Title
题目
IGU-Aug: Information-Guided UnsupervisedAugmentation and Pixel-Wise ContrastiveLearning for Medical Image Analysis
IGU-Aug:面向医学图像分析的信息引导无监督数据增强与逐像素对比学习
01
文献速递介绍
对比学习(CL)相关研究与IGU-Aug策略提出 对比学习(CL)是自监督学习(SSL)的一种形式,在该框架下,数据通过代理任务为模型提供监督信号[2]。与以往的自监督学习方法不同,对比学习的核心是通过对比具有相同分布与不同分布的样本,在嵌入空间中学习数据的特征表示[3]-[7]。目前,对比学习已被广泛应用于提升分类任务(典型的实例级任务)的性能。然而,当将实例级对比学习直接应用于像素级下游任务[8]-[9](如标志点检测、图像分割、目标检测)时,由于监督粒度的差异,其辅助效果十分有限。因此,面临像素级下游任务挑战的研究者更倾向于采用逐像素对比学习。 逐像素对比学习的性能在很大程度上取决于正负样本对的生成质量[10]-[11],这引发了我们对一个关键问题的思考:如何高效地为逐像素对比学习增强训练样本对,尤其是在无监督场景下? 目前尚无针对无监督场景的自动数据增强方法,但Hataya等人在有监督训练中提出的方法为我们提供了启发[1]。该方法将增强参数的搜索转化为增强后数据集与原始数据集的密度匹配问题,认为最优的数据增强应通过生成对抗网络(GAN)[12]减小两个数据集的瓦瑟斯坦距离,从而使二者尽可能相似。然而,由于缺乏标签,该方法无法应用于无监督对比学习,且不适用于逐像素对比学习任务。 本文旨在通过挖掘密集型对比学习的优势与特性,以无监督方式、按像素粒度自适应优化正负样本对的获取,从而解决上述挑战。 首先,图像在像素层面存在信息量不均衡的特点:每个像素及其上下文信息对理解图像中的局部区域、目标物体和整体结构所提供的辅助作用存在差异。例如,在标志点检测这一典型的逐像素任务中,信息量大的像素往往能发挥更重要的作用。因此,对图像中像素的信息量进行量化,并重点关注高信息区域,将对任务性能提升具有重要意义。我们发现,在对比学习中,若对含更多语义信息的像素所构成的正样本对施加过强的增强操作,会对其造成更大损害——过强的增强会给正样本对带来更大的绝对扰动,进而破坏其语义信息。基于此,本文对不同类型的像素采用差异化增强策略:对高信息像素施加较弱的增强,对低信息像素施加较强的增强。但目前鲜有方法能在无监督场景下实现这一目标。为突破这一限制,我们引入图像信息熵(IIE)的概念,用于评估单个像素及其邻域内容的复杂度;借助图像信息熵,我们将像素划分为低信息、中信息和高信息三类,并在信息更丰富的区域内构建更多对比像素对。 其次,对于特定像素,我们可将语义一致的像素归为同一类别。随后,与以往方法类似,我们通过观察增强后数据与原始数据的兼容性,来评估数据增强参数的适用性。在实际操作中,我们通过判断增强后数据中边缘样本到中心样本的距离是否超出合理范围,来确定数据增强的适宜性(需注意,该距离通过互信息进行估计)。此外,若为每个像素单独估计增强参数,会引入显著误差,因此我们采用组级平均的方式来降低这种误差。图1直观展示了本研究思路的核心动机。 综上,我们提出一种面向逐像素对比学习的信息引导式像素增强(IGU-Aug)策略,其主要贡献如下: 1. 据我们所知,本文首次提出按像素粒度设计的像素增强方法,用于改进无监督逐像素对比学习。 2. 引入图像信息熵(IIE) 这一指标来量化单个像素所含的信息量;以图像信息熵值为指导,将像素划分为低信息、中信息和高信息三类,并验证了中高信息像素在逐像素对比学习中的重要性。 3. 以无监督方式为不同类别像素设计自适应增强强度,显著提升了实验性能。 4. 通过大量实验验证了核心策略(包括偏向性选择高信息像素、采用自适应增强策略)的有效性:在头影测量数据集和手部X射线数据集上,将单样本模型CC2D[13]的平均重建误差(MRE)分别从2.85mm降至2.31mm、从2.20mm降至1.70mm;此外,该策略还显著提升了腹部磁共振(Abd-MRI)和腹部计算机断层扫描(Abd-CT)数据集上的单样本分割模型性能。
Abatract
摘要
Contrastive learning (CL) is a form of self*supervised learning and has been widely used for varioustasks. Different from widely studied instance-level contrastive learning, pixel-wise contrastive learning mainlyhelps with pixel-wise dense prediction tasks. The counterpart to an instance in instance-level CL is a pixel, alongwith its neighboring context, in pixel-wise CL. Aiming tobuild better feature representation, there is a vast literature about designing instance augmentation strategies forinstance-level CL; but there is little similar work on pixelaugmentation for pixel-wise CL with a pixel granularity.In this paper, we attempt to bridge this gap. We first classify apixel into three categories, namely low-, medium-, and highinformative, based on the information quantity the pixelcontains. We then adaptively design separate augmentation strategies for each category in terms of augmentationintensity and sampling ratio. Extensive experiments validatethat our information-guided pixel augmentation strategysucceeds in encoding more discriminative representations and surpassing other competitive approaches inunsupervised local feature matching. Furthermore, our pretrained model improves the performance of both one-shotand fully supervised models. To the best of our knowledge, we are the first to propose a pixel augmentationmethod with a pixel granularity for enhancing unsupervised pixel-wise contrastive learning.
对比学习(CL) 对比学习(CL)是自监督学习的一种形式,已广泛应用于各类任务中。与已被广泛研究的实例级对比学习不同,逐像素对比学习主要助力于像素级密集预测任务。在实例级对比学习中,“实例”是对比对象;而在逐像素对比学习中,对比对象是单个像素及其周边上下文信息。 为构建更优的特征表示,现有大量文献围绕实例级对比学习的实例增强策略设计展开研究;但针对逐像素对比学习、以像素为粒度的像素增强研究却较为匮乏。本文旨在填补这一空白:首先,根据像素所包含的信息量,将其划分为低信息像素、中信息像素和高信息像素三类;随后,针对每类像素,在增强强度和采样比例方面自适应设计差异化的增强策略。 大量实验验证表明,我们提出的信息引导式像素增强策略能够成功编码更具区分性的特征表示,在无监督局部特征匹配任务中性能优于其他主流方法。此外,基于该策略预训练的模型还可提升单样本学习模型与全监督学习模型的性能。据我们所知,本文首次提出以像素为粒度的像素增强方法,用于改进无监督逐像素对比学习。
Method
方法
Pixels behave differently as shown in Fig. 3 (left), inspiringus to treat them with different strategies for each pixel.We naturally reform the standard contrastive loss into a
pixel-wise adaptive loss:L* = XiLi(ρi, Ai) = XiρiL(τ (xi, Ai), xi), (6)
where xi refers to a pixel (along with its content in s × simage patch), τ (xi, Ai) refers to transformation on xi withaugmentation parameters Ai and ρi refers to the weights of xiduring training. However, the above ideal case of customizingstrategies {ρi, Ai} for each pixel xi is hard to achieve due toits time-consuming nature, thus a practical way is to cluster xiinto several classes and adjust {ρ , A} for each class.A. Information-Guided Pixel Categorization*To cluster xi , we use Image Information Entropy (IIE)and contrastive loss (Loss), which are already detailedin section III. We use 3-order polynomial regression to achievethe blue curve in Fig. 3 (left). The U-shaped curve of the lossagainst IIE and the dashed line of the total average loss, nicelysplitting pixels into three categories: low-, medium- and highinfo pixels. We list their details as follows.Low-info pixels featuring low IIE and low loss:most of them contain less semantic information andmuch noise (low IIE) but are easy to discriminate(low loss).Medium-info pixels featuring medium IIE and highloss: they have medium texture information (mediumIIE) but are hard to discriminate for networks
(high loss).High-info pixels featuring high IIE and low loss: mostof them are edges and corners with much deterministicinformation (high IIE) and they are easy to discriminatefor networks (low loss).With the division of all pixels into three categories, our pixelaugmentation goal can be formulated as follows:L(ρl, ρm, ρh, Al, Am, Ah)= Xα∈{l,m,h}ραLα(* f (τ (xα, Aα), xα)), (7)where the total loss L is split into 3 losses Ll , Lm and Lhwith their sampling ratios ρl , ρm, and ρh and augmentationintensities Al , Am, and Ah for the low-, medium- and high-infopixels xl , xm, and xh, respectively. The proposed strategy ofaugmenting pixels is to find the optimal sampling ratio andaugmentation intensity for each category such that the overallloss is minimized. Next, we will elaborate how to do so oneby one.
像素的表现各不相同(如图3左图所示),这启发我们对每个像素采用不同的处理策略。我们自然地将标准对比损失改进为逐像素自适应损失: L = ∑i Li(ρi, Ai) = ∑i ρi L(τ(xi, Ai), xi) (6) 其中,xi表示一个像素(及其在s×s图像块中的内容),τ(xi, Ai)表示使用增强参数Ai对xi进行的变换,ρi表示训练过程中xi的权重。然而,上述为每个像素xi定制策略{ρi, Ai}的理想情况难以实现,因为其耗时性较高,因此一种可行的方法是将xi聚类为若干类别,并为每个类别调整{ρ, A}。 ## A. 信息引导的像素分类 为对xi进行聚类,我们采用了“图像信息熵(IIE)”和“对比损失(Loss)”,二者已在第三章详细介绍。我们通过三阶多项式回归得到图3左图中的蓝色曲线。损失值随IIE变化的U型曲线以及总平均损失的虚线,可将像素很好地划分为三类:低信息像素、中信息像素和高信息像素。以下是各类像素的详细说明: 1)低信息像素:具有低IIE和低损失值的特点。这类像素大多包含较少的语义信息,且噪声较多(低IIE),但易于区分(低损失值)。 2)中信息像素:具有中等IIE和高损失值的特点。这类像素拥有中等程度的纹理信息(中等IIE),但网络难以对其进行区分(高损失值)。 3)高信息像素:具有高IIE和低损失值的特点。这类像素大多为边缘和角点,包含大量确定性信息(高IIE),且网络易于对其进行区分(低损失值)。 将所有像素划分为这三类后,我们的像素增强目标可表述如下: L(ρl, ρm, ρh, Al, Am, Ah) = ∑α∈{l, m, h} ρα Lα(f(τ(xα, Aα), xα)) (7) 其中,总损失L被拆分为三个损失项Ll、Lm和Lh,ρl、ρm、ρh分别为低信息、中信息、高信息像素(xl、xm、xh)的采样比例,Al、Am、Ah分别为三类像素的增强强度。所提出的像素增强策略旨在为每个类别找到最优的采样比例和增强强度,从而使总损失最小化。接下来,我们将逐一详细说明如何实现这一目标。
Conclusion
结论
Image augmentation at a pixel granularity is not well studiedfor pixel-wise CL. To this, we propose an information-guidedpixel augmentation strategy to boost pixel-wise CL. We firstclassify pixels into three categories, namely low/medium/highinformative, based on the information quantity the pixelcontains. We then design separate strategies for each category including sampling pixels with entropy-based weightmaps; estimating augmentation parameters by mutual information; applying adaptive augmentation. Experiments forboth landmark detection and segmentation validate that ourinformation-guided pixel augmentation strategy succeeds inencoding more discriminative representations and outperforms other competitive approaches in unsupervised localfeature matching. Additionally, supervised models can also beenhanced by our pre-trained model. Currently, our augmentation method is unsupervised and we use density consistencyas the main objective. In the future, we will apply it to asemi-supervised setting. A possible way is to first predictpseudo-labels of unlabeled data through existing labeled dataand construct the intra-class samples, and then use the densitymatching method in this article to predict appropriate dataaugmentation parameters for each category. The obtainedparameters can be used in new training to get a better model.For existing medical imaging workflows, before training amodel, our method can provide a more powerful augmentationpolicy to optimize the model training.
在逐像素对比学习(CL)中,像素粒度的图像增强尚未得到充分研究。为此,我们提出一种信息引导的像素增强策略,以改进逐像素对比学习。具体步骤如下:首先,根据像素包含的信息量,将像素划分为低信息、中信息、高信息三类;随后,为每类像素设计独立策略,包括基于熵权图的像素采样、通过互信息估计增强参数、施加自适应增强。 针对标志点检测与分割任务的实验表明,我们提出的信息引导像素增强策略能够成功编码更具区分性的特征表示,且在无监督局部特征匹配任务中,性能优于其他同类方法。此外,利用我们的预训练模型,还可对监督学习模型进行性能提升。 目前,我们的增强方法属于无监督学习范畴,主要以密度一致性为目标函数。未来,我们计划将其应用于半监督学习场景。一种可行思路是:先通过已有带标签数据预测无标签数据的伪标签,并构建类内样本;再采用本文提出的密度匹配方法,为每类样本预测合适的数据增强参数;最终将所得参数用于新的训练过程,以获得性能更优的模型。 对于现有医学影像处理流程而言,在模型训练前,我们的方法可提供更有效的增强策略,从而优化模型训练过程。
Figure
图
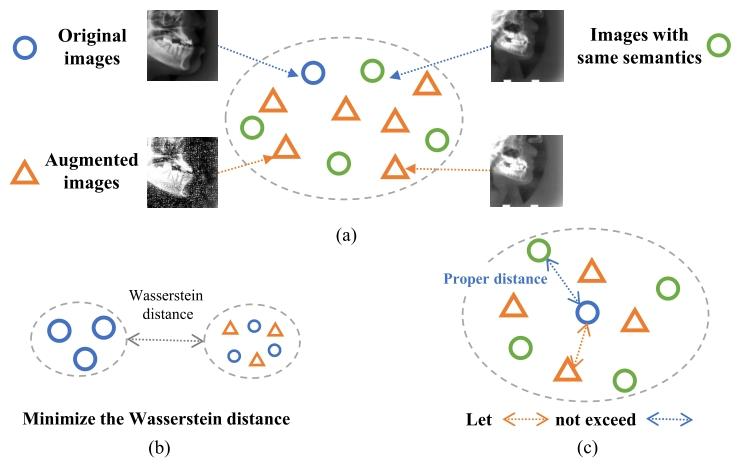
Fig. 1. (a) Similar to [1], we regard data augmentation as a process thatfills missing data points of the original training data; (b) Hayata et.al [1]minimize the Wasserstein distance between original and augmenteddatasets by GAN trained with labeled samples; © Our method estimatesa reasonable distance by finding samples of the same class and controlsthe augmented samples within the distance
图1 数据增强思路对比 (a)与文献[1]的思路类似,本文将数据增强视为对原始训练数据中缺失数据点的补充过程; (b)Hayata等人[1]通过利用带标签样本训练生成对抗网络(GAN),最小化原始数据集与增强后数据集之间的瓦瑟斯坦距离; (c)本文方法通过寻找同类样本估计合理距离范围,并将增强后的样本控制在该距离范围内。

Fig. 2. Core idea of our method.
图 2 本文方法的核心思路

Fig. 3. Overview of our method. (1) Pixel Categorization. (2) Adaptive augmentation. Unsupervised landmark detector F is a pretrained CC2D [13]without labels.
图3 本文方法的整体框架 (1)像素分类(Pixel Categorization);(2)自适应增强(Adaptive Augmentation)。其中,无监督标志点检测器F是未使用标签、基于CC2D模型[13]预训练得到的模型。

Fig. 4. Pipeline of CC2D , an unsupervised landmark detector.LCL refers to (1)
图4 无监督标志点检测器CC2D[13]的流程 LCL指
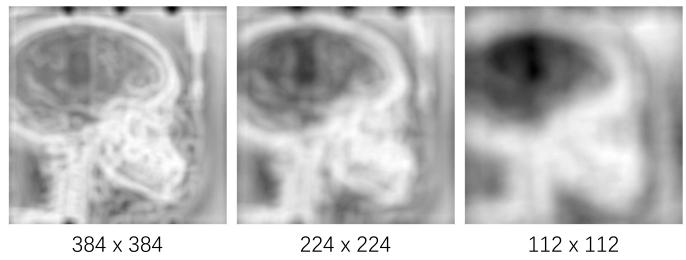
Fig. 5. Image information entropy maps of images with different sizes.
图 5 不同尺寸图像的图像信息熵图

Fig. 6. (left) Distribution of IIE of images with different resolutions. (right)Results of low-resolution images.
图6 不同分辨率图像的图像信息熵(IIE)相关结果 (左图)不同分辨率图像的图像信息熵(IIE)分布; (右图)低分辨率图像的实验结果。
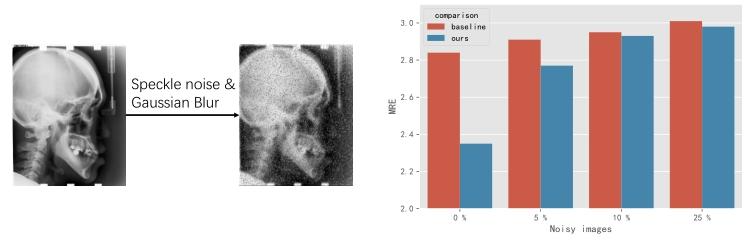
Fig. 7. (left) Add noise to images. (right) Results of noisy datasets.
图7 噪声实验结果 (左图)向图像中添加噪声的示意图
Table
表

TABLE ICOMPARISON OF SSL FOR Local Feature Matching WITH OTHERAPPROACHES ON CEPHALOMETRIC [50] TESTSET
表1 头影测量数据集 [50] 测试集上,本文自监督学习(SSL)方法与其他方法在局部特征匹配任务中的性能对比

TABLE IIABLATION STUDY FOR COMPONENTS IN OUR METHODON CEPHALOMETRIC [50] TESTSET
表2 头影测量数据集[50]测试集上本文方法各组件的消融实验

TABLE IIIANALYSIS CONDUCTED ON CEPHALOMETRIC DATASET.COMPARISON OF OTHER PIXEL-WISE SSLFOR local Feature Matching
表 3 头影测量数据集 上的分析:本文方法与其他逐像素自监督学习(SSL)方法在局部特征匹配任务中的对比

TABLE IVACCURACY WITH DIFFERENT γ
表 4 不同γ值对应的准确率

TABLE VIIE MAPS OF DIFFERENT PATCH SIZES FOR SAMPLING
表5 不同采样块大小的图像信息熵图(IIE Maps)
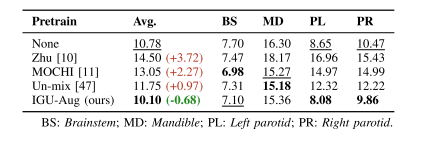
TABLE VICOMPARISON WITH DIFFERENT PRE-TRAINED MODEL FORCC2D-S2 ON H&N 3D TEST SETS. THE BEST ANDTHE SECOND-BEST PERFORMANCES ARE HIGHLIGHTED
表 6 头颈部 3D 测试集上不同预训练模型与 CC2D-S2 模型 的性能对比

TABLE VIICOMPARISON OF THE Supervised AND One-Shot APPROACHES WITH DIFFERENT PRE-TRAINED MODEL ON CEPHALOMETRIC [50]AND HAND X-RAY . THE BEST AND THE SECOND-BEST PERFORMANCES ARE HIGHLIGHTED
表7 头影测量数据集[50]与手部X射线数据集[53]上,不同预训练模型对应的监督学习方法与单样本学习方法性能对比

TABLE VIIIQUANTITATIVE COMPARISON BETWEEN OUR METHOD AND OTHERSOTA METHODS. THE BEST PERFORMANCES ARE HIGHLIGHTED
表8 本文方法与其他最优方法(SOTA)的定量对比 最优性能(BEST)已突出显示。

TABLE IXCOMPARISON OF DIFFERENT KEY POINT EXTRACTORS.PERFORMANCE EVALUATION ON THECEPHALOMETRIC TESTSET
表9 不同关键点提取器的对比——头影测量测试集上的性能评估

TABLE XCOMPARISON OF EASE OF IMPLEMENTATION, COMPUTATIONAL EFFICIENCY, SCALABILITY AND APPLICABILITY
表10 易用性、计算效率、可扩展性及适用性对比

TABLE XIPERFORMANCE OF SSL-ALP MODELS TRAINEDON Abd-CT ON WORD TESTSET. (DICE %)
表11 在腹部计算机断层扫描(Abd-CT)数据上训练的自监督学习-自适应局部增强(SSL-ALP)模型在WORD测试集上的性能(DICE系数,单位:%)