Title
题目
Template-based semantic-guided orthodontic teeth alignment previewer
基于模板的语义引导式正畸牙齿排列预览器
01
文献速递介绍
正畸治疗及牙齿排列预测研究进展 正畸治疗旨在改善牙齿与颌骨的排列及位置,以实现最佳的口腔健康、功能与美观。该治疗需运用牙套、隐形矫治器等多种器械与技术,逐步将牙齿移动至理想位置,并矫正牙齿与颌骨排列不齐的问题——若不及时干预,这类问题可能引发多种口腔健康隐患。治疗时长取决于正畸问题的严重程度及所选治疗方案,平均从数月到数年不等(Mavreas & Athanasiou, 2008)。 对于漫长的治疗过程,缓解正畸患者的顾虑、帮助其保持治疗动力与积极心态至关重要。保持清晰沟通、设定合理预期、定期更新治疗进展等策略,均能有效减轻患者担忧。因此,预测正畸治疗后的牙齿排列情况,并将结果转化为直观可见的美观笑容可视化图像,不仅可帮助患者决定是否接受治疗,还能让其更好地理解治疗方案。牙齿排列预测工具还可作为医生优化治疗方案的辅助手段,提升其临床应用价值;此外,可视化牙齿排列预测在面部美容软件中也具有巨大应用潜力。 近年来,正畸治疗后笑容图像的预测研究备受关注。Yang等人(Lingchen et al., 2020)设计了一套复杂框架,包含三个独立的深度神经网络,分别用于从笑容图像中提取牙齿轮廓、构建三维牙齿模型,以及生成治疗后的牙齿排列图像。但该框架需同时输入正面笑容图像及通过口腔扫描获取的对应牙齿不齐三维模型,普通用户获取这类数据存在一定难度。 相比之下,Chen等人(2022)提出了另一种方法:将StyleGAN生成器与 latent空间编辑方法结合,借助GAN逆变换技术,仅通过单张输入图像即可确定牙齿排列整齐后的最佳外观。该方法虽仅依赖正面图像,且在图像空间内对牙齿结构与外观进行隐式调整,但存在过度估计治疗效果的可能,生成的视觉结果或与实际情况存在偏差。 在我们此前的研究中(Chen & Chen, 2023),我们提出了一种基于语义引导的模型方法,可通过单张正面笑容照片预测并可视化正畸治疗后的牙齿排列。具体而言,该方法包含三个核心部分:(1)引入区域-边界特征融合模块,提升二维牙齿语义分割效果;(2)利用统计先验知识,从单张正面笑容照片提取的牙齿语义边界中重建三维牙齿模型;(3)结合正畸模拟算法与语义引导图像生成框架,实现治疗后牙齿外观的真实可视化。与Lingchen等人(2020)及Chen等人(2022)的研究相比,我们的方法在保证治疗效果真实性的同时,提升了方法的实用性与可及性。但在牙齿结构控制方面,基于pSpGAN将图像分解为风格与结构正交表示的方式,有时无法准确反映牙齿排列情况(牙齿间隙较大的案例中该问题尤为明显);此外,此前方法生成的图像难以还原原始图像中每颗牙齿对应的局部纹理细节。因此,我们在牙齿结构控制与纹理迁移方面进行了进一步改进。 我们关于语义引导正畸模拟预测工作框架的初步研究已发表于MICCAI 2023(Chen & Chen, 2023)。在本文中,我们对原有研究进行了大幅改进与拓展,提出一种基于扩散模型的语义引导正畸预测框架——无需依赖三维牙齿模型,即可实现当前最先进的正畸效果预测。主要贡献如下:(1)在扩散模型中引入新型语义引导机制,实现对牙齿排列的精准结构控制;(2)提出自适应纹理迁移策略,有效保留对应牙齿的表面细节,克服基于模板方法的形态失真问题,提升预测图像的真实感;(3)首创双优化框架,将结构控制与纹理生成解耦,同时提升牙齿排列精度与视觉真实度。该创新策略有效解决了传统GAN方法在牙齿预测中面临的长期挑战——即风格与结构的纠缠处理限制了临床可控性。此外,我们对框架中各组件均提供了可视化展示,并首次建立了正畸预测结果与实际治疗效果间的定量关联,进一步验证了本方法的临床相关性。
Aastract
摘要
Intuitive visualization of orthodontic prediction results is of great significance in helping patients make up theirminds about orthodontics and maintain an optimistic attitude during treatment. To address this, we proposea semantically guided orthodontic simulation prediction framework that predicts orthodontic outcomes usingonly a frontal photograph. Our method comprises four key steps. Firstly, we perform semantic segmentation oforal and the teeth cavity, enabling the extraction of category-specific tooth contours from frontal images withmisaligned teeth. Secondly, these extracted contours are employed to adapt the predefined teeth templatesto reconstruct 3D models of the teeth. Thirdly, using the reconstructed tooth positions, sizes, and postures,we fit the dental arch curve to guide tooth movement, producing a 3D model of the teeth after simulatedorthodontic adjustments. Ultimately, we apply a semantically guided diffusion model for structural control andgenerate orthodontic prediction images which are consistent with the style of input images by applying texturetransformation. Notably, our tooth semantic segmentation model attains an average intersection of union of0.834 for 24 tooth classes excluding the second and third molars. The average Chamfer distance betweenour reconstructed teeth models and their corresponding ground-truth counterparts measures at 1.272 mm2 intest cases. The teeth alignment, as predicted by our approach, exhibits a high degree of consistency with theactual post-orthodontic results in frontal images. This comprehensive qualitative and quantitative evaluationindicates the practicality and effectiveness of our framework in orthodontics and facial beautification
正畸预测结果的直观可视化研究 正畸预测结果的直观可视化对于帮助患者下定决心接受正畸治疗、并在治疗期间保持积极心态具有重要意义。为此,我们提出一种语义引导的正畸模拟预测框架,仅通过正面照片即可预测正畸效果。该方法包含四个关键步骤: 首先,对口腔及牙腔区域进行语义分割,从牙齿排列不齐的正面图像中提取出特定类别的牙齿轮廓。其次,利用提取的轮廓对预定义牙齿模板进行适配,重建牙齿的三维模型。第三,基于重建得到的牙齿位置、尺寸与姿态,拟合牙弓曲线以引导牙齿移动,生成模拟正畸调整后的牙齿三维模型。最后,采用语义引导的扩散模型进行结构控制,并通过纹理转换生成与输入图像风格一致的正畸预测图像。 值得注意的是,在排除第二磨牙和第三磨牙的24个牙齿类别中,我们的牙齿语义分割模型平均交并比(IoU)达到0.834;在测试案例中,重建牙齿模型与对应真实模型的平均香农距离(Chamfer Distance)为1.272 mm²;且本方法预测的牙齿排列与正面图像中实际正畸后的结果具有高度一致性。这种全面的定性与定量评估表明,该框架在正畸治疗及面部美容领域具有实用性与有效性。
Method
方法
The core concept of our method is conditional image generation,specifically, generating a post-treatment frontal photograph based onthe input pre-treatment frontal smiling photograph and the tooth semantic segmentation maps representing post-treatment teeth alignmentfrom the same viewpoint. The pre-treatment frontal photograph can beeasily obtained from a patient’s selfie and the expected post-treatmentaligned teeth models can be computed from the pre-treatment unaligned ones through a series of 3D rigid transformations leveragingthe automated orthodontic tooth arrangement algorithm. This resulting model’s projection can serve as the segmentation maps to guidethe final image generation. Consequently, our method comprises fourcomponents: tooth and mouth cavity segmentation in frontal images,statistical shape modeling of human teeth and template-based 3D teethreconstruction, orthodontic treatment simulation, and semantic-guidedimage generation incorporating predicted teeth alignment. Fig. 1 describes our method’s workflow in details and Fig. 2 illustrates theoutputs at each stage of the framework.
本方法核心概念与框架构成 本方法的核心概念是条件图像生成,具体而言,即基于输入的治疗前正面笑容照片,以及从同一视角呈现治疗后牙齿排列的牙齿语义分割图,生成治疗后的正面照片。 其中,治疗前正面照片可通过患者自拍轻松获取;而预期的治疗后牙齿排列整齐模型,则可利用自动化正畸牙齿排列算法,通过一系列三维刚性变换,由治疗前牙齿排列不齐的模型计算得出。该模型的投影结果可作为分割图,用于指导最终的图像生成。 因此,本方法包含四个核心组件:正面图像中的牙齿与口腔区域分割、人类牙齿的统计形状建模与基于模板的三维牙齿重建、正畸治疗模拟,以及融合预测牙齿排列的语义引导图像生成。图1详细展示了本方法的工作流程,图2则呈现了该框架各阶段的输出结果。
Conclusion
结论
In summary, we develop a framework to predict teeth alignmentand the resulting frontal visual appearance after orthodontic treatment.Within this framework, we introduce a region-boundary feature fusionmodule aimed at enhancing the precision of semantic tooth segmentation, conduct 3D teeth reconstruction from single frontal images usinga pre-established parametric teeth template, run orthodontic treatmentsimulations to refine teeth alignment, and generate post-orthodonticvisual outcomes in a frontal image format. Quantitative analyses werecarried out to evaluate the accuracy of tooth segmentation and 3Dteeth reconstruction. Through qualitative analysis, the superiority ofthe method of diffusion model based on structure control combinedwith texture transformer over the style-structure-disentangled imagegeneration mode is demonstrated. Additional testing, which includescomparisons with actual post-orthodontic outcomes, was conducted tovalidate the robustness and authenticity of the proposed framework.The experimental results demonstrate the direct applicability of ourmethod for post-orthodontic visual outcome prediction.
研究总结 综上,我们开发了一个用于预测正畸治疗后牙齿排列及正面视觉外观的框架。 在该框架中,我们引入区域-边界特征融合模块以提升牙齿语义分割精度;利用预构建的参数化牙齿模板,从单张正面图像中重建三维牙齿模型;通过正畸治疗模拟优化牙齿排列;并以正面图像形式生成正畸后的视觉效果。 我们通过定量分析评估了牙齿分割与三维牙齿重建的精度;通过定性分析,验证了基于结构控制的扩散模型结合纹理转换器的方法,相较于风格-结构解耦的图像生成模式所具备的优势。此外,我们还通过与实际正畸治疗结果对比等额外测试,验证了所提框架的稳健性与真实性。 实验结果表明,本方法可直接应用于正畸后视觉效果预测。 要不要我帮你将这段总结提炼成核心要点清单,方便快速抓取研究目的、方法、验证方式与结论?
Results
结果
4.1. Data sets and implementation details
We collected 225 digital dental scans with annotated teeth and theirintra-oral photos, as well as 5610 frontal intra-oral images, of which3300 were labeled, and 4330 frontal smiling photographs, of which2000 were labeled. These data were sourced from our collaboratinghospitals. The digital dental scans were divided into two groups, 130scans for building morphable shape models and tooth-row templatesand the remaining 95 scans for 3D teeth reconstruction evaluation.Every tooth within the scanned mesh has been accurately identifiedand labeled at the vertex level, and extended to form a hull with theinvisible tooth root being omitted. The labeled 3300 intra-oral imagesand 2000 smiling images were randomly split into training (90%) andlabeled test (10%) datasets. The segmentation accuracy was assessedon the labeled test data, and the synthetic image quality was evaluatedon the unlabeled test data.All models were trained and evaluated using an NVIDIA GeForceRTX 3090 GPU. The segmentation models underwent 100 epochs oftraining, employing a batch size of 4. The training was started fromscratch and the learning rate was set to 10−4 . Models were savedbased on minimal loss observed on the labeled test data. In the inference stage, our method exhibits an average execution time of roughly15 s per case, with the 3D reconstruction phase constituting the mosttime-consuming aspect, taking approximately 12 s. All inference computations were exclusively performed on an Intel 12700H CPU.
4.1 数据集与实现细节 我们收集了225份带牙齿标注的数字化口腔扫描数据及其口内照片、5610张正面口内图像(其中3300张带有标注),以及4330张正面笑容照片(其中2000张带有标注),所有数据均来源于合作医院。 数字化口腔扫描数据分为两组:130份用于构建可变形形状模型与牙列模板,剩余95份用于三维牙齿重建效果评估。扫描网格中的每颗牙齿均在顶点级别完成精准识别与标注,并扩展为外壳结构(未包含不可见的牙根部分)。 带有标注的3300张口内图像与2000张笑容图像被随机划分为训练集(90%)与带标注测试集(10%)。分割精度基于带标注测试集进行评估,合成图像质量则在无标注测试集上开展评估。 所有模型的训练与评估均使用NVIDIA GeForce RTX 3090显卡。分割模型训练总轮次为100轮,批大小设为4,采用从头训练模式,学习率设定为10⁻⁴;模型保存依据带标注测试集上的最小损失值确定。 推理阶段,本方法单案例平均执行时间约为15秒,其中三维重建阶段耗时最长,约占12秒;所有推理计算均仅在Intel 12700H CPU上完成。
Figure
图
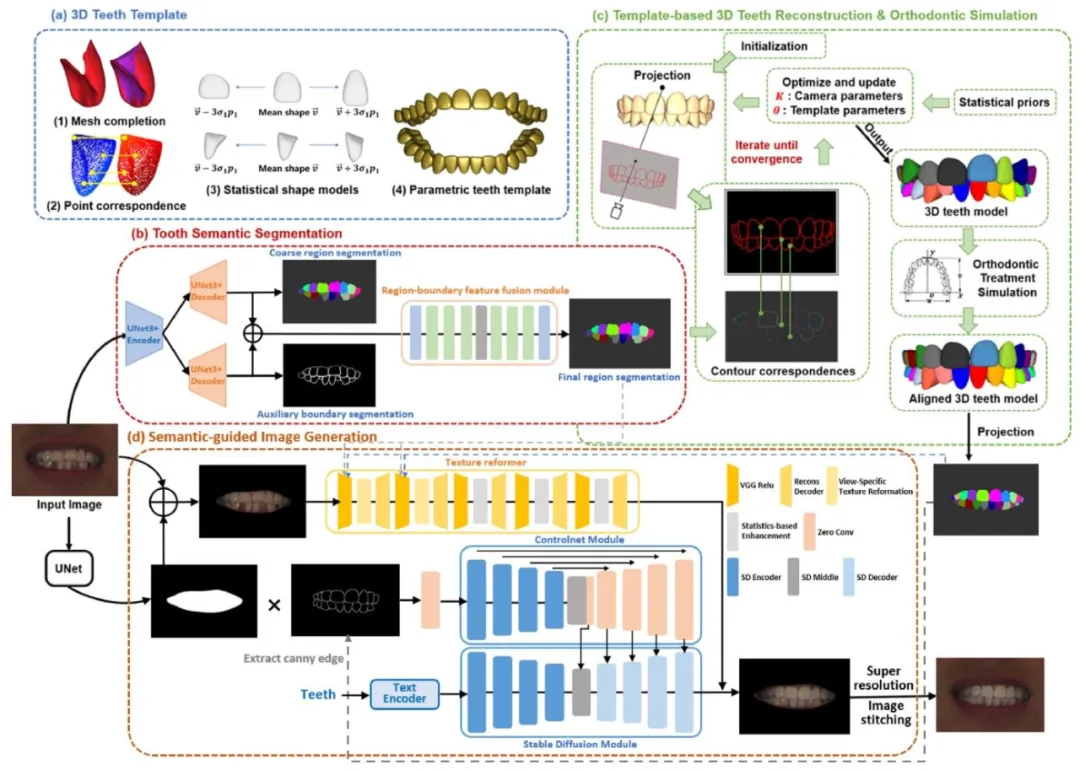
Fig. 1. The workflow of the orthodontic teeth alignment previewer that predicts the visual results of orthodontic treatment based on single frontal photographs.(a) The 3D teeth template is an ensemble of statistical shape models of human teeth, encompassing the probability distributions for tooth poses and scales. (b)The tooth semantic segmentation model is composed of a dual-branch U-Net3+ model that conducts coarse tooth semantic segmentation and binary contoursegmentation, and a region-boundary feature fusion module that outputs the refined tooth semantic segmentation. © Template-based 3D teeth reconstructionis executed by deforming the parametric teeth template to align its projected tooth contours with the predicted contours obtained through tooth semanticsegmentation. The orthodontic simulation is guided by displacing the fiducial landmarks towards their desired positions in the approximated dental arch andcorrecting the orientation of each tooth. (d) The semantic-guided image generation model utilizes Stable Diffusion controlled by the ControlNet connected to theencoder blocks and middle block (Zhang and Agrawala, 2023), to generate tooth images with the same structure as the tooth semantic segmentation map. Itemploys a texture reformer to migrate the original image texture through five stages of texture reformation and enhancement (Wang et al., 2022). This processrecombines structural and style features to produce the visual representation of improved teeth alignment. The style features are derived from the mouth area ofthe input image, while structural information is obtained from the mouth cavity mask and the tooth segmentation map generated by projecting the aligned 3Dteeth model
图1:基于单张正面照片预测正畸治疗视觉效果的牙齿排列预览器工作流程 (a)三维牙齿模板是人类牙齿统计形状模型的集合,包含牙齿姿态与尺寸的概率分布。 (b)牙齿语义分割模型由双分支U-Net3+模型和区域-边界特征融合模块构成:双分支U-Net3+模型负责执行牙齿粗语义分割与二值轮廓分割,区域-边界特征融合模块则输出精细化的牙齿语义分割结果。 (c)基于模板的三维牙齿重建通过以下方式实现:对参数化牙齿模板进行变形,使其投影的牙齿轮廓与牙齿语义分割得到的预测轮廓对齐。正畸模拟的实现过程为:将基准标志点朝近似牙弓中的目标位置移动,并校正每颗牙齿的朝向,以此为引导完成模拟。 (d)语义引导图像生成模型采用稳定扩散(Stable Diffusion)技术,通过连接编码器块与中间块的ControlNet(Zhang & Agrawala, 2023)进行控制,生成与牙齿语义分割图结构一致的牙齿图像。该模型利用纹理重构器,通过五个阶段的纹理重构与增强(Wang et al., 2022)迁移原始图像纹理——此过程将结构特征与风格特征重新组合,生成牙齿排列改善后的视觉效果。其中,风格特征来源于输入图像的口腔区域,结构信息则取自口腔掩模及对齐后的三维牙齿模型投影生成的牙齿分割图。

Fig. 2. Visualization of the intermediate results within the generative framework, presented from left to right: input mouth image, predicted toothsemantic segmentation map, projection of the reconstructed 3D teeth model,segmentation maps depicting aligned teeth from orthodontic simulation, andsynthetic mouth image with the predicted teeth alignment.
图2:生成框架中中间结果的可视化展示 从左至右依次为:输入口腔图像、预测的牙齿语义分割图、重建的三维牙齿模型投影图、呈现正畸模拟后牙齿排列整齐效果的分割图,以及包含预测牙齿排列效果的合成口腔图像。
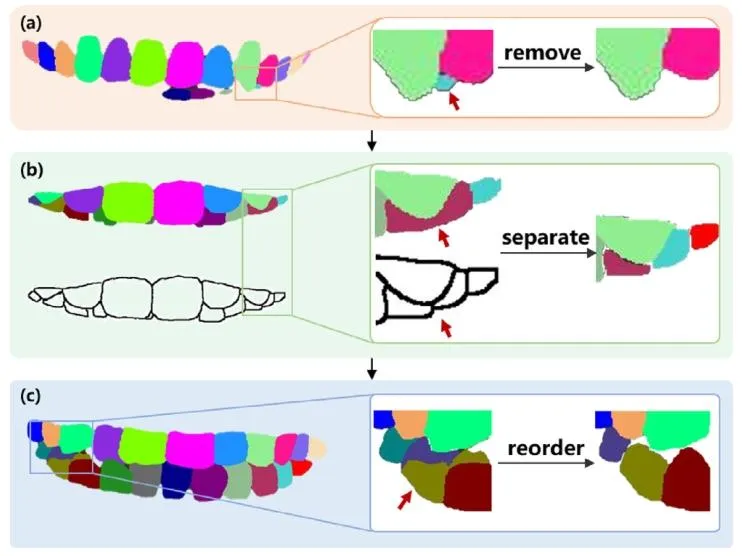
Fig. 3. The workflow of the heuristic post-processing algorithm. For eachtooth segmentation map, we process the region corresponding to each toothnumber in turn from the middle incisors to the third molar. (a) For each toothnumber, extract the largest connected region in the semantic segmentationgraph. When the max connected area’s pixel count is less than 8% of theaverage pixel count for that tooth number in all tooth semantic segmentationmap, ignore the segmentation of that tooth number. (b) When the toothsegmentation map is inconsistent with the boundary map, use contours to splitit into two separate areas and assign adjacent and different tooth numbers tothe two regions. © After the first two steps have been completed in the areacorresponding to each tooth number, use the tooth number with the highestnumber of pixels in each region to standardize the labeling of all pixels in thatregion.
图3:启发式后处理算法工作流程 针对每张牙齿分割图,从中切牙到第三磨牙,依次处理每个牙位编号对应的区域,具体步骤如下: (a)对于每个牙位编号,提取语义分割图中最大的连通区域。若该最大连通区域的像素数量小于所有牙齿语义分割图中该牙位编号平均像素数量的8%,则忽略该牙位编号的分割结果。 (b)当牙齿分割图与边界图不一致时,利用轮廓将其分割为两个独立区域,并为这两个区域分配相邻且不同的牙位编号。 (c)在完成前两步对每个牙位编号对应区域的处理后,针对每个区域,采用该区域内像素数量最多的牙位编号,对该区域内所有像素的标记进行标准化处理。

Fig. 4. Visualization depicting the impact of the segmentation post-processingalgorithm. This algorithm effectively rectifies misclassified tooth segmentationregions by leveraging information extracted from the binary tooth contours.
图4:分割后处理算法效果可视化 该算法通过利用从牙齿二值轮廓中提取的信息,有效修正了牙齿分割区域的误分类问题。

Fig. 5. Comparison of the orthodontic treatment outcome predictions generated by different models: TSynNet (Lingchen et al., 2020), contour-guidedpSpGAN (Chen and Chen, 2023), semantic-guided pSpGAN (Chen and Chen,2023), multi-condition latent diffusion model (Osuala et al., 2024) and ourmethod
图5:不同模型生成的正畸治疗效果预测结果对比 对比模型包括:TSynNet(Lingchen等人,2020)、轮廓引导pSpGAN(Chen与Chen,2023)、语义引导pSpGAN(Chen与Chen,2023)、多条件 latent 扩散模型(Osuala等人,2024),以及本研究提出的方法。
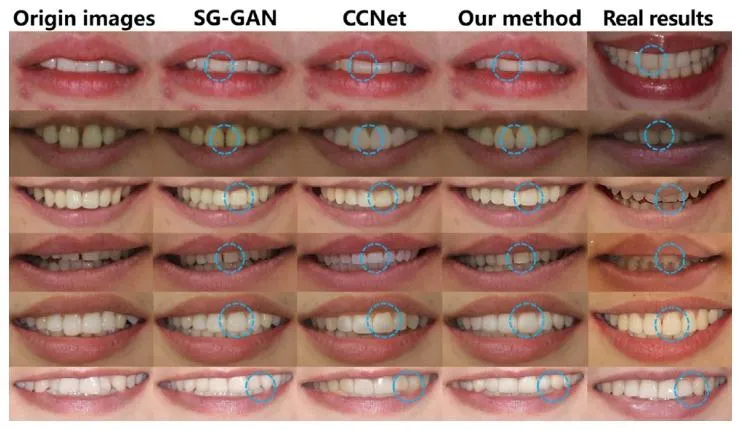
Fig. 6. From left to right are the positive smiling photos before orthodontic treatment, the visual results predicted based on semantic-guidedpSpGAN (Chen and Chen, 2023), the visual results predicted based on multicondition latent diffusion model (Osuala et al., 2024), the visual resultspredicted based on diffusion model, and the photos after orthodontic treatment(real visual results), showing the comparison between different orthodonticcases
图6:正畸治疗效果对比展示 从左至右依次为:正畸治疗前的正面笑容照片、基于语义引导pSpGAN的预测视觉效果(Chen与Chen,2023)、基于多条件潜在扩散模型的预测视觉效果(Osuala等人,2024)、基于(本研究)扩散模型的预测视觉效果,以及正畸治疗后的照片(真实视觉效果),呈现了不同正畸案例的效果对比。 要不要我帮你提炼该图的核心对比维度(如“真实度”“牙齿排列贴合度”),整理成一份视觉对比分析表,方便快速梳理不同模型的预测表现?

Fig. 7. Predicted teeth alignment in frontal smiling images from the Flickr-Faces-HQ datasets: original input images with misaligned teeth (left), synthetic imageswith predicted teeth alignment by semantic-guided pSpGAN (Chen and Chen, 2023) (middle), synthetic images with predicted teeth alignment by our method(right)
图7:Flickr-Faces-HQ数据集正面笑容图像中的牙齿排列预测结果 从左至右依次为:牙齿排列不齐的原始输入图像、基于语义引导pSpGAN生成的牙齿排列预测合成图像(Chen与Chen,2023)、基于本方法生成的牙齿排列预测合成图像。
Table
表
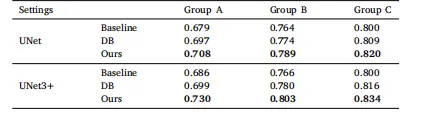
Table 1Segmentation accuracy on the test data, quantified by the mean Intersection ofUnion (mIoU), is presented for various tooth label groups and models, whereDB denotes Dual-Branch and Ours denotes Region-Boundary Feature Fusionmodule. Group A encompasses 32 tooth classes, Group B comprises 28 classes,excluding the third molars, and Group C consists of 24 classes, excluding thesecond and third molars.
表1:测试数据上的分割精度(以平均交并比mIoU量化) 该表展示了不同牙齿标签组与不同模型的分割精度,其中“DB”代表双分支模型(Dual-Branch),“Ours”代表本研究提出的区域-边界特征融合模块(Region-Boundary Feature Fusion module)。 各标签组定义如下: - A组:包含32个牙齿类别 - B组:包含28个牙齿类别,排除第三磨牙 - C组:包含24个牙齿类别,排除第二磨牙与第三磨牙
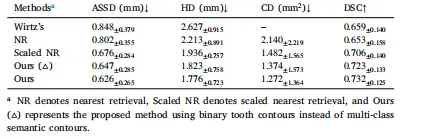
Table 2Teeth reconstruction accuracy (avg.± std.) on all the teeth of the 95 testcases (ASSD: average symmetric surface distance, HD: Hausdorff distance, CD:Chamfer distance, DSC: Dice similarity coefficient).
表2:95个测试案例中所有牙齿的重建精度(平均值±标准差) (注:ASSD=平均对称表面距离,HD=豪斯多夫距离,CD=香农距离,DSC=骰子相似系数)

Table 3Average Fréchet Inception Distance (FID) for different generators on 3500 testcases of dental images.
表3:3500个口腔图像测试案例中不同生成器的平均弗雷歇 inception 距离(FID) (注:FID即Fréchet Inception Distance,是衡量生成图像与真实图像相似度的常用指标,数值越低表示生成图像质量越接近真实图像)

Table 4Average authenticity scores of participants in both groups for natural imagesand images generated by different methods.
表4:两组参与者对自然图像及不同方法生成图像的平均真实性评分
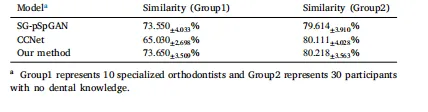
Table 5Quantitative assessment of similarity between predicted orthodontic outcomesand real orthodontic treatment outcomes
表5:正畸预测结果与实际正畸治疗结果的相似度定量评估