Title
题目
Ultrasound Report Generation WithCross-Modality Feature Alignmentvia Unsupervised Guidance
基于无监督引导的跨模态特征对齐超声报告生成
01
文献速递介绍
医学影像与自动报告生成研究背景及本文方法 医学影像能够对人体内部器官、组织及结构进行无创、实时的可视化呈现,在现代医疗诊断及潜在疾病排查中发挥着关键作用[1]。然而,解读医学影像并撰写报告的过程耗时耗力、对专业知识要求高且依赖人工操作,给临床医生带来了沉重负担。随着医学影像规模的持续扩大,放射科医生与超声科医生难以满足日益增长的患者需求,这可能导致诊断与治疗延误。因此,开发自动医学报告生成算法以辅助医生撰写报告,已变得愈发重要。 图像描述(image captioning)技术的成功为医学报告生成奠定了坚实基础,启发研究人员探索采用类似架构实现医学报告自动生成的可能性。当前主流的报告生成方法基于编码器-解码器结构[2]:利用卷积神经网络(CNN)[3]从医学影像中提取视觉特征,再通过循环神经网络(RNN)[4]基于提取的特征生成描述性文本。但由于医学影像与自然图像存在显著差异,在实现视觉与文本特征对齐时,医学影像面临独特挑战。与自然图像不同,医学影像的视觉特征往往较为相似,非专业人员难以区分其中的细微差异;此外,医学报告通常篇幅更长、内容更详尽,需描述不同身体组织的复杂观测结果,这导致影像与文本在特征多样性上存在明显不匹配。 为解决由此引发的性能下降问题,研究人员探索了多种方法以改进编码器-解码器结构的性能。部分方法通过添加带标注的疾病标签[5]-[6]辅助训练过程,另有一些方法[7]-[8]则将医学报告的子标题作为额外的影像标签形式,以更好地区分视觉特征。借助这些先验知识,编码器-解码器结构能够更有效地捕捉影像与文本间的复杂关联,提升视觉与文本表征的对齐性能。尽管[5]-[8]等方法在报告生成任务中展现出良好效果,但需注意的是,这些方法需要额外的标注数据,且并非适用于所有类型的数据集,而添加这些标注的过程会给临床医生带来额外负担。 此外,现有医学报告生成领域的多数研究[5]-[10]聚焦于放射科报告,这主要得益于IU-Xray[11]、MIMIC-CXR[12]等知名公开数据集的可获取性。与之形成对比的是,尽管超声是临床中应用更广泛、更安全的疾病筛查工具,但针对超声报告生成的研究仍相对有限。由图1可知,超声报告生成与放射科报告生成在图像和文本层面均存在差异:超声图像具有对比度低、存在伪影等显著特征,这为准确提取用于文本描述的相关视觉特征带来挑战;反之,超声报告通常比放射科报告更长、更详细,往往包含对器官、病灶、组织的全面描述,增加了文本生成过程的复杂性。此外,当前超声领域的相关方法多聚焦于描述生成[13],这类任务类似图像描述,旨在生成简短说明以用于教学。因此,迫切需要进一步研究以开发有效的超声报告生成策略,攻克上述难题。 本文提出一种结合无监督与有监督学习方法的新型报告生成框架,用于实现视觉与文本特征的对齐。该方法的设计灵感源于医生的学习与书写过程:通过无监督学习从文本报告中提取潜在知识,这一过程类似医生从病历中获取知识;借助从文本中提取的潜在知识,可为视觉提取器提供引导,使其学习与文本相关的视觉特征。该方法无需专家提供额外的疾病标签,即可弥合视觉与文本模态间的差距,在多数数据集上更易获取且效率更高。 为提升模型学习冗长复杂医学报告全局语义的能力,本文设计了相似性对比机制,以助力模型生成更准确、更长的报告。在训练过程中,该方法通过计算预测报告与真实报告(ground truth)的整体相似度,捕捉文本报告的全局语义,最终生成与真实报告高度契合、更准确全面的输出结果。 此外,为验证所提方法的有效性,本文构建了三个独立的超声数据集,分别针对乳腺、甲状腺、肝脏三种不同器官。数据收集已通过机构审查委员会批准(批准号:YSB-2020-Y0902)。 综上,本文的主要贡献总结如下: 1. 提出一种结合无监督与有监督学习的新型框架,无需额外疾病标签即可从文本报告中提取潜在医学知识。该方法旨在实现视觉与文本特征的对齐,从而缓解医学报告生成过程中的视觉-文本模态差距。 2. 所提框架通过采用相似性对比机制生成冗长且准确的报告。该方法结合全局语义信息生成复杂句子,相较于其他方法,能生成信息更丰富、准确性更高的报告。 3. 收集了三个大型独立超声图像-文本数据集,涵盖乳腺、甲状腺、肝脏领域。具体而言,乳腺数据集包含3521名患者,甲状腺数据集包含2474名患者,肝脏数据集包含1395名患者。据我们所知,本研究是首个在多器官超声报告数据集上进行评估与测试的工作。 本文工作是我们此前会议论文[14]的重要扩展,并提供了多项关键贡献:首先,优化了框架中“知识提取器”(Knowledge Distiller)的每一步流程,使其更适配超声报告生成任务,最终取得极具竞争力的结果;其次,在三个不同器官的大型超声报告数据集上验证了所提方法,体现其泛化能力;再次,在每个数据集上均与当前主流方法进行了全面对比,证明了所提框架的优越性能;最后,对实验结果进行了深入讨论,阐明了所提方法的优势与局限性。
Aastract
摘要
Automatic report generation has arisen asa significant research area in computer-aided diagnosis,aiming to alleviate the burden on clinicians by generatingreports automatically based on medical images. In thiswork, we propose a novel framework for automatic ultrasound report generation, leveraging a combination ofunsupervised and supervised learning methods to aid thereport generation process. Our framework incorporatesunsupervised learning methods to extract potential knowledge from ultrasound text reports, serving as the priorinformation to guide the model in aligning visual and textual features, thereby addressing the challenge of featurediscrepancy. Additionally, we design a global semanticcomparison mechanism to enhance the performance of generating more comprehensive and accurate medical reports.To enable the implementation of ultrasound report generation, we constructed three large-scale ultrasound image-textdatasets from different organs for training and validationpurposes. Extensive evaluations with other state-of-the-artapproaches exhibit its superior performance across all threedatasets. Code and dataset are valuable at this link.Index Terms—Ultrasound image, report generation,unsupervised learning, transformer, breast, thyroid, liver.
自动报告生成的研究背景与本文方法 在计算机辅助诊断领域,自动报告生成已成为重要研究方向,其目标是基于医学图像自动生成报告,以减轻临床医生的工作负担。本文提出一种新型自动超声报告生成框架,结合无监督与有监督学习方法辅助报告生成过程。 该框架通过无监督学习方法从超声文本报告中提取潜在知识,将其作为先验信息引导模型实现视觉与文本特征的对齐,进而解决特征差异问题。此外,本文还设计全局语义对比机制,以提升生成报告的完整性与准确性。 为实现超声报告生成任务,本文构建了三个涵盖不同器官的大规模超声图像-文本数据集,用于模型训练与验证。与当前主流方法的大量对比实验表明,该方法在三个数据集上均表现出更优性能。相关代码与数据集可通过链接获取。 关键词——超声图像、报告生成、无监督学习、Transformer、乳腺、甲状腺、肝脏
Method
方法
Fig. 2 presents our proposed method consisting of threemodules: Knowledge Distiller (KD), Knowledge MatchedVisual Extractor (KMVE), and Report Generator (RG).KD aims to obtain prior knowledge from ultrasound reports.KMVE focuses on extracting visual features associated withtext and aligning visual and textual features based on theacquired knowledge. RG is designed to generate ultrasoundreports using aligned visual features with a comparison mechanism to enhance the generation performance.
图2展示了我们提出的方法,该方法包含三个模块:知识提取器(Knowledge Distiller,KD)、知识匹配视觉提取器(Knowledge Matched Visual Extractor,KMVE)和报告生成器(Report Generator,RG)。 其中,KD旨在从超声报告中获取先验知识;KMVE侧重于提取与文本相关的视觉特征,并基于所获取的知识实现视觉与文本特征的对齐;RG的设计目标是利用对齐后的视觉特征生成超声报告,同时通过一种比较机制来提升生成性能。
Conclusion
结论
In this work, we propose a novel framework that combines unsupervised and supervised learning for ultrasoundreport generation. Our framework leverages the unsupervisedlearning clustering method to extract prior knowledge fromultrasound text reports, which is then utilized to guide thetraining process. Additionally, we designed a similarity comparer in the report generator to enhance the prediction process.Furthermore, we built three large ultrasound report datasetsof different organs to assess the framework’s performanceacross various organs. Through extensive experimentation andanalysis of three ultrasound datasets, we demonstrate theeffectiveness and superiority of our framework compared tobaseline models. Despite the promising results achieved, it isimportant to realise the existing limitations of current models. Similar to other state-of-the-art approaches, our methodexhibits insensitivity to terms related to size, location, andnumber within ultrasound reports. This insensitivity may beattributed to the uneven distribution of these terms in thevocabulary, following a long-tail distribution pattern. Consequently, further research is required to address this challengeand improve the accuracy in handling such situations.
本文方法总结与局限性说明 在本研究中,我们提出了一种结合无监督学习与有监督学习的新型框架,用于超声报告生成。该框架采用无监督学习聚类方法从超声文本报告中提取先验知识,并利用这些知识指导训练过程;此外,我们在报告生成器中设计了相似性比较器,以优化预测过程。同时,为评估该框架在不同器官上的性能表现,我们构建了三个针对不同器官的大型超声报告数据集。 通过在三个超声数据集上开展大量实验与分析,我们证实了所提框架相较于基准模型的有效性与优越性。尽管已取得了良好的结果,但需认识到当前模型仍存在局限性:与其他主流方法类似,我们的方法对超声报告中与尺寸、位置及数量相关的术语不敏感。这种不敏感性可能源于这些术语在词汇表中呈长尾分布,导致数据分布不均衡。因此,未来仍需进一步研究以攻克这一难题,提升模型在处理此类情况时的准确性。
本文方法总结与局限性说明 在本研究中,我们提出了一种结合无监督学习与有监督学习的新型框架,用于超声报告生成。该框架采用无监督学习聚类方法从超声文本报告中提取先验知识,并利用这些知识指导训练过程;此外,我们在报告生成器中设计了相似性比较器,以优化预测过程。同时,为评估该框架在不同器官上的性能表现,我们构建了三个针对不同器官的大型超声报告数据集。 通过在三个超声数据集上开展大量实验与分析,我们证实了所提框架相较于基准模型的有效性与优越性。尽管已取得了良好的结果,但需认识到当前模型仍存在局限性:与其他主流方法类似,我们的方法对超声报告中与尺寸、位置及数量相关的术语不敏感。这种不敏感性可能源于这些术语在词汇表中呈长尾分布,导致数据分布不均衡。因此,未来仍需进一步研究以攻克这一难题,提升模型在处理此类情况时的准确性。
Figure
图

Fig. 1. Examples of the ultrasound report and radiology report. Theoriginal ultrasound report is written in Chinese.
图1 超声报告与放射科报告示例 (注:原始超声报告以中文撰写)
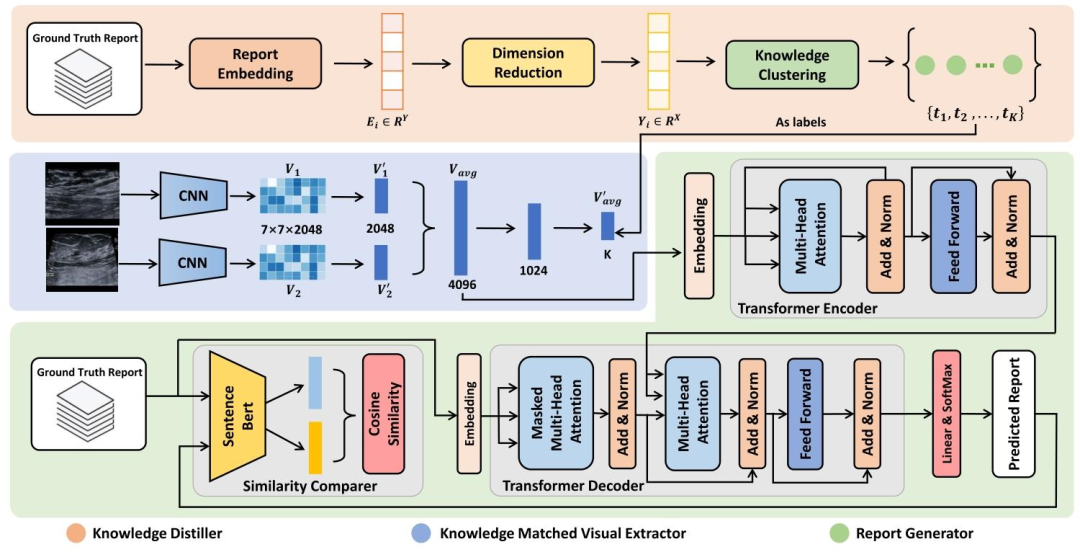
Fig. 2. An overview of our proposed report generation framework. The orange section shows the Knowledge Distiller (KD), which extracts potentialprior knowledge from ultrasound reports using unsupervised learning methods. The blue section is the Knowledge Matched Visual Extractor (KMVE),which uses prior knowledge extracted by the KD module to guide the visual extractor to capture knowledge-related visual features, addressing theproblem of mismatch between visual and textual features. The green section shows the Report Generator (RG), which generates a text sequencefrom visual features, with a Transformer Encoder Decoder backbone and a proposed Similarity Comparer module.
图2 所提报告生成框架概况 橙色部分为知识提取器(Knowledge Distiller,KD),通过无监督学习方法从超声报告中提取潜在先验知识;蓝色部分为知识匹配视觉提取器(Knowledge Matched Visual Extractor,KMVE),利用KD模块提取的先验知识引导视觉提取器捕捉与知识相关的视觉特征,以解决视觉与文本特征不匹配问题;绿色部分为报告生成器(Report Generator,RG),以Transformer编解码器为基础架构,并结合所提相似性比较器(Similarity Comparer)模块,从视觉特征中生成本文序列。

Fig. 3. Age and gender distribution of our collected ultrasound datasetsfrom three organs.
图3 所收集的三个器官超声数据集的年龄与性别分布

Fig. 4. Hyper-parameter searching with 10% liver training data.(a) shows the report generation performance evaluated by the ROUGE-Lmetric, whereas (b) shows the results evaluated by the METEOR metric
图4 基于10%肝脏训练数据的超参数搜索 (a)为采用ROUGE-L指标评估的报告生成性能,(b)为采用METEOR指标评估的结果

Fig. 5. Heatmap of clustering results with different dimensionality reduction and cluster numbers. Each heatmap in this table displays clusteringresults, with the x-axis representing the dimensions of dimensionalityreduction and the y-axis indicating different numbers of clusters. Thevalues in each cell of the heatmap represent the silhouette coefficientscores, which reflect the performance of the clustering for each combination of dimension reduction and cluster numbers.
图5 不同降维方式与聚类数量下的聚类结果热力图 此表中的每张热力图均展示聚类结果:横轴代表降维后的维度,纵轴代表不同的聚类数量;热力图每个单元格中的数值为轮廓系数(silhouette coefficient)得分,该得分反映了对应降维方式与聚类数量组合下的聚类性能。
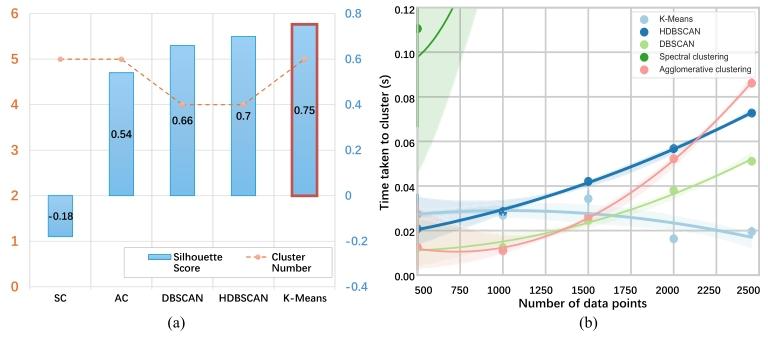
Fig. 6. Comparison between different clustering methods. (a) Clusteringperformance of each method. (b) Time efficiency of each method. SC andAC denote spectral clustering and agglomerative clustering
图6 不同聚类方法的对比 (a)为各方法的聚类性能;(b)为各方法的时间效率。其中,SC代表谱聚类(spectral clustering),AC代表层次聚类(agglomerative clustering)

Fig. 7. The number of correct entailments for different entities. A higher correct number represents more accurate descriptions per entity. It shouldbe noted that the CNN-RNN method cannot describe certain entities, resulting in some entailment numbers of 0.
图7 不同实体的正确蕴含数量 数值越高表示对每个实体的描述越准确。需注意,CNN-RNN方法无法描述部分实体,导致其部分蕴含数量为0。

Fig. 8. Attention maps of different words in the sentence. Warmcolours indicate high attention, while cool colours indicate low attention.To preserve the original word order of Chinese, the English translationmay exhibit unconventional expressions and grammatical variations.
图8 句子中不同词语的注意力热力图 暖色调表示注意力权重高,冷色调表示注意力权重低。需说明的是,为保留中文原有的词语顺序,英文译文可能存在表达非常规、语法有差异的情况。

Fig. 9. Visualization results in breast dataset. The highlighted words represent descriptions aligned with the ground truth reports. It is worth notingthat all the results were originally presented in Chinese. We used Google Translate to provide the English translations.
图9 乳腺数据集的可视化结果 高亮显示的词语代表与真实报告(ground truth reports)对齐的描述内容。需说明的是,所有结果原文均以中文呈现,本文采用谷歌翻译(Google Translate)提供对应的英文译文。

Fig. 10. Visualization results in thyroid and liver dataset. The highlighted words are incorrect and differ from the ground truth reports. It is worthnoting that all the results were originally presented in Chinese. We used google translate to provide the English translations.
图10 甲状腺与肝脏数据集的可视化结果 高亮显示的词语为错误描述,与真实报告(ground truth reports)存在差异。需说明的是,所有结果原文均以中文呈现,本文采用谷歌翻译(Google Translate)提供对应的英文译文。
Table
表

TABLE I REPLACEMENT RULE FOR NUMERICAL VALUES
表1 数值替换规则

TABLE II THE COARSE RANGE FOR THE NUMBER OF CLUSTERS FROMDIFFERENT EMBEDDING METHODS
表2 不同嵌入方法的聚类数量粗略范围

TABLE III FINAL PARAMETER SETTINGS AND CLUSTER SCORES FOR THEKNOWLEDGE DISTILLER MODULE. FROM LEFT TO RIGHT, THECOLUMN’S HEADINGS ARE DATASET, DATASET SIZE, EMBEDDINGMETHOD, VOCABULARY SIZE, DIMENSION REDUCTION,CLUSTERING NUMBER AND SILHOUETTE SCORE
表3 知识提取器(Knowledge Distiller)模块的最终参数设置与聚类得分 从左至右,各列标题依次为:数据集(Dataset)、数据集规模(Dataset Size)、嵌入方法(Embedding Method)、词汇表大小(Vocabulary Size)、降维方式(Dimension Reduction)、聚类数量(Clustering Number)及轮廓系数得分(Silhouette Score)

TABLE IV COMPARING REPORT GENERATION RESULTS FROM EACHCLUSTERING METHOD ON THE THYROID DATASET. B-1 TO B-4REFER TO BLEU-1 TO BLEU-4. M AND R-L DENOTEMETEOR AND ROUGE-L
表4 各聚类方法在甲状腺数据集上的报告生成结果对比 其中,B-1至B-4分别代表BLEU-1至BLEU-4(4个不同n-gram的BLEU评价指标),M代表METEOR指标,R-L代表ROUGE-L指标
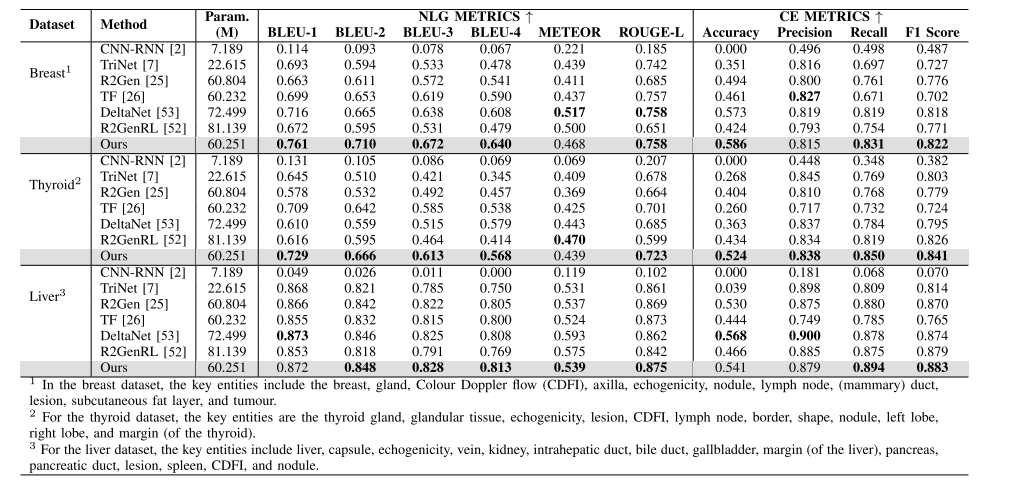
TABLE V PERFORMANCE COMPARISON FROM THREE ULTRASOUND DATASETS. BEST PERFORMANCES ARE HIGHLIGHTED IN BOLD
表5 三个超声数据集上的性能对比 (注:最优性能结果已用粗体突出显示)
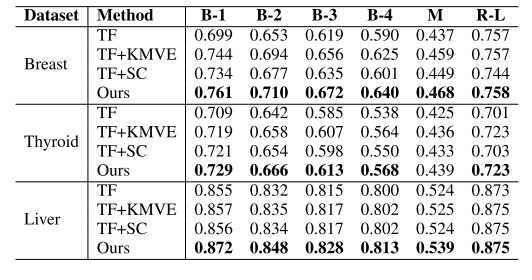
TABLE VI ABLATION STUDIES FROM THREE ULTRASOUND DATASETS. BESTPERFORMANCES ARE HIGHLIGHTED IN BOLD
表 6 三个超声数据集上的消融实验结果