Title
题目
A novel gradient inversion attack framework to investigate privacy vulnerabilities during retinal image-based federated learning
一种新颖的梯度反转攻击框架,用于研究基于视网膜图像的联邦学习过程中的隐私漏洞
01
文献速递介绍
视网膜图像机器学习与联邦学习的隐私安全研究解析 视网膜作为中枢神经系统的延伸,为观察人体整体健康和衰老过程提供了独特视角,基于其图像的机器学习模型在疾病诊断、生物年龄评估等领域成效显著,但数据多样性不足和隐私安全问题制约了模型的实际应用,联邦学习成为潜在解决方案的同时也面临梯度反转攻击的风险。 ## 1. 视网膜图像机器学习的应用价值 - 疾病诊断覆盖广:既能精准分类眼部疾病(如糖尿病视网膜病变、年龄相关性黄斑变性、青光眼),也能预测非眼部疾病(如阿尔茨海默病、慢性肾病)。 - 生物年龄评估创新:仅通过视网膜图像即可估算生物年龄,其与实际年龄的差值(视网膜年龄差RAG)已成为重要生物标志物,可反映整体健康状况,预测帕金森病、心血管疾病等多种疾病风险及死亡风险。 ## 2. 模型训练的核心挑战:数据多样性不足 - 资源有限地区(如农村)缺乏充足训练数据,尤其难以获取代表性不足群体的数据。 - 数据覆盖范围窄易导致模型嵌入选择偏差,显著降低对目标人群的预测准确性。 - 关键需求:构建规模大、人口统计学特征多样且与目标人群匹配的数据集,以最大化模型的准确性和泛化能力。 ## 3. 联邦学习(FL)的解决方案与工作机制 ### 3.1 核心优势 作为分布式机器学习训练方法,联邦学习可整合网络中多个客户端的分散数据,无需将隐私数据传输至中央服务器,既规避了复杂数据隐私法规的限制,又能扩大训练数据规模。 ### 3.2 工作流程 1. 中央服务器向各客户端分发全局模型参数; 2. 客户端基于本地数据进行训练,向服务器反馈模型参数梯度更新; 3. 服务器聚合梯度更新以优化全局模型; 4. 迭代上述过程直至模型达到预设收敛阈值。 ### 3.3 眼科领域应用案例 - 用于早产儿视网膜病变诊断的联邦学习系统; - 基于分布式数据训练年龄相关性黄斑变性检测模型,均验证了联邦学习利用分散视网膜图像数据提升模型性能的潜力。 ## 4. 联邦学习的隐私漏洞:梯度反转攻击 ### 4.1 攻击风险本质 联邦学习并非绝对安全,攻击者可通过客户端与中央服务器之间交换的参数更新,重建敏感训练数据,这种漏洞主要通过梯度反转攻击利用。 ### 4.2 相关研究与具体风险 - 现有研究多聚焦分类任务,如iDLG、GradInversion等方法可恢复训练集的类别标签和高质量图像; - 针对视网膜图像的联邦学习:此前研究已证实,糖尿病视网膜病变分类任务中,可重建足以识别身份的眼底图像,而视网膜图像本身可作为可靠生物识别依据; - 高风险场景:“一机构一患者”场景(如个人眼底图像存储在智能手机)极易遭受图像类梯度反转攻击; - 双重泄露风险:攻击可能同时获取训练图像的隐私标签(如年龄、疾病诊断结果),泄露更多个人身份信息。 ## 5. 现有隐私保护技术的局限 | 保护技术 | 核心原理 | 主要不足 | |———-|———-|———-| | 安全聚合 | 聚合梯度更新时保障数据隐私 | 高维医学影像任务中计算开销过大 | | 同态加密 | 加密状态下进行数据运算 | 计算复杂度高,实用性不足 | | 可信执行环境(TEEs) | 依托硬件创建安全计算区域 | 依赖特定硬件,扩展性和可行性受限,不适用于资源紧张的医疗场景 | | 差分隐私随机梯度下降(DP-SGD) | 梯度更新中添加噪声 | 噪声会降低模型准确性,且无法完全抵御梯度反转攻击 | ## 6. 本研究的核心目标与贡献 ### 6.1 研究目标 开发新型梯度反转攻击框架,评估基于视网膜图像训练的机器学习模型(重点关注视网膜年龄预测任务)对该类攻击的脆弱性,同时利用公开数据提升攻击过程中重建图像的质量。 ### 6.2 三大核心贡献 1. 提出新型梯度反转攻击技术,借助公开数据优化重建图像质量,可用于评估联邦学习模型的攻击脆弱性; 2. 验证差分隐私在视网膜图像联邦训练中抵御梯度反转攻击的效果; 3. 首次全面评估视网膜年龄预测模型对梯度反转攻击的脆弱性,该任务的临床相关性正逐步提升。 要不要我帮你整理一份研究核心信息对比表,清晰列出数据挑战、解决方案、隐私风险及保护技术的关键要点,方便快速梳理核心逻辑?
Abatract
摘要
Machine learning models trained on retinal images have shown great potential in diagnosing various diseases. However, effectively training these models, especially in resource-limited regions, is often impeded by a lack of diverse data. Federated learning (FL) offers a solution to this problem by utilizing distributed data across a network of clients to enhance the training dataset volume and diversity. Nonetheless, significant privacy concerns have been raised for this approach, notably due to gradient inversion attacks that could expose private patient data used during FL training. Therefore, it is crucial to assess the vulnerability of FL models to such attacks because privacy breaches may discourage data sharing, potentially impacting the models’ generalizability and clinical relevance. To tackle this issue, we introduce a novel framework to evaluate the vulnerability of federated deep learning models trained using retinal images to gradient inversion attacks. Importantly, we demonstrate how publicly available data can be used to enhance the quality of reconstructed images through an innovative image-to-image translation technique. The effectiveness of the proposed method was measured by evaluating the similarity between real fundus images and the corresponding reconstructed images using three different convolutional neural network architectures: ResNet-18, VGG-16, and DenseNet-121. Experimental results for the task of retinal age prediction demonstrate that, across all models, over 92 % of the participants in the training set could be identified from their reconstructed retinal vessel structure alone. Furthermore, even with the implementation of differential privacy countermeasures, we show that substantial information can still be extracted from the reconstructed images. Therefore, this work underscores the urgent need for improved defensive strategies to safeguard patient privacy during federated learning
基于视网膜图像训练的机器学习模型在多种疾病诊断中展现出巨大潜力。 然而,这类模型的有效训练(尤其是在资源有限地区)往往因缺乏多样化数据而受阻。联邦学习(FL)通过利用客户端网络中的分布式数据,增加训练数据集的规模和多样性,为该问题提供了一种解决方案。尽管如此,这种方法引发了严重的隐私担忧,主要原因是梯度反转攻击可能泄露联邦学习训练过程中使用的患者隐私数据。因此,评估联邦学习模型对此类攻击的脆弱性至关重要——隐私泄露可能会阻碍数据共享,进而影响模型的泛化能力和临床实用性。为解决这一问题,我们提出了一种新颖的框架,用于评估基于视网膜图像训练的联邦深度学习模型对梯度反转攻击的脆弱性。值得注意的是,我们通过创新的图像到图像转换技术,展示了如何利用公开可得的数据提升重建图像的质量。我们采用三种不同的卷积神经网络架构(ResNet-18、VGG-16 和 DenseNet-121),通过评估真实眼底图像与对应重建图像的相似度,验证了所提方法的有效性。视网膜年龄预测任务的实验结果表明,在所有模型中,仅通过重建的视网膜血管结构就能识别出训练集中超过 92% 的参与者。此外,即使实施了差分隐私防护措施,我们发现仍可从重建图像中提取大量信息。因此,本研究强调,迫切需要改进防御策略,以在联邦学习过程中保护患者隐私。 要不要我帮你整理一份核心研究信息提炼表,清晰列出研究背景、核心方法、实验结果及关键结论?
Method
方法
2.1. Federated learning framework
In this work, we explore the FL scenario where K clients are used to collaboratively train a common global model for retinal age prediction. Our focus on the task of retinal age prediction is motivated by the concern that both the subject’s private age and retinal image might be reconstructed during a gradient inversion attack, significantly increasing the risk of exposing personally identifiable information tomalicious adversaries. Furthermore, we examine the scenario where each client contributes data from only one subject, as this situation has been previously shown to be particularly susceptible to gradient inversion attacks (Nielsen et al., 2022). Overall, the data contributed by each client during FL training consists of a single retinal fundus image and a corresponding age label. For our FL training, we employed three widely used global model architectures ResNet-18 (He et al., 2015), VGG-16 (Simonyan and Zisserman, 2015), and DenseNet-121 (G. Huang et al., 2018). ResNet-18 (18 layers with approximately 12 million parameters) is known for its use of residual connections, which facilitate the training of deeper networks by mitigating vanishing gradients. VGG-16 (16 layers with roughly 138 million parameters) is a sequential architecture characterized by its simplicity and depth, primarily utilizing stacked small convolutional filters. DenseNet-121 (121 layers with approximately 8 million parameters) features dense connectivity, where each layer within a block receives feature maps from all preceding layers, promoting feature reuse and efficient gradient flow. These specific models were selected based on their established effectiveness in prior federated learning studies. For instance, ResNet-18 has been successfully applied to ophthalmic disease prediction using retinal images in FL settings (Hanif et al., 2022) and (Gholami et al., 2023), while VGG-16 (Nielsen et al., 2022) and DenseNet-121 (Mohanty et al., 2023) have been validated for diabetic retinopathy classification. Crucially, they were also chosen because they represent fundamentally different approaches to network design, enabling evaluation of the generalizability of the developed method. To compare both their predictive performance and inherent vulnerability, all three architectures were subjected to identical training conditions and gradient inversion attack scenarios, including evaluations across various differential privacy levels. At the beginning of each training round t, the federated server distributes the current global model parameters, denoted as w*t, and the current batch norm mean μt* and variance σ2 t , to all participants for local model training. Local training updates are computed by each client to minimize the mean squared error (MSE) between predicted retinal age and chronological age. Next, each client transfers their locally computed gradient updates, represented for client k as Δw*k t* , and batch norm updates μk t and σ2 t,k* back to the central server. The model parameters are updated using an aggregationtechnique known as FedSGD (McMahan et al., 2023),represented as wt+1←wt α 1K* ∑Kk=1Δwk t (1) where α is the FedSGD learning rate. Furthermore, the updated batch norm statistics are computed as μt+1←(1 − η)μt + η1K* ∑Kk=1μk t (2) σ2 t+1←(1 − η)σ2 t + η K 1 ∑Kk=1*σ2 t,k (3) where η is the running average momentum hyperparameter. This training process is repeated until the global model converges to a prespecified performance criteria. The choice of using FedSGD, as opposed to other commonly used aggregation strategies such as FedAvg (McMahan et al., 2023), was guided by the specific characteristics of our simulation scenario, which reflects a 1-patient-per-institution FL setting. In this setup, each client possesses only a single data point, which consists of a single retinal fundus image paired with a corresponding age label. Applying FedAvg in such a case would require multiple local training iterations on this single data sample, which may lead to overfitting. In contrast, FedSGD performs one local gradient step per round and immediately communicates the result, which is more stable and appropriate when each client has extremely limited data available.In this work, a differential privacy strategy was implemented by adding Gaussian noise to the parameter gradients calculated by each client in every round. Therefore, the updated parameter gradients are expressed as Δw*k t* = Δw*k t* + N ( 0, σ2 DP) , where the noise N ( 0, σ2 DP) has a mean of zero and a variance of σ2 DP. Following the methodology developed by Hatamizadeh et al. (Hatamizadeh et al., 2023), the variance of the noise, σ2 DP, is set as σ2 DP = σ0 × P95, where σ0 is a tunable hyperparameter that controls the amount of added noise, and P95 is the 95th percentile of the absolute values of the gradients calculated across all trainable model parameters.
2.1 联邦学习框架 本研究探索的联邦学习场景中,由K个客户端协同训练一个用于视网膜年龄预测的通用全局模型。我们聚焦于视网膜年龄预测任务,核心顾虑在于梯度反转攻击可能同时重建受试者的隐私年龄与视网膜图像,大幅增加个人身份信息泄露给恶意攻击者的风险。此外,我们还考察了“每个客户端仅贡献一名受试者数据”的场景——此前研究(Nielsen等人,2022)已表明该场景对梯度反转攻击尤为敏感。在联邦学习训练过程中,每个客户端贡献的数据均包含一张视网膜眼底图像及对应的年龄标签。 本研究选用三种广泛应用的全局模型架构:ResNet-18(He等人,2015)、VGG-16(Simonyan和Zisserman,2015)以及DenseNet-121(G. Huang等人,2018)。ResNet-18包含18层网络,约1200万个参数,其核心优势是通过残差连接缓解梯度消失问题,助力深层网络训练;VGG-16包含16层网络,约1.38亿个参数,属于串行架构,以简洁性和深度为特征,主要采用堆叠的小尺寸卷积核;DenseNet-121包含121层网络,约800万个参数,具有密集连接特性,块内每层都会接收所有前层的特征图,可促进特征复用与高效梯度流动。 选择这些模型的依据主要有两点:一是它们在以往联邦学习研究中已被证实有效(例如ResNet-18已成功应用于联邦学习场景下的视网膜图像眼部疾病预测(Hanif等人,2022;Gholami等人,2023),VGG-16(Nielsen等人,2022)和DenseNet-121(Mohanty等人,2023)已通过糖尿病视网膜病变分类任务验证);二是它们代表了截然不同的网络设计思路,有助于评估所提方法的泛化性。为对比三种模型的预测性能与固有脆弱性,所有架构均在相同的训练条件和梯度反转攻击场景下进行测试,包括不同差分隐私水平的评估。 在每轮训练(t轮)开始时,联邦服务器会向所有参与者分发当前的全局模型参数(记为$\boldsymbol{w}t$)、批量归一化均值(记为$\boldsymbol{\mu}t$)和方差(记为$\boldsymbol{\sigma}^{2,t}$),供客户端进行本地模型训练。每个客户端通过最小化“预测视网膜年龄与实际年龄的均方误差(MSE)”计算本地训练更新,随后将本地计算的梯度更新(客户端k的梯度更新记为$\Delta\boldsymbol{w}^{k,t}$)以及批量归一化更新(记为$\boldsymbol{\mu}^{k,t}$和$\boldsymbol{\sigma}^{2,t,k}$)反馈至中央服务器。 模型参数通过联邦随机梯度下降(FedSGD)聚合策略更新(McMahan等人,2023),公式如下: $\boldsymbol{w}^{t+1} \leftarrow \boldsymbol{w}t + \alpha \cdot \frac{1}{K} \sum{k=1}^{K} \Delta\boldsymbol{w}^{k,t}$ (1) 其中$\alpha$为FedSGD的学习率。 此外,批量归一化统计量的更新公式如下: $\boldsymbol{\mu}^{t+1} \leftarrow (1 - \eta) \boldsymbol{\mu}t + \eta \cdot \frac{1}{K} \sum{k=1}^{K} \boldsymbol{\mu}^{k,t}$ (2) $\boldsymbol{\sigma}^{2,t+1} \leftarrow (1 - \eta) \boldsymbol{\sigma}^{2,t} + \eta \cdot \frac{1}{K} \sum{k=1}^{K} \boldsymbol{\sigma}^{2,t,k}$ (3) 其中$\eta$为滑动平均动量超参数。 上述训练过程会重复进行,直至全局模型达到预设的性能收敛标准。本研究选择FedSGD而非联邦平均(FedAvg,McMahan等人,2023)等常用聚合策略,主要是基于模拟场景的特定特征——该场景对应“一机构一患者”的联邦学习设置:每个客户端仅拥有一个数据样本(单张视网膜眼底图像+对应年龄标签)。若采用FedAvg,需对该单一样本进行多轮本地训练,易导致过拟合;而FedSGD每轮仅执行一次本地梯度计算并即时反馈结果,在客户端数据极度有限的情况下更稳定、更适用。 本研究通过在每个客户端每轮计算的参数梯度中添加高斯噪声实现差分隐私保护,含噪声的参数梯度更新公式如下: $\Delta\boldsymbol{w}^{k,t}{\text{noise}} = \Delta\boldsymbol{w}^{k,t}{\text{original}} + \mathcal{N}(0, \sigma2{\text{DP}})$ 其中$\mathcal{N}(0, \sigma2{\text{DP}})$表示均值为0、方差为$\sigma2{\text{DP}}$的高斯噪声。参考Hatamizadeh等人(2023)提出的方法,噪声方差$\sigma2{\text{DP}}$设定为$\sigma2{\text{DP}} = \sigma_0 \times P{95}$,其中$\sigma_0$为控制噪声量的可调超参数,$P{95}$为所有可训练模型参数梯度绝对值的95百分位数。 要不要我帮你整理一份联邦学习框架核心参数与公式汇总表,清晰列出模型架构、聚合策略、差分隐私参数及关键公式,方便快速查阅核心信息?
Conclusion
结论
In summary, it has been demonstrated that the gradient inversion attack framework developed in this work can effectively reconstruct private retinal image data at a quality level that significantly threatens patient privacy. Moreover, these attacks not only compromise the privacy of retinal data but also allow for the extraction of sensitive clinical information when applied to retinal age prediction models. Additionally, we demonstrated that the implementation of a cGAN-based image enhancement technique, trained using publicly available data, can improve the quality of reconstructions achieved through the gradient inversion optimization process. Importantly, this work investigates the scenario where each client sends updates based on data from a single subject, representing a more vulnerable setting compared to other federated learning scenarios where local training across multiple subjects leads to averaging of the gradients, inherently providing a layer of protection. The experimental results showed that even with the implementation of differential privacy measures, substantial information can still be extracted from the reconstructed images. Therefore, this work underscores the urgent need for more effective defensive strategies to safeguard data privacy against such vulnerabilities. While differential privacy offers a tunable but imperfect defense, techniques like homomorphic encryption and secure aggregation are potentially more effective methods to mitigate this risk, as they prevent malicious adversaries from accessing individual client gradients. While this work focuses on retinal data, the core methods developed in this study, including gradient inversion optimization and reconstruction enhancement, are applicable to other structured medical imaging domains, supporting broader relevance across FL-based clinical workflows.
研究总结与核心结论 本研究开发的梯度反转攻击框架能有效重建隐私视网膜图像,质量足以对患者隐私构成重大威胁;此类攻击不仅会泄露视网膜数据隐私,应用于视网膜年龄预测模型时还能提取敏感临床信息。 研究关键发现与价值如下: 1. 图像增强技术提升重建质量:基于条件生成对抗网络(cGAN)的图像增强技术,经公开数据训练后,可显著优化梯度反转优化过程生成的重建图像质量。 2. 高风险场景的隐私脆弱性:聚焦“单个客户端仅基于一名受试者数据发送更新”的场景,该场景比“多个受试者本地训练、梯度平均”的联邦学习场景更脆弱,而本研究证实此高风险场景下隐私泄露风险极高。 3. 差分隐私防护存在局限:即使实施差分隐私措施,仍可从重建图像中提取大量信息,其防护效果可调但并不完善。 4. 防御策略的改进方向:同态加密、安全聚合等技术更有望缓解该风险,这类技术能阻止恶意攻击者获取单个客户端的梯度数据。 5. 方法的广泛适用性:研究核心方法(包括梯度反转优化和重建增强技术)虽聚焦视网膜数据,但可推广至其他结构化医学影像领域,对基于联邦学习的临床工作流具有广泛参考意义。 综上,本研究强调,迫切需要更有效的防御策略来应对此类隐私漏洞,以保障医疗数据在联邦学习场景中的安全性。 要不要我帮你整理一份研究核心结论与应用价值提炼表,清晰列出关键发现、现有防护局限及未来改进方向,方便快速梳理核心价值?
Results
结果
Table 1 summarizes the baseline retinal age prediction performance on the holdout test set of real retinal images across different differential privacy noise levels σ0. Without differential privacy (σ0 = 0), the ResNet-18 model achieved an MAE of 5.73 ± 0.08 years and a Pearson correlation coefficient of 0.58 ± 0.01. Similarly, the VGG-16 model obtained an MAE of 5.72 ± 0.09 years and a Pearson correlation coefficient of 0.56 ± 0.01, while the DenseNet-121 model reached an MAE of 5.68 ± 0.07 years and a Pearson correlation coefficient of 0.59 ±0.01. Interestingly, when differential privacy was applied with σ0 values of 20 or lower, no significant differences in performance were observed (p = 0.27, one-way ANOVA). However, at σ0 = 30, model performance began to decline. Specifically, the ResNet-18 model achieved an MAE of 6.23 ± 0.20 years and a Pearson correlation coefficient of 0.49 ± 0.03; the VGG-16 model had an MAE of 6.45 ± 0.25 years and a Pearson correlation coefficient of 0.43 ± 0.05; and the DenseNet-121 model achieved an MAE of 5.92 ± 0.18 years and a Pearson correlation coefficient of 0.54 ± 0.03. At higher differential privacy levels (σ0 = 50 and σ*0 = 100), model performance deteriorated further, becoming worse than simply predicting the mean age of the training set (MAE of 7.42 ±0.05 years). This suggests that at these elevated σ0 values, the gradients become excessively noisy, preventing effective model convergence.Fig. 4 presents examples of images reconstructed using the proposed gradient inversion framework for the ResNet-18 model, both with and without the accompanying cGAN-based enhancement strategy without using differential privacy (σ0 = 0). It can be observed that the reconstructed images retain similar anatomical characteristics as the actual fundus images, such as the position and dimensions of the optic disc and macula, along with the structure of the retinal vessels. Furthermore, the proposed enhancement strategy boosts the visual similarity between the real fundus images and their reconstructed counterparts. Similar results were observed for the VGG-16 and DenseNet-121 models inSupplementary Fig. 1 and Supplementary Fig. 2, respectively.The evaluation metric values used to quantify the similarity between real fundus images and their reconstructions are shown in Table 2 for σ0 = 0. Overall, the use of the proposed cGAN-based image enhancement strategy significantly improved the quality of the reconstructed images, enhancing similarity across all metrics (p* < 0.001 for each comparison, assessed using a paired t-test for each metric). For instance, the MSE notably decreased from 0.179 ± 0.063 (unenhanced) to 0.014 ± 0.011 (enhanced) for the ResNet-18 model, from 0.195 ± 0.068 (unenhanced) to 0.018 ± 0.013 (enhanced) for the VGG-16 model, and from 0.162 ± 0.057 (unenhanced) to 0.011 ± 0.009 (enhanced) for the DenseNet-121 model.Fig. 5 showcases an example of image reconstruction and vessel segmentation being performed for varying σ0 values for the ResNet-18 model. It can be observed that as the value of σ0 increases, the overall visual quality of the reconstructed images decreases, with the anatomical regions becoming blurrier. Additionally, the vessel structure in these images increasingly differs from that in the real fundus image with higher σ0 values. Similar results were observed for the VGG-16 and DenseNet-121 models in Supplementary Fig. 3 and Supplementary Fig. 4, respectively.The effectiveness of recovering private age labels during gradient inversion attacks for different values of σ0 for differential privacy is shown in Table 3. Overall, recovery becomes more challenging as σ0 increases. For instance, at σ0 = 0, the age can be nearly perfectly recovered with an MAE of 1.10 × 10
− 6 ± 5.03 × 10− 8 years for ResNet- 18, MAE of 5.05 × 10− 6 ± 5.12 × 10− 8 years for VGG-16, MAE of 9.95 ×10− 7 ± 4.89 × 10− 8 years for DenseNet-121. Conversely, at σ0 = 100, the MAE increases significantly to 21.60±1.83 years for ResNet-18, 20.45 ± 1.95 years for VGG-16, and 19.51 ± 1.75 years for DenseNet- However, even when using σ0 = 20, the age is recoverable to some extent with an MAE of 4.14 ± 0.35 years for ResNet-18, 3.95 ±0.38 years for VGG-16, 4.22 ± 0.32 years for DenseNet-121, demonstrating a high level of accuracy in extracting the patient’s age, even at a moderately high level of differential privacy.Table 3 summarizes the effectiveness of gradient inversion attacks in recovering private age labels under varying differential privacy noise levels σ0. In general, recovering age labels becomes increasingly difficult as σ0 increases. For example, at σ0 = 0 (no differential privacy), age labels can be recovered almost perfectly, with extremely low MAEs: 1.10 × 10− 6 ± 5.03 × 10− 8 years for ResNet-18, 5.05 × 10− 6 ± 5.12 ×10− 8 years for VGG-16, and 9.95 × 10− 7 ± 4.89 × 10− 8 years for DenseNet-121. In contrast, at σ0 = 100, the MAE significantly increases to 21.60 ± 1.83 years for ResNet-18, 20.45 ± 1.95 years for VGG-16, and 19.51 ± 1.75 years for DenseNet-121. However, even at a moderately high differential privacy level (σ0 = 20), age labels remain partially recoverable, with MAEs of 4.14 ± 0.35 years for ResNet-18, 3.95 ± 0.38 years for VGG-16, and 4.22 ± 0.32 years for DenseNet- This indicates that patient age can still be extracted with relatively high accuracy despite the presence of moderate differential privacy noise.Figs. 6 and 7 illustrate the top-1 and top-5 image identifiability precision, respectively, for reconstructed images evaluated using PSNRand Dice scores across various differential privacy noise levels σ0. Precision is highest at lower σ0 values and decreases as σ0 increases. For example, at σ0 = 0, the ResNet-18 model achieves a top-1 Dice precisionof 0.94 ± 0.02 and a top-5 Dice precision of 0.98 ± 0.01; the VGG-16 model achieves a top-1 Dice precision of 0.92 ± 0.02 and a top-5 Dice precision of 0.95 ± 0.01; and the DenseNet-121 model achieves a top-1Dice precision of 0.95 ± 0.01 and a top-5 Dice precision of 0.98 ± 0.01. Notably, even at a moderately high σ0 value of 20, the ResNet-18 model maintains a top-1 PSNR precision of 0.72 ± 0.03 and a top-5 PSNR precision of 0.88 ± 0.04; the VGG-16 model has a top-1 PSNR precision of 0.68 ± 0.04 and a top-5 PSNR precision of 0.82 ± 0.05; and the DenseNet-121 model achieves a top-1 PSNR precision of 0.73 ± 0.04 and a top-5 PSNR precision of 0.87 ± 0.03. Similarly, at σ0 = 20, the Dice score top-1 precision is 0.62 ± 0.03 and top-5 precision is 0.84 ±0.02 for ResNet-18; 0.58 ± 0.06 (top-1) and 0.81 ± 0.04 (top-5) for VGG-16; and 0.64 ± 0.05 (top-1) and 0.85 ± 0.03 (top-5) for DenseNet- These results indicate that substantial uniquely identifiable information remains in reconstructed images even at higher differential privacy levels. Additionally, the VGG-16 model exhibited significantly lower image identifiability precision compared to the ResNet-18 and DenseNet-121 models (p < 0.01 using paired t-tests).
视网膜年龄预测模型的隐私脆弱性实验结果解析 本部分通过多组实验,从模型预测性能、重建图像质量、隐私年龄恢复效果及图像可识别性四个维度,系统评估了联邦学习场景下视网膜年龄预测模型对梯度反转攻击的脆弱性,以及差分隐私(DP)噪声水平(σ₀)的影响。 ## 1. 基线模型预测性能(表1) - 核心结论:低水平DP噪声(σ₀≤20)对模型性能无显著影响,高水平噪声(σ₀≥30)导致性能大幅下降。 - 关键数据: - 无DP(σ₀=0)时,三款模型MAE均在5.68-5.73年之间,Pearson相关系数0.56-0.59,性能接近; - σ₀=20及以下时,单因素方差分析显示性能无显著差异(p=0.27); - σ₀=30时,模型性能开始下滑(如VGG-16的MAE升至6.45±0.25年,相关系数降至0.43±0.05); - σ₀=50/100时,性能进一步恶化,MAE超过7.42年(仅预测训练集平均年龄的性能水平),因梯度噪声过大阻碍模型有效收敛。 ## 2. 重建图像质量评估(图4、图5及表2) ### 2.1 无DP场景(σ₀=0) - 基础重建效果:梯度反转攻击生成的图像($\hat{\boldsymbol{x}}k$)保留了真实眼底图像的核心解剖特征,包括视盘、黄斑的位置和尺寸,以及视网膜血管结构; - cGAN增强效果:通过条件生成对抗网络(cGAN)优化后的重建图像($\hat{\boldsymbol{x}}{k,\text{enhanced}}$),与真实图像的视觉相似度显著提升,所有评估指标均有统计学意义上的改善(p<0.001); - 量化数据:三款模型的MSE均大幅下降,如DenseNet-121从0.162±0.057降至0.011±0.009,图像质量明显优化。 ### 2.2 不同DP噪声水平的影响(σ₀变化) - 视觉趋势:随σ₀增大,重建图像的整体视觉质量下降,解剖区域逐渐模糊,血管结构与真实图像的差异愈发明显(图5及补充图3、4); - 模型一致性:ResNet-18、VGG-16、DenseNet-121均呈现相同趋势,验证了结论的泛化性。 ## 3. 隐私年龄标签恢复效果(表3) - 核心结论:年龄恢复难度随σ₀增大而上升,但中等水平DP(σ₀=20)仍无法完全阻断年龄泄露,高噪声(σ₀=100)下泄露风险显著降低但未完全消除。 - 关键数据: - σ₀=0时,年龄几乎可完美恢复,MAE低至10⁻⁶~10⁻⁷年量级(三款模型表现接近); - σ₀=20时,仍能以较高精度恢复年龄,MAE为3.95-4.22年(VGG-16最优,DenseNet-121略高); - σ₀=100时,MAE显著增至19.51-21.60年,年龄恢复准确性大幅下降,但未降至随机猜测水平。 ## 4. 重建图像的可识别性(图6、图7) - 评估指标:基于峰值信噪比(PSNR)和骰子系数(Dice)的Top-1/Top-5识别精度(即通过重建图像匹配真实受试者的准确率)。 - 核心结论:即使在中等DP水平下,重建图像仍保留大量独特身份信息,可识别性较高。 - 关键数据: - σ₀=0时,三款模型的Top-1 Dice精度达0.92-0.95,Top-5达0.95-0.98,几乎可精准识别受试者; - σ₀=20时,Top-1 PSNR精度为0.68-0.73,Top-5为0.82-0.88;Top-1 Dice精度为0.58-0.64,Top-5为0.81-0.85,仍具备强可识别性; - 模型差异:VGG-16的可识别性显著低于ResNet-18和DenseNet-121(p<0.01),推测与网络架构的特征提取方式相关。 要不要我帮你整理一份实验核心结果汇总表,清晰列出不同σ₀水平下三款模型的预测性能、年龄恢复MAE、图像可识别性关键数据,方便快速对比分析?
Figure
图
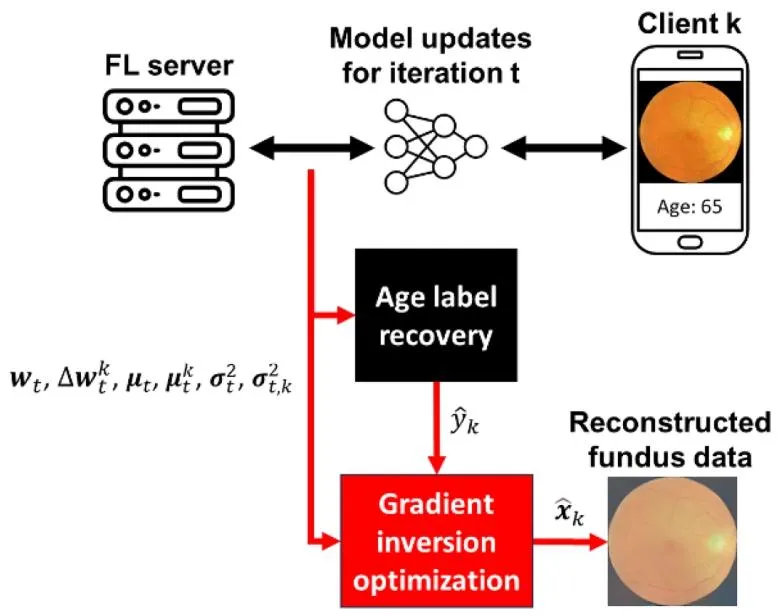
Fig. 1. Summary of gradient inversion attack process to recover private age label yk and reconstruct the private fundus image data x*k* using information communicated between the federated learning (FL) server and client k, during training round t.
图1 训练轮次t期间,利用联邦学习(FL)服务器与客户端k之间的通信信息,恢复隐私年龄标签$y_k$并重建隐私眼底图像数据$\boldsymbol{x}_k$的梯度反转攻击流程汇总。
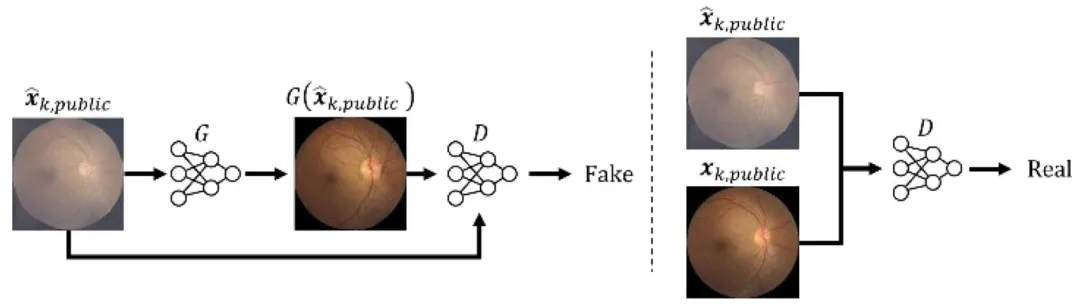
Fig. 2. Summary of conditional generative adversarial network used to map reconstructed images x̂k*, public to real images x k,public. Specifically, the discriminator D learns to differentiate between images synthesized by the generator G, and real fundus images.
图2 条件生成对抗网络流程汇总 该网络用于将重建图像$\hat{\boldsymbol{x}}{k,\text{public}}$映射至真实图像$\boldsymbol{x}{k,\text{public}}$。具体而言,判别器$D$负责学习区分生成器$G$合成的图像与真实眼底图像。

Fig. 3. Computing the quality enhanced reconstruction x̂k,enhanced* from the output of the gradient inversion attack process x̂k.
图3 基于梯度反转攻击输出结果$\hat{\boldsymbol{x}}k$计算质量增强型重建图像$\hat{\boldsymbol{x}}{k,\text{enhanced}}$的流程

Fig. 4. Example images showing image reconstruction quality for the ResNet-18 model. The top row displays real fundus images. The middle row presents images reconstructed through the proposed gradient inversion optimization scheme without using the developed image enhancement strategy. The bottom row shows the reconstructed images after image enhancement.、
图4 ResNet-18模型的图像重建质量示例图 - 上行:展示真实眼底图像; - 中行:呈现通过所提梯度反转优化方案重建的图像(未使用所开发的图像增强策略); - 下行:展示经图像增强后的重建图像。
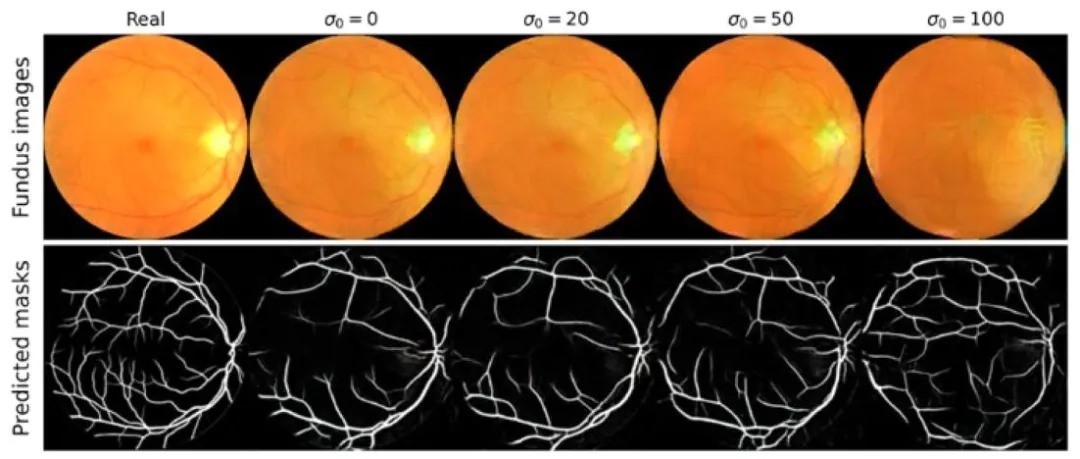
Fig. 5. Example of fundus image reconstruction and resulting vessel segmentation mask for different values of σ0 for differential privacy with the ResNet-18 model. The top row displays the fundus images, and the second row presents the vessel segmentation masks. Additionally, the first column displays the real fundus image and its corresponding vessel segmentation mask for comparison.
图5 ResNet-18模型在不同差分隐私噪声水平σ₀下的眼底图像重建及血管分割掩码示例 - 上行:展示各σ₀对应的重建眼底图像; - 第二行:呈现对应重建图像的血管分割掩码; - 第一列:展示真实眼底图像及其对应的血管分割掩码,作为对比基准。
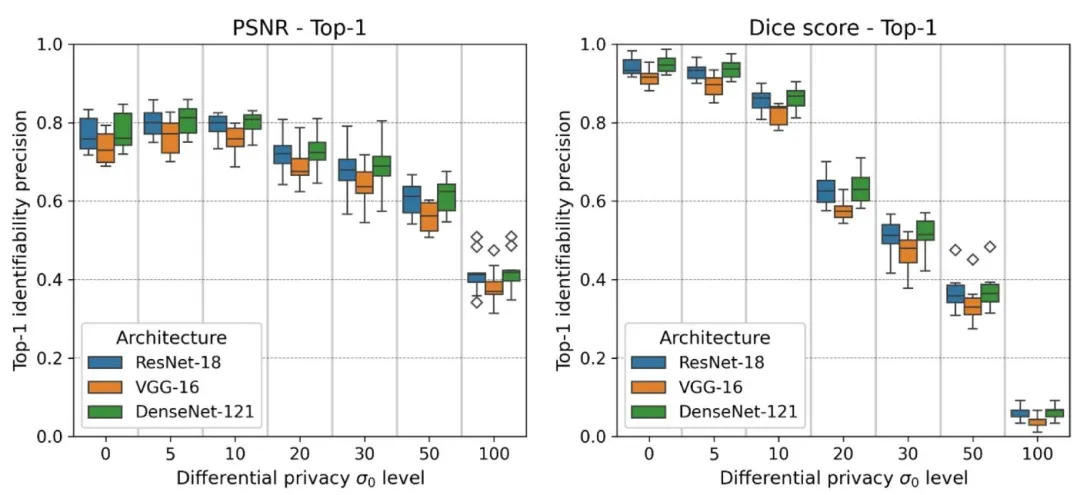
Fig. 6. Box plots illustrating the top-1 image identifiability precision at various σ0 values for differential privacy. The left plot displays the top-1 image identifiability precision based on the peak signal-to-noise ratio (PSNR), and the right plot presents theprecision based on the Dice score. Blue boxes represent the ResNet-18 model, orange boxes represent the VGG-16 model, and green boxes represent the DenseNet-121 model.
图6 不同差分隐私噪声水平σ₀下Top-1图像可识别性精度的箱线图 - 左图:基于峰值信噪比(PSNR)的Top-1图像可识别性精度; - 右图:基于骰子系数(Dice score)的Top-1图像可识别性精度; - 图例说明:蓝色箱形代表ResNet-18模型,橙色箱形代表VGG-16模型,绿色箱形代表DenseNet-121模型。

Fig. 7. Box plots illustrating the top-5 image identifiability precision at various σ0 values for differential privacy. The left plot displays the top-5 image identifiability precision based on the peak signal-to-noise ratio (PSNR), and the right plot presents the precision based on the Dice score. Blue boxes represent the ResNet-18 model, orange boxes represent the VGG-16 model, and green boxes represent the DenseNet-121 model.
图7 不同差分隐私噪声水平σ₀下Top-5图像可识别性精度的箱线图 - 左图:基于峰值信噪比(PSNR)的Top-5图像可识别性精度; - 右图:基于骰子系数(Dice score)的Top-5图像可识别性精度; - 图例说明:蓝色箱形代表ResNet-18模型,橙色箱形代表VGG-16模型,绿色箱形代表DenseNet-121模型。
Table
表

Table 1 Performance of age prediction on the holdout test set using differential privacy with varying values of σ0 for each model type, measured using the mean absolute error (MAE) in years, and the Pearson correlation coefficient.
表1 不同模型在不同差分隐私噪声水平σ₀下的年龄预测性能 该表采用平均绝对误差(MAE,单位:年)和皮尔逊相关系数,衡量各模型在独立测试集上的年龄预测表现,测试集由真实视网膜图像构成,变量为差分隐私噪声水平σ₀。

Table 2 Comparison of image similarity metrics between original and reconstructed fundus images for σ0 = 0 across all model types, evaluated for reconstructions with and without image enhancement.
表2 所有模型在σ₀=0时原始眼底图像与重建眼底图像的相似度指标对比 该表针对无差分隐私(σ₀=0)的场景,对比了所有模型在“未使用图像增强”和“使用图像增强”两种情况下,原始眼底图像与重建眼底图像的相似度指标。

Table 3 Mean absolute error (MAE) of recovering private age label during gradient inversion attack using differential privacy with varying values of σ0.
表3 不同差分隐私噪声水平σ₀下,梯度反转攻击恢复隐私年龄标签的平均绝对误差(MAE)