Title
题目
Anatomically and metabolically informed diffusion for unified denoising and segmentation in low-count PET imaging
结合解剖学和代谢信息的扩散模型用于低计数PET成像中的联合去噪与分割
01
文献速递介绍
正电子发射断层显像(PET)相关研究综述 正电子发射断层显像(PET)是一种高灵敏度核医学成像技术,广泛应用于肿瘤学、神经病学和心脏病学领域(Kitson等人,2009)。重建后的PET图像通常需结合计算机断层扫描(CT)图像使用,用于识别病灶、定位器官,并量化临床指标——如代谢肿瘤体积(MTV)、感兴趣区域(ROIs)内的标准化摄取值(SUV)以及总病灶糖酵解量(TLG),进而为疾病诊断和治疗方案制定提供支持(Chen等人,2012),具体如图1所示。图像质量和下游语义分析精度是影响量化准确性的两个关键因素:图像质量主要由噪声水平决定,而噪声水平又取决于PET采集过程中探测到的光子事件数量,这些光子计数则受示踪剂剂量、扫描时长和扫描仪效率等因素影响;精准的语义分析需要经验丰富的医师进行细致标注,该过程既耗费人力又耗时。 近年来,深度学习在通过图像去噪和自动分割解决这些挑战方面展现出巨大潜力。去噪技术能够从低计数采集数据中生成高计数PET图像(Bousse等人,2024),从而减少示踪剂剂量、缩短扫描时间,提升患者舒适度并降低运动伪影影响;同时,自动分割技术可通过高效勾勒感兴趣区域(ROIs)显著减轻医师工作负担(Yousefirizi等人,2021)。 在深度学习PET图像去噪领域,随着各类模型的发展已取得显著进展,涵盖卷积神经网络(CNNs)(Angelis等人,2021;Liu等人,2022)、生成对抗网络(GANs)(Xue等人,2022;Zhu等人,2023)、视觉Transformer(ViTs)(Jang等人,2023),以及近年来出现的去噪扩散概率模型(DDPMs)(Han等人,2023;Gong等人,2024a;Xie等人,2024)。此外,部分模型还集成了提升实际适用性的功能,例如噪声水平自适应机制(Xie等人,2023)和跨中心数据隐私保护考量(Zhou等人,2023)。尽管取得了这些进展,深度学习去噪后的PET图像仍面临关键挑战:一是过度平滑导致病灶对比度和可探测性降低;二是出现“幻觉现象”,即引入不存在的病灶等虚假特征(Xia等人,2025)。这些局限会损害去噪图像的解剖学和代谢真实性,限制其在下游临床分析中的应用。为解决这些问题,已有多种方法将辅助语义先验作为正则化机制:例如,通过额外卷积层从配准后的磁共振(MR)或CT图像中提取语义特征,再通过特征拼接或注意力机制整合到PET去噪流程中(Fu等人,2024;Onishi等人,2021;Cui等人,2019);另有研究利用原始正弦图数据提取先验信息,以指导去噪过程(Zhang等人,2024)。但这些方法依赖于核心去噪任务之外的中间模块,且需从多模态输入中提取间接或隐含的语义线索。一种更直接的策略可能是利用器官、肿瘤标注等显式语义标签监督去噪过程,例如(Huang等人,2022;Xia等人,2024)将模型生成的语义标签纳入损失函数以实现训练正则化,但这些生成标签的准确性可能欠佳,反而可能给去噪过程引入偏差。 在深度学习PET图像分割领域,主要采用基于Unet的架构,且已在病灶分割(Leung等人,2024;Gatidis等人,2024)和器官分割(Shiyam Sundar等人,2022;Suganuma等人,2023)中开展研究。对于病灶分割,半监督迁移学习应用广泛(Leung等人,2024):利用带有完整标注的大型公开数据集(Gatidis等人,2022)进行预训练,再在标注不完整的本地数据集上微调;近年来,研究人员还利用DDPMs从含病灶图像生成无病灶图像,通过图像相减实现病灶检测(Ahamed等人,2024),同时也利用DDPMs合成含病灶图像(Hu等人,2024),作为分割网络训练的数据增强手段。对于器官分割,尽管多数模型(Shiyam Sundar等人,2022;Suganuma等人,2023)依赖PET-CT图像对作为输入,但近期研究表明,在无CT的PET扫描中实现多器官分割具有可行性(Liebgott等人,2021;Salimi等人,2022)——这些进展得益于深度学习在更大规模数据集上能力的提升。然而,上述所有PET分割模型(无论用于病灶还是器官分割)均依赖标准计数或高计数PET输入才能取得理想效果,据我们所知,目前尚无模型能在低计数噪声输入上有效发挥作用。 如图1所示,去噪和分割作为分析流程中天然关联的任务,在逻辑上存在协同作用:质量更高的去噪图像能提升病灶和器官的可见度与区分度,从而简化语义分割;反之,下游的病灶和器官掩码可从语义结构层面正则化去噪输出,为去噪提供直接且显式的支持。 近年来,多任务学习的理念已在多个领域得到积极探索,但尚未专门应用于PET去噪与分割任务。多任务学习通过促进任务间的信息共享,展现出优于传统单任务学习的性能。例如,已有研究开发多任务扩散框架(Ye和Xu,2024),用于联合处理分割、图像生成等多个场景相关的密集预测任务——该框架利用条件机制,整合多个辅助解码器的初始预测结果,以增强目标任务的学习过程;类似地,图像转换模型也采用语义或类别标签引导设计(Peng等人,2023;Li等人,2023;Xu等人,2023;Lim,2023),即通过分割或分类模型监督转换过程,而优化后的转换结果又能反过来提升分割或分类性能。尽管这些方法在各自领域取得了成功,但应用于PET分析时仍存在局限:它们主要针对2D图像处理设计,难以适配3D医学体数据(Ye和Xu,2024;Li等人,2023;Lim,2023);此外,为生成主任务先验而进行的辅助任务训练,往往与主任务训练独立开展(Ye和Xu,2024;Peng等人,2023),可能在了你先验生成过程中引入偏差;虽可采用迭代训练方法缓解偏差(Xu等人,2023),但会大幅增加训练复杂度。 综上,从临床角度来看,尽管已有众多针对低计数PET去噪和标准计数PET分割的方法,但这两个紧密关联的任务通常被独立处理,导致现有方法无法直接从低计数输入中自动获取TLG等重要临床指标。如图1所示,能够同时执行去噪和分割的统一模型为解决这一局限提供了可行方案——此类模型通过端到端自动处理,有望同时降低扫描成本和医师工作负担。从技术角度来看,尽管PET去噪与分割因共享语义特征而存在潜在协同效益,但相关探索仍严重不足;为其他成像任务设计的现有多任务学习模型应用于PET时,常因数据维度不匹配和跨任务交互设计局限而面临挑战。 在本研究中,我们提出一种创新的多任务框架,用于低计数PET成像中的联合去噪与分割,命名为结合解剖学和代谢信息的扩散模型(AMDiff)。研究贡献主要体现在三方面:(1)AMDiff可通过同时自动生成去噪图像及病灶、器官掩码,直接从低计数输入中实现临床指标的一步量化;(2)AMDiff充分挖掘任务间的协同作用——分割从语义结构层面引导去噪,去噪则为更稳健的分割提供支持;两个任务联合训练,可直接获取输入和标签,并通过预热机制互联,实现高效且准确的信息交换;(3)通过在多厂商、多中心、多噪声水平的数据集上开展全面实验,验证了AMDiff相较于当前最先进(SOTA)去噪与分割方法的有效性。
Aastract
摘要
Positron emission tomography (PET) image denoising, along with lesion and organ segmentation, are criticalsteps in PET-aided diagnosis. However, existing methods typically treat these tasks independently, overlookinginherent synergies between them as correlated steps in the analysis pipeline. In this work, we present theanatomically and metabolically informed diffusion (AMDiff) model, a unified framework for denoising andlesion/organ segmentation in low-count PET imaging. By integrating multi-task functionality and exploitingthe mutual benefits of these tasks, AMDiff enables direct quantification of clinical metrics, such as total lesionglycolysis (TLG), from low-count inputs. The AMDiff model incorporates a semantic-informed denoiser basedon diffusion strategy and a denoising-informed segmenter utilizing nnMamba architecture. The segmenterconstrains denoised outputs via a lesion-organ-specific regularizer, while the denoiser enhances the segmenterby providing enriched image information through a denoising revision module. These components areconnected via a warming-up mechanism to optimize multi-task interactions. Experiments on multi-vendor,multi-center, and multi-noise-level datasets demonstrate the superior performance of AMDiff. For test casesbelow 20% of the clinical count levels from participating sites, AMDiff achieves TLG quantification biasesof −21.60±47.26%, outperforming its ablated versions which yield biases of −30.83±59.11% (without thelesion-organ-specific regularizer) and −35.63±54.08% (without the denoising revision module). By leveragingits internal multi-task synergies, AMDiff surpasses standalone PET denoising and segmentation methods.Compared to the benchmark denoising diffusion model, AMDiff reduces the normalized root-mean-square errorfor lesion/liver by 22.92/17.27% on average. Compared to the benchmark nnMamba segmentation model,AMDiff improves lesion/liver Dice coefficients by 10.17/2.02% on average.
正电子发射断层显像(PET)图像去噪及病灶与器官分割 正电子发射断层显像(PET)图像去噪及病灶与器官分割是PET辅助诊断中的关键步骤。然而,现有方法通常将这些任务独立处理,忽视了它们作为分析流程中相互关联的步骤所具有的内在协同作用。在本研究中,我们提出了结合解剖学和代谢信息的扩散模型(AMDiff),这是一个用于低计数PET成像中去噪与病灶/器官分割的统一框架。通过整合多任务功能并利用这些任务间的相互优势,AMDiff能够直接从低计数输入中量化临床指标,例如总病灶糖酵解量(TLG)。 AMDiff模型包含一个基于扩散策略的语义引导去噪器,以及一个采用nnMamba架构的去噪引导分割器。分割器通过病灶-器官特异性正则化器约束去噪输出,而去噪器则通过去噪修正模块提供更丰富的图像信息,从而增强分割器性能。这些组件通过预热机制连接,以优化多任务间的交互。 在多厂商、多中心、多噪声水平的数据集上进行的实验表明,AMDiff具有优异性能。对于来自参与研究机构的、计数水平低于临床计数水平20%的测试案例,AMDiff实现的TLG量化偏差为-21.60±47.26%,优于其消融版本——无病灶-器官特异性正则化器的版本偏差为-30.83±59.11%,无去噪修正模块的版本偏差为-35.63±54.08%。 借助其内部多任务协同作用,AMDiff的性能超过了独立的PET去噪和分割方法。与基准去噪扩散模型相比,AMDiff对病灶/肝脏的归一化均方根误差平均降低了22.92%/17.27%;与基准nnMamba分割模型相比,AMDiff对病灶/肝脏的骰子相似系数(DSC)平均提升了10.17%/2.02%。
Method
方法
The framework of AMDiff is shown in Fig. 2. It comprises a semanticinformed denoiser and a denoising-informed segmenter. The denoiserreconstructs high-count images 𝐼𝐻𝐶 from low-count ones 𝐼𝐿𝐶. Thedenoising process is constrained by a lesion-organ-specific regularizer,which emphasizes anatomical and metabolic similarities of denoisedoutputs 𝑃𝐻𝐶 with references 𝐼𝐻𝐶. The segmenter inherits denoisedinformation 𝑃𝐻𝐶 via a revision function 𝑓𝑟𝑒𝑣(⋅) and generates completelesion and organ masks using a dual-branch architecture 𝑓𝑠𝑒𝑔 (⋅). Due tocomputational constraints, large PET images are divided into smaller3D patches for network processing and are reassembled afterward.Details of the AMDiff components are as below
AMDiff模型框架说明 AMDiff的框架如图2所示,由语义引导去噪器与去噪引导分割器两部分构成。其中,去噪器负责从低计数图像(I{LC})中重建高计数图像(I{HC}),其去噪过程受病灶-器官特异性正则化器约束——该正则化器会着重确保去噪输出(P{HC})与参考图像(I{HC})在解剖学和代谢特征上的相似性。 分割器则通过修正函数(f{rev}(\cdot))继承去噪信息(P{HC}),并借助双分支架构(f_{seg}(\cdot))生成完整的病灶与器官掩码。由于计算资源限制,处理时会先将大型PET图像分割为更小的3D块,待网络处理完成后再重新拼接。 下文将详细介绍AMDiff各组件的具体细节。
Conclusion
结论
We present AMDiff, a unified model for denoising and lesion/organsegmentation in low-count PET imaging. By simultaneously mappinglow-count images to high-count equivalents and generating lesion andorgan masks, AMDiff facilitates one-step clinical metric quantification,offering practical advantages. The model effectively leverages synergiesbetween denoising and segmentation tasks, as validated through extensive experiments. With the dual tasks mutually enhancing each other,AMDiff outperforms SOTA denoising and segmentation benchmarks.
AMDif模型核心贡献总结 本文提出了AMDiff模型,这是一种用于低计数PET成像中去噪与病灶/器官分割的统一模型。该模型可同时将低计数图像映射为等效高计数图像,并生成病灶与器官掩码,从而实现临床指标的一步量化,具备实际应用优势。 通过大量实验验证,该模型有效利用了去噪与分割任务间的协同作用。在两项任务的相互增强下,AMDiff的性能超过了当前最先进(SOTA)的去噪与分割基准模型。 要不要我帮你整理一份AMDiff模型核心亮点与实验结论的提炼文档,方便你快速梳理该研究的关键价值?
Results
结果
4.1. Denoising evaluations
The denoising performance of AMDiff was compared against representative denoising methods, including LeqMod-GAN (Xia et al., 2024),SpachTransformer (Jang et al., 2023), and Med-DDPM (Dorjsembeet al., 2024). All comparison models were re-trained on the localdatasets using their official implementations, with whole images divided into 3D patches of 128 × 128 × 128 voxels. For each method,the version that achieved the best performance on the validation setwas selected for final testing.Results are summarized in Table 2. Unlike the comparison models,which are limited to denoising functionality, the AMDiff integratessegmentation maps to regularize denoised outputs, demonstrating superior performance across multiple scanners. When averaged acrossall test cases from all scanners and noise levels, AMDiff achievedliver NRMSE reductions of 31.6%, 7.1%, and 17.3% compared toLeqMod, SpachTransformer, and Med-DDPM, respectively. For lesionregions, the corresponding reductions were 2.6%, 8.9%, and 22.9%. Inparticularly challenging cases with extremely low-count levels below5%, AMDiff delivered even greater improvements in lesion NRMSE,achieving reductions of 12.0%, 24.1%, and 32.5%.For visual comparisons, Fig. 4 presents sample denoised imagesgenerated by different models. Relative to high-count references, metods such as LeqMod-GAN, SpachTransformer, and Med-DDPM exhibitreduced lesion contrast and blurred anatomical boundaries, particularlyfor small lesions and bone structures. In contrast, AMDiff leverages bothanatomical and metabolic guidance to produce semantically coherentreconstructions that closely resemble high-count references, as highlighted by red arrows in Fig. 4. In certain cases, lesion characteristics inAMDiff-denoised images differ from those in high-count references andmay appear as hallucinations, as indicated by the yellow arrows. This islikely because similar features exhibit strong signals in the low-countinputs, causing the denoised images to preserve these characteristics.Nevertheless, these results remain superior to those produced by othercomparison models. There are also instances where small, faint lesionsare missed by all denoising methods, likely due to their extremely lowsignal and the challenge of distinguishing them from high noise inlow-count inputs, as indicated by the orange arrows in Fig. 4.
去噪性能评估 我们将AMDiff的去噪性能与代表性去噪方法进行了对比,包括LeqMod-GAN(Xia等人,2024)、SpachTransformer(Jang等人,2023)以及Med-DDPM(Dorjsembe等人,2024)。所有对比模型均使用其官方实现代码在本地数据集上重新训练,训练时将完整图像分割为128×128×128体素的3D块;对于每种方法,均选择在验证集上表现最佳的版本用于最终测试。 结果总结于表2中。与仅具备去噪功能的对比模型不同,AMDiff整合了分割掩码以正则化去噪输出,在多台扫描仪数据上均展现出更优性能。对所有扫描仪、所有噪声水平的测试案例取平均值后,与LeqMod、SpachTransformer、Med-DDPM相比,AMDiff对肝脏区域的归一化均方根误差(NRMSE)分别降低了31.6%、7.1%和17.3%;对病灶区域,对应的NRMSE降低幅度分别为2.6%、8.9%和22.9%。在计数水平低于5%的极富挑战性案例中,AMDiff对病灶NRMSE的改善效果更为显著,分别降低了12.0%、24.1%和32.5%。 为进行视觉对比,图4展示了不同模型生成的去噪图像样本。相较于高计数参考图像,LeqMod-GAN、SpachTransformer、Med-DDPM等方法的去噪结果存在病灶对比度降低、解剖边界模糊的问题,在小病灶和骨骼结构上表现尤为明显。与之相反,AMDiff借助解剖学和代谢信息的双重引导,生成的重建图像语义连贯性更强,与高计数参考图像高度接近(如图4中红色箭头所示)。在部分案例中,AMDiff去噪图像中的病灶特征与高计数参考图像存在差异,可能表现为“幻觉特征”(如图4中黄色箭头所示),这很可能是因为低计数输入中某些相似特征信号较强,导致去噪图像保留了这些特征。尽管如此,这些结果仍优于其他对比模型的表现。此外,还存在所有去噪方法均遗漏小型微弱病灶的情况(如图4中橙色箭头所示),这可能是由于这些病灶信号极弱,在低计数输入中难以与强噪声区分所致。
Figure
图
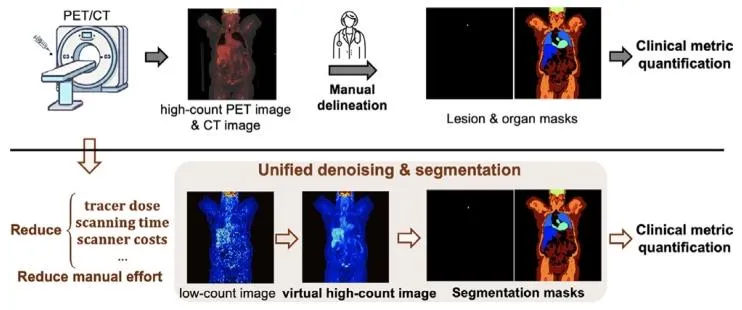
Fig. 1. Deep learning PET image analysis offers substantial benefits. This workinvestigates unified denoising and lesion and organ segmentation in low-countPET imaging while leveraging the synergies between these tasks.
图1:深度学习在PET图像分析中具有显著优势 本研究聚焦低计数PET成像中的联合去噪与病灶、器官分割任务,同时充分利用这些任务间的协同作用。

Fig. 2. Overview of the AMDiff model. It comprises a semantic-informed denoiser and a denoising-informed segmenter. The segmenter constrains the semanticstructures of denoised outputs using a lesion-organ-specific regularizer. Vice versa, the denoiser supports the segmenter by providing images with enhanced lesionvisibility and organ clarity via the denoising revision module
图2:AMDiff模型总览 该模型包含语义引导去噪器与去噪引导分割器两部分: 分割器通过病灶-器官特异性正则化器,约束去噪输出的语义结构; 反之,去噪器则通过去噪修正模块,提供病灶可见度提升、器官轮廓更清晰的图像,为分割器提供支持。

Fig. 3. The dual-branch segmenter architecture of the AMDiff model.
图3:AMDiff模型的双分支架构分割器
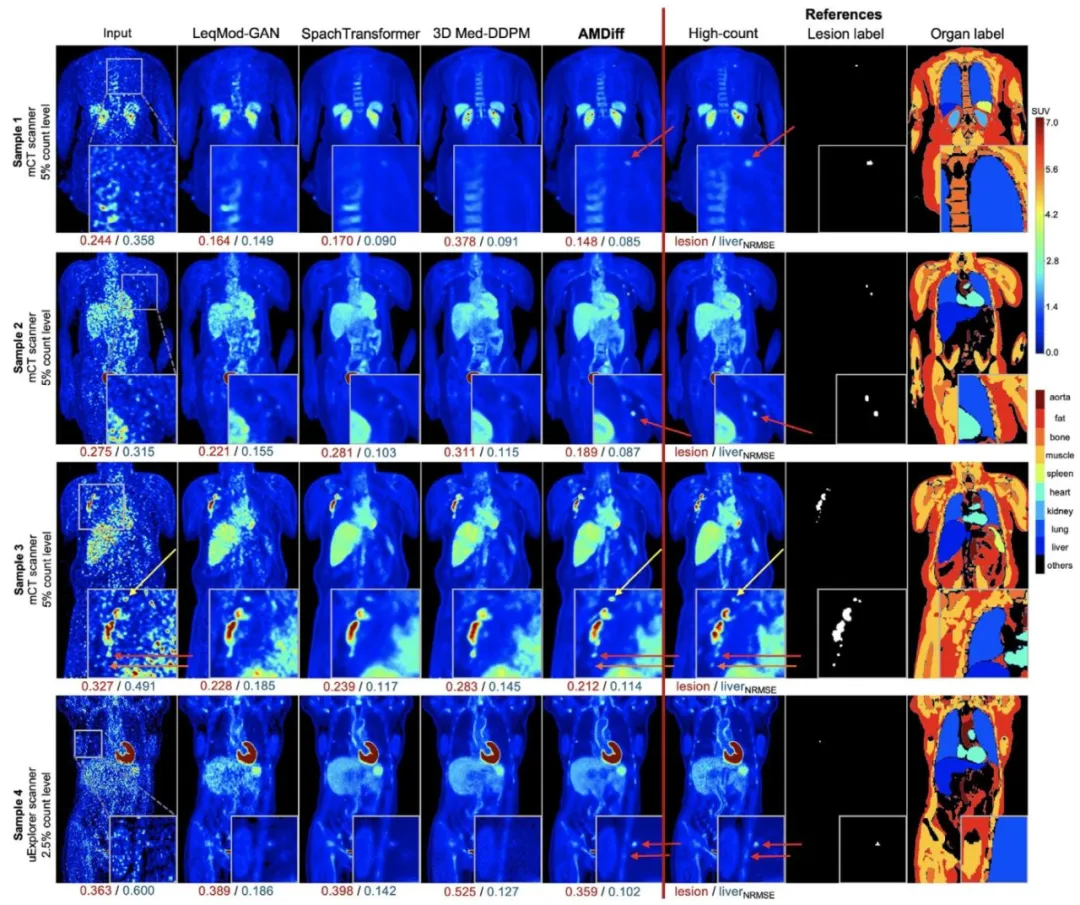
Fig. 4. Visual comparisons between AMDiff and other denoising models. NRMSE metrics for the lesion and liver are displayed below each image. ROIs are cropped,magnified, and shown in the bottom-right corner of each image. Red arrows highlight areas where lesions and organ structures in AMDiff-denoised results appearsuperior to those in comparison models and more closely resemble high-count references. Yellow arrows indicate lesions in AMDiff-denoised images that exhibitslight differences from high-count references but still outperform comparison models and remain consistent with their appearance in the input. Orange arrowsdenote small, weak lesions that are missed in all denoised outputs, likely due to their extremely faint signals and the challenge of distinguishing them from highnoise in low-count inputs.
图4:AMDiff与其他去噪模型的视觉对比 每张图像下方均标注了病灶和肝脏区域的归一化均方根误差(NRMSE)指标;感兴趣区域(ROIs)经裁剪、放大后,展示在每张图像的右下角。 - 红色箭头:标注AMDiff去噪结果中病灶及器官结构表现优于其他对比模型、且与高计数参考图像更接近的区域; - 黄色箭头:标注AMDiff去噪图像中与高计数参考图像存在细微差异,但仍优于对比模型、且与输入图像中病灶外观保持一致的区域; - 橙色箭头:标注所有去噪结果均遗漏的小型微弱病灶——此类病灶未被检测出,可能因其信号极弱,在低计数输入中难以与强噪声区分。

Fig. 5. Visual comparisons of AMDiff with other models for lesion segmentation. Dice coefficients are shown below each image. ROIs are cropped, magnified,and displayed in the bottom-right corner of each image
图5:AMDiff与其他模型在病灶分割任务中的视觉对比 每张图像下方均标注了骰子相似系数(Dice);感兴趣区域(ROIs)经裁剪、放大后,展示在每张图像的右下角。

Fig. 6. Visual comparisons of AMDiff with other models for organ segmentation. Dice coefficients for organs are shown below each image. ROIs are cropped,magnified, and displayed in the bottom-right corner of each image.
图6:AMDiff与其他模型在器官分割任务中的视觉对比 每张图像下方均标注了各器官的骰子相似系数(Dice);感兴趣区域(ROIs)经裁剪、放大后,展示在每张图像的右下角。

Fig. 7. Linear regression analysis on clinical metric quantification, includingMTV, TLG, and organ SUVmean, taking the liver and aorta as examples.
图7:临床指标量化结果的线性回归分析 分析指标包括代谢肿瘤体积(MTV)、总病灶糖酵解量(TLG)以及器官平均标准化摄取值(SUVmean),并以肝脏和主动脉为示例进行展示。
Table
表

Table 1Details of used datasets.
表1:所用数据集的详细信息
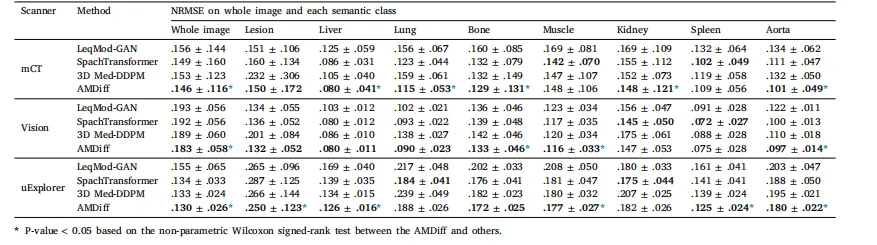
Table 2Denoising comparisons with SOTA methods. Metrics are averaged across all noise levels and presented as mean ± std. A lower value is preferred, with the bestresult in each case highlighted in bold
表2:与当前最先进(SOTA)方法的去噪性能对比 所有指标均为不同噪声水平下的平均值,以“均值±标准差”形式呈现;指标数值越小越好,各组最佳结果以粗体标注。
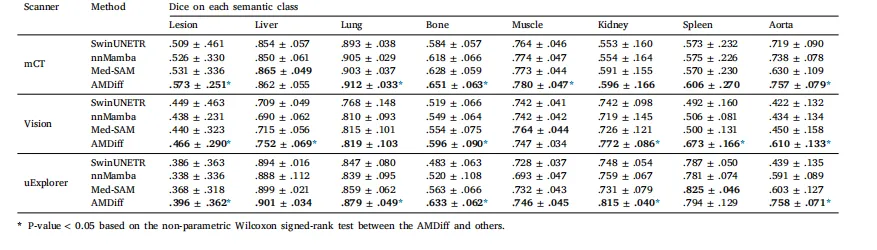
Table 3Segmentation comparisons with SOTA methods. Inputs to the comparison segmentation models are concatenation of low-count images and denoised ones obtainedby the conditioned diffusion module architecture used in AMDiff. Metrics are averaged across all noise levels and presented as mean ± std. Higher Dice scoresare preferred, with the best result in each case highlighted in bold.
表3:与当前最先进(SOTA)方法的分割性能对比 对比分割模型的输入为“低计数图像”与“AMDiff所用条件扩散模块生成的去噪图像”的拼接结果。所有指标均为不同噪声水平下的平均值,以“均值±标准差”形式呈现;骰子相似系数(Dice)数值越高越好,各组最佳结果以粗体标注。

Table 4Ablation studies on the AMDiff. Metrics are averaged across all test cases and are presented as mean ± std. Lower NRMSE values and higher Dice scores indicatebetter performance. The best result for each case is highlighted in bold.
表4:AMDiff模型的消融实验结果 所有指标均为所有测试案例的平均值,以“均值±标准差”形式呈现。归一化均方根误差(NRMSE)数值越小越好,骰子相似系数(Dice)数值越高越好,各组最佳结果以粗体标注。