,提炼各模型在关键指标、推理效率及参数量上的差异,方便快速定位最优模型和性能优势?
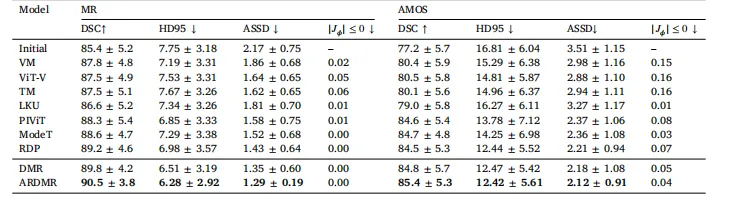
Table 4Quantitative results for different models on the multi-modal MRI and AMOS datasets. The boldface indicates the best performancefor each metric.
表 4 不同模型在多模态磁共振(MRI)数据集和 AMOS 数据集上的定量结果
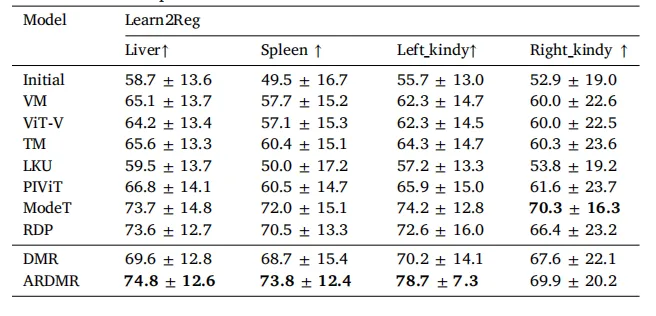
Table 5The quantitative registration results of the transfer model on the Learn2Regdataset. These models were trained using the HA and HB datasets. The boldfaceindicates the best performance for each metric.
表5 迁移模型在Learn2Reg数据集上的配准定量结果 所有模型均基于HA和HB数据集训练;粗体数据为各项指标的最优性能。

Table 6Quantitative registration metric results for ablation of the MCL and MSFR modules
表6 多层对比损失(MCL)与多尺度特征配准(MSFR)模块的消融实验配准指标结果

Table 7Ablation results of different loss function weights on the multi-center MR–CT liver dataset.
表7 不同损失函数权重在多中心磁共振-计算机断层扫描(MR-CT)肝脏数据集上的消融实验结果

Table 8The quantitative registration results of the transfer model on the AMOSdataset. These models were trained using the HA and HB datasets. The boldfaceindicates the best performance for each metric.
表8 迁移模型在AMOS数据集上的配准定量结果 所有模型均基于HA和HB数据集训练;粗体数据为各项指标的最优性能。