Title
题目
TCFNet: Bidirectional face-bone transformation via a Transformer-basedcoarse-to-fine point movement network
TCFNet:基于 Transformer 的从粗到精点移动网络实现人脸 - 骨骼双向转换
01
文献速递介绍
正颌手术可矫正颅颌面(CMF)畸形,恢复面部外观,改善骨骼功能,如咀嚼和吞咽(Zammit等人,2023年)。其主要目标是矫正骨骼畸形,在颌骨与下颌骨之间建立协调的空间关系(Millesi等人,2023年)。此外,面部美学协调是患者极为关注的问题,也是正颌手术的一个重要目标(Bianchi等人,2023年)。正颌手术通常依靠计算机辅助手术(CAS)(Elnagar等人,2020年)进行术前规划,通过对颌骨和下颌骨建模,确定截骨后骨骼畸形矫正所需的位移。具体而言,该过程包括:(1)从(锥形束)计算机断层扫描(CBCT、CT)切片中分割并重建颌骨和下颌骨(Zhang等人,2024a);(2)提取截骨后的骨骼,模拟手术过程以确定最佳移动路径(Han等人,2021年;Fang等人,2024年;Ma等人,2023b);(3)调整截骨后的骨骼使其恢复正常,并确保面部表面变化与畸形矫正效果相契合。因此,CAS 中精确的术前规划对正颌手术的成功及患者术后恢复起着关键作用(Denadai等人,2020年)。计算机辅助手术模拟(CASS)技术能够精准模拟截骨后骨骼的调整路径。尽管骨骼移动在术后可实现良好的功能性咬合,但由于骨骼与软组织之间复杂的非线性相互作用,要实现美观协调、比例匀称且令人满意的面部外观仍具挑战性。因此,在正颌手术规划任务中,准确模拟骨骼与面部外观之间的关系至关重要。 面骨变换旨在从骨骼结构重建面部外观,反之亦然;生物力学模拟方法被广泛用于预测(Mollemans等人,2007年)。这些方法通常构建手工特征来预测目标组织,包括质量弹簧模型(MSM)、质量张量模型(MTM)和有限元模型(FEM)(Kim等人,2019年)。其中,有限元模型往往能达到最佳预测精度(Ruggiero等人,2023年)。然而,有限元模型需要大量计算时间,且数据处理流程繁琐,才能在临床流程中生成可接受的有限元网格模型(Kim等人,2021年)。其实际应用受到限制,因为外科医生在正颌手术规划过程中往往需要多次尝试,而模拟必须快速进行才能在临床流程中有效发挥作用(Lampen等人,2023年)。此外,大多数方法假设相似组织在变换后保持一致性,这并不现实,因为该假设忽略了个体特异性的差异。 深度学习的最新进展,尤其是点云处理的3D表示学习方法,为传统生物力学模拟方法提供了有前景的替代方案,能够高效、快速地进行组织模拟预测(Lampen等人,2023年;Fang等人,2024年;Ma等人,2023b、a;Bao等人,2024b)。基于深度学习的方法将面骨变换视为点云对之间的点对点对应问题。具体而言,从面部和骨骼网格中采样密集点云,以确保重建结果准确且无变形。然后采用点云学习方法提取用于变换的详细拓扑和结构关系,生成点对点位移场。该位移场用于将点从源3D形状移动到目标形状。先前的研究(Ma等人,2023a;Bao等人,2024b)利用3D离散卷积从体素化的3D空间中提取特征,用于在点云上实现的深度神经网络;这种策略会产生许多异常值,且计算和内存消耗大(Wu等人,2019年)。因此,这些实现方式内存消耗大且效率低,将网络输入限制在少于5000个点。这一限制使得先前的方法难以利用大规模数据的潜在优势,使其不适合处理密集点云。显然,处理稀疏点云会降低对局部细节特征的建模能力,且依赖于点云采样算法的性能。先前的网络能够通过下采样层扩大感受野,但与基于Transformer的方法相比,感受野有限。 为应对大规模点云,近期的进展(Graham等人,2018年)在生成高效卷积骨干网方面取得了进展,可克服上述数据规模限制。稀疏卷积(Graham等人,2018年)缓解了这一限制,但感受野小的卷积网络难以捕捉全局依赖关系。基于Transformer的模型(Zhao等人,2021年)特别适合点云处理,因为Transformer架构的核心自注意力机制本质上是一种集合算子,且具有输入置换不变性。近期的一项研究(Wu等人,2024年)引入了一种基于Transformer的模型,性能更强、感受野更广、速度更快,名为Point Transformer V3(PTV3)。具体而言,它用点云序列化取代了传统的K近邻(KNN)操作,能够更高效地处理密集点云。此外,它使用Transformer捕捉空间全局关系,将感受野扩展到1024个点。因此,我们提出一种基于Point Transformer V3(PTv3)(Wu等人,2024年)的Transformer网络,以高效处理密集面骨点云。然而,由于舍弃了K近邻(KNN)操作,PTv3在建模局部结构时性能下降。为克服这一问题,受3D形状补全领域的启发(该领域广泛使用多步骤或多尺度框架(Wen等人,2023年、2021年;Yu等人,2023年)以从粗到精的方式恢复缺失的点云),我们引入了从粗到精的点移动网络(TCFNet),这是一种基于Transformer的网络。具体而言,TCFNet采用以下改进,以在面骨形状变换任务中实现出色的精度和高效性能。 (1)我们提出一种名为TCFNet的双向点云变换框架,用于双向面骨预测。它采用两步从粗到精的网络,包括基于Transformer的阶段和局部信息聚合网络(LIA - Net),以学习面部和骨骼点云之间的密集对应关系和复杂局部结构。与先前开发的方法(Ma等人,2023a)相比,TCFNet无需下采样为稀疏点云,即可在单次测试中实现面骨形状变换,且其多项评估指标和可视化结果更优。此外,它在预处理过程中无需预对齐,在后处理过程中无需模板配准。 (2)为克服点云序列化导致的邻域精度损失,我们提出LIA - Net,对结合局部区域特征、其方向和相对全局位置特征的局部几何结构进行建模。为聚合先前移动路径及其当前位置的特征,第一阶段的全局特征用于指导LIA - Net中的局部位移场,类似于门控循环单元(GRU)。消融实验表明,我们提出的LIA - Net模型显著增强了对局部结构(如鼻子和嘴唇)的变换和重建能力。 (3)受可变形医学图像配准任务中辅助损失的启发,我们提出一种可选的辅助损失,以促进医生极为关注的器官局部关键特征之间的对应关系。与配准类似,大量的器官标注可改善变换和重建过程的局部和全局性能。
Abatract
摘要
Computer-aided surgical simulation is a critical component of orthognathic surgical planning, where accuratelysimulating face-bone shape transformations is significant. The traditional biomechanical simulation methodsare limited by their computational time consumption levels, labor-intensive data processing strategies andlow accuracy. Recently, deep learning-based simulation methods have been proposed to view this problem asa point-to-point transformation between skeletal and facial point clouds. However, these approaches cannotprocess large-scale points, have limited receptive fields that lead to noisy points, and employ complexpreprocessing and postprocessing operations based on registration. These shortcomings limit the performanceand widespread applicability of such methods. Therefore, we propose a Transformer-based coarse-to-fine pointmovement network (TCFNet) to learn unique, complicated correspondences at the patch and point levels fordense face-bone point cloud transformations. This end-to-end framework adopts a Transformer-based networkand a local information aggregation network (LIA-Net) in the first and second stages, respectively, whichreinforce each other to generate precise point movement paths. LIA-Net can effectively compensate for theneighborhood precision loss of the Transformer-based network by modeling local geometric structures (edges,orientations and relative position features). The previous global features are employed to guide the localdisplacement using a gated recurrent unit. Inspired by deformable medical image registration, we proposean auxiliary loss that can utilize expert knowledge for reconstructing critical organs. Our framework is anunsupervised algorithm, and this loss is optional. Compared with the existing state-of-the-art (SOTA) methodson gathered datasets, TCFNet achieves outstanding evaluation metrics and visualization results.
计算机辅助手术模拟是正颌手术规划的关键组成部分,其中准确模拟面骨形状变换意义重大。传统的生物力学模拟方法受限于计算耗时、数据处理策略繁琐(劳动强度大 )以及精度较低。近年来,已提出基于深度学习的模拟方法,将该问题视为骨骼与面部点云之间的点对点变换。然而,这些方法无法处理大规模点云,感受野有限会导致点云噪声问题,并且需要基于配准进行复杂的预处理和后处理操作。这些缺陷限制了此类方法的性能和广泛适用性。因此,我们提出一种基于Transformer的从粗到精点移动网络(TCFNet),以在面片和点层面学习独特、复杂的对应关系,实现密集面骨点云变换。这个端到端框架在第一阶段和第二阶段分别采用基于Transformer的网络和局部信息聚合网络(LIA - Net),二者相互强化以生成精确的点移动路径。LIA - Net通过对局部几何结构(边、方向和相对位置特征 )建模,能够有效弥补基于Transformer的网络的邻域精度损失。利用门控循环单元,先前的全局特征可用于指导局部位移。受可变形医学图像配准的启发,我们提出一种辅助损失,可利用专家知识重建关键器官。我们的框架是一种无监督算法,且该损失为可选项。与现有最先进(SOTA)方法在收集的数据集上对比,TCFNet取得了出色的评估指标和可视化结果 。
Method
方法
The task of conducting bidirectional prediction between faces andbones (i.e., between a facial point cloud 𝐏𝐹 and a corresponding skeletal point cloud 𝐏𝐵) is formulated as a point cloud deformation process.
面部与骨骼之间的双向预测任务(即面部点云𝐏*𝐹与对应的骨骼点云𝐏𝐵之间的预测)被表述为一个点云变形过程。
Conclusion
结论
In summary, we propose a simple and end-to-end framework,TCFNet, which is a Transformer-based coarse-to-fine point movementnetwork, to simulate the relationships between bones and facial appearances during orthognathic surgery planning. TCFNet can accuratelyand efficiently process dense point clouds, utilize global-to-local features derived from coarse-to-fine point movement, and overcome thetraditional tradeoff between global and local matching. Additionally,our proposed auxiliary information loss can leverage prior expertknowledge to achieve better local region matching effects. Finally, ourmethod produces optimal results in comparison with those of otherSOTA methods.
总之,我们提出了一个简单的端到端框架——TCFNet,这是一种基于Transformer的从粗到精点移动网络,用于模拟正颌手术规划中骨骼与面部外观之间的关系。TCFNet能够准确且高效地处理密集点云,利用从粗到精点移动所衍生的全局到局部特征,克服了传统方法在全局匹配与局部匹配之间存在的权衡问题。此外,我们提出的辅助信息损失能够借助已有的专家知识,实现更好的局部区域匹配效果。最后,与其他最先进(SOTA)方法相比,我们的方法取得了最优结果。
Figure
图

Fig. 1. The framework of our proposed TCFNet. It includes a data preprocessing module, a point Transformer network in the first stage and an LIA-Net model in the second stage.LIA-Net is composed of local region features, orientations and globally relative position features. The pointwise noise is an independent Gaussian noise vector, which is similar tothat used in P2P-Net (Yin et al., 2018). The GRU is a gated recurrent unit. The positional encoding scheme is an enhanced conditional positional encoding (xCPE) method (Wang,2023; Wu et al., 2024)
图1. 我们提出的TCFNet框架。它包括一个数据预处理模块、第一阶段的点Transformer网络和第二阶段的LIA-Net模型。 LIA-Net由局部区域特征、方向特征和全局相对位置特征组成。逐点噪声是一个独立的高斯噪声向量,类似于P2P-Net(Yin等人,2018)中使用的噪声。GRU是门控循环单元。位置编码方案是一种增强的条件位置编码(xCPE)方法(Wang,2023;Wu等人,2024)。

Fig. 2. Capturing the orientation and relative position features between a point 𝒑 andthe farthest region 𝒒 ∈ 𝛺far via LIA-Net. 𝜃 is the orientation between vector 𝒑𝒒 andthe 𝑥, 𝑦, 𝑧-axis. 𝑾 𝑨 = 𝑾 𝒙 , 𝑾 𝒚 , 𝑾 𝒛 denotes learnable weights that can extract directionfeatures from the edge features.
图2. 通过LIA-Net捕捉点𝒑与最远区域𝒒∈𝛺far之间的方向和相对位置特征。𝜃是向量𝒑𝒒*⃗与x、y、z轴之间的方向角。𝑾 𝑨=𝑾 𝒙⃗、𝑾 𝒚⃗、𝑾 𝒛⃗*表示可学习权重,能够从边缘特征中提取方向特征。

Fig. 3. Comparison between the results produced for the predicted facial point clouds and the ground-truth point clouds. The green points are the predicted points, and the redpoints are the ground-truth points.
图3. 预测的面部点云结果与真实点云的对比。绿色点为预测点,红色点为真实点。

Fig. 4. Comparison between the results produced for the predicted skeletal point clouds and the ground-truth point clouds
图4. 预测的骨骼点云结果与真实点云的对比。

Fig. 5. The visual comparison of the local ROI between results produced for the predicted facial point clouds and the ground-truth point clouds. The predicted local point cloud(face and bone) is obtained from the ground-truth labeled ROI (bone and face) after network transformation, and this bone and face point cloud come from a person. The red,yellow, green, blue points are the ground-truth nose, lip, predicted nose and lip, respectively.
图5. 预测的面部点云结果与真实点云在局部感兴趣区域(ROI)的可视化对比。预测的局部点云(面部和骨骼)是通过网络变换从带真实标签的感兴趣区域(骨骼和面部)得到的,且该骨骼和面部点云来自同一人。红色点、黄色点、绿色点、蓝色点分别为真实的鼻子、真实的嘴唇、预测的鼻子、预测的嘴唇。

Fig. 6. Comparison between the results produced in local areas for the predicted point clouds and the ground-truth point clouds.
图6. 局部区域中预测点云结果与真实点云的对比。

Fig. 7. The visual comparison of the local ROI between results produced for the predicted facial point clouds and the ground-truth point clouds. Individual columns correspondto a pair of bony and facial structures from the same person. The red, yellow, green, blue points are the ground-truth nose, lip, predicted nose and lip, respectively
图7. 预测的面部点云结果与真实点云在局部感兴趣区域(ROI)的可视化对比。每一列对应同一人的一组骨骼与面部结构。红色点、黄色点、绿色点、蓝色点分别为真实的鼻子、真实的嘴唇、预测的鼻子、预测的嘴唇。

Fig. 8. Visualization results of coarse and fine predicted point clouds of our method.
图8. 我们方法的粗略预测点云和精细预测点云的可视化结果。

Fig. 9. Comparisons of the error distribution between the predicted and ground-truth meshes from 4 persons in test set
图9. 测试集中4个人的预测网格与真实网格之间误差分布的对比。

Fig. 10. The prediction results of our method. The mesh is sampled into a point cloud which is the input of our network. The output of the point cloud is reconstructed to amesh for better visualization. The data is from the same person
图10. 我们方法的预测结果。将网格采样为点云作为我们网络的输入。为了更好地可视化,将输出的点云重建为网格。数据来自同一人。

Fig. 11. Comparison between ground-truth and predicted meshes from two persons in the test set
图11. 测试集中两个人的真实网格与预测网格的对比。
Table
表
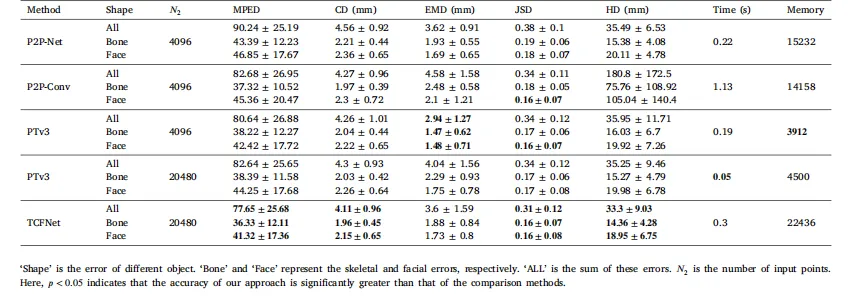
Table 1The results produced by our approach and other comparison methods on the test set according to a 5-fold cross-validation process
表1根据5折交叉验证过程,我们的方法与其他对比方法在测试集上产生的结果

Table 2The local errors between our approach and the other SOTA methods on the test set,determined via 5-fold cross-validation
表2 通过5折交叉验证确定的我们的方法与其他最先进(SOTA)方法在测试集上的局部误差

Table 3Comparison between the results obtained with the optional auxiliary loss and other losses
表3 采用可选辅助损失与其他损失所获结果的对比

Table 4The results produced by our proposed method in ablation experiments.
表4 我们提出的方法在消融实验中产生的结果。