Title
题目
Robust image representations with counterfactual contrastive learning
基于反事实对比学习的鲁棒图像表征
01
文献速递介绍
医学影像中的对比学习已成为利用未标记数据的有效策略。这种自监督学习方法已被证明能大幅提升模型在域迁移时的泛化能力,还能减少训练所需的高质量标注数据量(阿齐兹等人,2021年、2023年;格苏等人,2022年;周等人,2023年)。然而,基于对比的学习能否成功,在很大程度上取决于正样本对的生成流程(田等人,2020年)。这些正样本对通常是通过对原始图像反复应用预定义的数据增强操作来生成的。因此,增强流程的变化会对所学表征的质量产生重大影响,最终影响下游任务的性能以及对域变化的鲁棒性(田等人,2020年;斯卡尔贝特等人,2023年)。传统上,为自然图像开发的增强流程被直接应用于医学影像,但由于医学扫描的采集方式存在独特挑战和特点,这种做法可能并非最优。特别是,域变异往往比细微的类别差异大得多。这可能导致通过对比学习得到的表征在不经意间将这些与采集相关的无关变异编码到所学表征中。在这项工作中,我们旨在提高通过对比学习得到的表征对域迁移(尤其是采集偏移)的鲁棒性。采集偏移是由图像采集协议(设备设置、后处理软件等)的变化引起的,是医学影像领域中数据集偏移的主要来源。我们假设,在正样本对创建阶段更忠实地模拟域变异,能够提高对比学习得到的特征对图像特征这类变化的鲁棒性。为此,我们提出并评估了 “反事实对比学习”,这是一种新的对比样本对生成框架,利用深度生成模型的最新进展来生成高质量、逼真的反事实图像(里贝罗等人,2023年;丰塔内拉等人,2023年)。反事实生成模型让我们能够回答 “如果…… 会怎样” 问题,比如模拟用一种设备采集的乳房X线照片,若用另一种设备采集会是什么样子。具体而言,在我们提出的反事实对比框架中,我们通过将真实图像与其域反事实图像进行匹配来创建跨域正样本对,逼真地模拟设备变化。重要的是,所提出的方法与对比学习目标的选择无关,因为它只影响正样本对的创建步骤。我们针对两种广泛使用的对比学习框架说明了这种方法的优势:开创性工作SimCLR(陈等人,2020年)和新发布的DINO - V2(奥夸布等人,2023年)目标。此外,为了精确衡量所提出的反事实样本对生成过程的效果,我们还将所提出的方法与一种更简单的方法进行了比较,后者只是用生成的反事实图像扩展训练集。我们在两种医学图像模态(乳房X线摄影和胸部X线摄影)、五个公共数据集以及两项与临床相关的分类任务上对所提出的反事实对比学习框架进行了评估,结果表明,我们的方法生成的特征对域变化具有更强的鲁棒性。这种增强的鲁棒性在特征空间中能直接观察到,更重要的是,下游任务的性能有了显著提升,尤其是在标注数据有限以及训练时域代表性不足的情况下。关键的是,尽管训练目标存在重大差异,但这些发现对SimCLR和DINO - V2都成立。本文是我们近期MICCAI研讨会论文(罗舍维茨等人,2024年)的扩展。它在以下方面有所不同: - 我们之前只考虑了SimCLR目标,这里我们将反事实对比方法扩展到最近提出的DINO - V2(奥夸布等人,2023年)目标。这些新结果实证表明,所提出的方法具有通用性,且与对比学习目标的选择无关。 - 虽然这项工作的主要关注点是对采集偏移的鲁棒性,但在本次扩展中,我们表明所提出的方法可以扩展到这种情况之外,例如,用于改善亚组性能。 - 我们大幅扩展了讨论、方法和相关工作部分 。
Abatract
摘要
Contrastive pretraining can substantially increase model generalisation and downstream performance. However, the quality of the learned representations is highly dependent on the data augmentation strategy applied to generate positive pairs. Positive contrastive pairs should preserve semantic meaning while discarding unwanted variations related to the data acquisition domain. Traditional contrastive pipelines attempt to simulate domain shifts through pre-defined generic image transformations. However, these do not always mimic realistic and relevant domain variations for medical imaging, such as scanner differences. To tackle this issue, we herein introduce counterfactual contrastive learning, a novel framework leveraging recent advances in causal image synthesis to create contrastive positive pairs that faithfully capture relevant domain variations. Our method, evaluated across five datasets encompassing both chest radiography and mammography data, for two established contrastive objectives (SimCLR and DINO-v2), outperforms standard contrastive learning in terms of robustness to acquisition shift. Notably, counterfactual contrastive learning achieves superior downstream performance on both in-distribution and external datasets, especially for images acquired with scanners under-represented in the training set. Further experiments show that the proposed framework extends beyond acquisition shifts, with models trained with counterfactual contrastive learning reducing subgroup disparities across biological sex.
对比预训练能够大幅提升模型的泛化能力和下游任务性能。然而,所学表征的质量在很大程度上取决于用于生成正样本对的数据增强策略。正对比样本对应在保留语义信息的同时,摒弃与数据采集域相关的无关变异。传统对比学习流程试图通过预定义的通用图像变换来模拟域迁移。但对于医学影像而言,这些变换并不总能模拟出真实且相关的域变异,比如扫描仪差异。为解决这一问题,我们在此引入反事实对比学习这一新颖框架,它借助因果图像合成方面的最新进展来创建对比正样本对,能够切实捕捉相关的域变异。我们在涵盖胸部X线摄影和乳腺X线摄影数据的五个数据集上,针对两种成熟的对比学习目标(SimCLR和DINO - v2)对该方法进行了评估,结果表明,在应对采集偏移的鲁棒性方面,它优于标准对比学习。值得注意的是,反事实对比学习在分布内数据集和外部数据集的下游任务中都实现了更优性能,对于训练集中代表性不足的扫描仪所采集的图像而言更是如此。进一步的实验表明,所提出的框架的作用不止于应对采集偏移,经反事实对比学习训练的模型能够减少不同生物性别的亚组差异 。
Figure
图

Fig. 1. We propose a novel counterfactual contrastive pair generation framework for improving robustness of contrastively-learned features to distribution shift. As opposed to solely relying on a pre-defined augmentation generation pipeline (as in standard contrastive learning), we propose to combine real images with their domain counterfactuals to create realistic cross-domain positive pairs. Importantly, this proposed approach is independent of the specific contrastive objective employed. The causal image generation model is represented by the ‘do’ operator. We also compare the proposed method to another approach where we simply extend the training set with the generated counterfactual images without explicit matching with their real counterparts, treating real and counterfactuals as independent training samples. Source: Figure adapted from Roschewitz et al. (2024). © 2024 The Author(s), under exclusive license to Springer Nature Switzerland AG
图1. 我们提出了一种新颖的反事实对比样本对生成框架,以提高通过对比学习得到的特征对分布偏移的鲁棒性。与标准对比学习中仅依赖预定义的增强生成流程(\mathcal{T})不同,我们提议将真实图像与其域反事实图像相结合,以创建逼真的跨域正样本对。重要的是,所提出的方法独立于所采用的特定对比学习目标。因果图像生成模型由“do”算子表示。我们还将所提出的方法与另一种方法进行了比较,在后一种方法中,我们只是用生成的反事实图像扩展训练集,而不将其与对应的真实图像进行明确匹配,将真实图像和反事实图像视为独立的训练样本。 来源:图改编自Roschewitz等人(2024年)。© 2024作者,独家授权给施普林格自然瑞士股份公司。

Fig. 2. Causal graphs used to train the counterfactual image generation models used in this study.
图2. 本研究中用于训练反事实图像生成模型的因果图。

Fig. 3. Examples of counterfactual images generated with our model. Note that on PadChest, text is only imprinted on a subset of Imaging scans (not on Phillips): our model respects this by removing text when generating counterfactuals from Imaging to Phillips and vice-versa. Generated images have a resolution of 224 × 224 pixels for PadChest and 224 × 192 for EMBED.
图3. 我们的模型生成的反事实图像示例。请注意,在PadChest数据集中,文本仅印在部分Imaging扫描图像上(Phillips扫描图像上没有):我们的模型在从Imaging生成Phillips的反事实图像时会去除文本,反之亦然,以此遵循这一特点。生成的图像中,PadChest数据集的图像分辨率为224×224像素,EMBED数据集的为224×192像素。

Fig. 4. Distribution of scanners in the original (real-only) training set and the counterfactual-augmented training set for EMBED (top) and PadChest (bottom).
图4. EMBED(上)和PadChest(下)的原始(仅真实图像)训练集与经反事实增强的训练集中扫描仪的分布情况。

Fig. 5. Pneumonia detection results with linear probing (frozen encoder, solid lines) and finetuning (unfrozen encoder, dashed lines) for models trained with the SimCLR objective. Results are reported as average ROC-AUC over 3 seeds, shaded areas denote ± one standard error. We also compare self-supervised encoders to a supervised baseline initialised with ImageNet weights.
图5. 采用SimCLR目标训练的模型在肺炎检测任务中的线性探测(冻结编码器,实线)和微调(解冻编码器,虚线)结果。结果以3次随机种子实验的平均ROC-AUC值呈现,阴影区域表示±1个标准误差。我们还将自监督编码器与以ImageNet权重初始化的有监督基线模型进行了比较。

Fig. 6. ROC-AUC difference to SimCLR baseline for CF-SimCLR and SimCLR+ for pneumonia detection. The top row depicts results with linear probing, bottom row shows results with model finetuning. Results are reported as average ROC-AUC difference compared to the baseline (SimCLR) over 3 seeds, error bars denote ± one standard error. CF-SimCLR consistently outperforms encoders trained with standard SimCLR and SimCLR+ (where counterfactuals are added to the training set) for linear probing, and performs best overall for full model finetuning.
图6. CF-SimCLR和SimCLR+在肺炎检测任务中相对于SimCLR基线的ROC-AUC差异。上排为线性探测结果,下排为模型微调结果。结果以3次随机种子实验相对于基线(SimCLR)的平均ROC-AUC差异呈现,误差线表示±1个标准误差。在 linear probing 中,CF-SimCLR 始终优于采用标准 SimCLR 和 SimCLR+(将反事实图像添加到训练集)训练的编码器;在全模型微调中,CF-SimCLR 总体表现最佳。
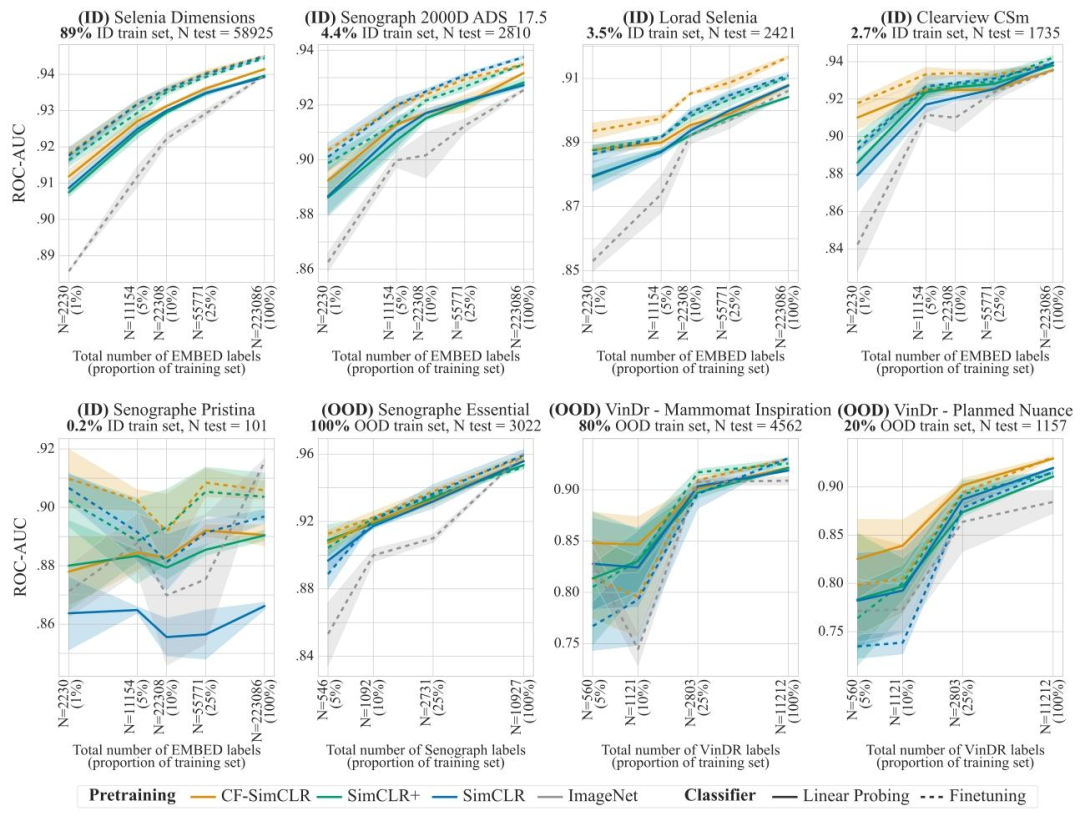
Fig. 7. Breast density results with linear probing (frozen encoder, solid lines) and finetuning (unfrozen encoder, dashed lines) for models trained with SimCLR. Results are reported as average one-versus-rest macro ROC-AUC over 3 seeds, shaded areas denote ± one standard error. CF-SimCLR performs best overall across ID and OOD data, and improvements are largest in the low data regime and on under-represented scanners.
图7. 采用SimCLR训练的模型在乳房密度预测任务中的线性探测(冻结编码器,实线)和微调(解冻编码器,虚线)结果。结果以3次随机种子实验的平均一对一宏ROC-AUC值呈现,阴影区域表示±1个标准误差。CF-SimCLR在分布内(ID)和分布外(OOD)数据上总体表现最佳,且在数据量较少的情况下以及在代表性不足的扫描仪数据上,改进最为显著。

Fig. 8. ROC-AUC difference between SimCLR and CF-SimCLR (resp. SimCLR+) for breast density assessment. The top two rows denote results with linear probing, and the bottom two rows show results with model finetuning. Results are reported as average macro ROC-AUC difference compared to the baseline (SimCLR) over 3 seeds, error bars denote ± one standard error. CF-SimCLR overall performs best across ID and OOD data, improvements are largest in the low data regime and on under-represented scanners.
图8. SimCLR与CF-SimCLR(相应地,SimCLR+)在乳房密度评估任务中的ROC-AUC差异。最上方两行是线性探测结果,最下方两行是模型微调结果。结果以3次随机种子实验相对于基线(SimCLR)的平均宏ROC-AUC差异呈现,误差线表示±1个标准误差。CF-SimCLR在分布内(ID)和分布外(OOD)数据上总体表现最佳,且在数据量较少的情况下以及在代表性不足的扫描仪数据上,改进最为显著。

Fig. 9. Breast density classification results for models pretrained with DINO-v2, for both linear probing and finetuning. Results are reported as average one-versus-rest macro ROC-AUC over 3 seeds, shaded areas denote ± one standard error. CF-DINO performs best overall, across ID and OOD data, improvements are largest in the low data regime.
图9. 采用DINO-v2预训练的模型在乳房密度分类任务中的线性探测和微调结果。结果以3次随机种子实验的平均一对一宏ROC-AUC值呈现,阴影区域表示±1个标准误差。CF-DINO在分布内(ID)和分布外(OOD)数据上总体表现最佳,在数据量较少的情况下改进最为显著。

Fig. 10. ROC-AUC difference between DINO and CF-DINO (resp. DINO+). Top two rows denote results with linear probing, bottom two rows results with model finetuning. Results are reported as average macro ROC-AUC difference compared to the baseline (DINO) over 3 seeds, error bars denote ± one standard error. CF-DINO overall performs best across ID and OOD data, improvements are largest in the low data regime and on under-represented scanners.
图10. DINO与CF-DINO(相应地,DINO+)之间的ROC-AUC差异。最上方两行是线性探测结果,最下方两行是模型微调结果。结果以3次随机种子实验相对于基线(DINO)的平均宏ROC-AUC差异呈现,误差线表示±1个标准误差。CF-DINO在分布内(ID)和分布外(OOD)数据上总体表现最佳,且在数据量较少的情况下以及在代表性不足的扫描仪数据上,改进最为显著。

Fig. 11. Pneumonia detection results for models trained with DINO-v2, for both linear probing (frozen encoder) and finetuning. Results are reported as average ROC-AUC over 3 seeds, shaded areas denote ± one standard error. CF-DINO consistently outperforms standard DINO.
图11. 采用DINO-v2训练的模型在肺炎检测任务中的线性探测(冻结编码器)和微调结果。结果以3次随机种子实验的平均ROC-AUC值呈现,阴影区域表示±1个标准误差。CF-DINO始终优于标准DINO。

Fig. 12. ROC-AUC difference to DINO baseline for CF-DINO and DINO+ for pneumonia detection. The top row depicts results with linear probing, bottom row show results with model finetuning. Results are reported as average ROC-AUC difference compared to the baseline (DINO) over 3 seeds, error bars denote ± one standard error.
图12. CF-DINO和DINO+在肺炎检测任务中相对于DINO基线的ROC-AUC差异。上排为线性探测结果,下排为模型微调结果。结果以3次随机种子实验相对于基线(DINO)的平均ROC-AUC差异呈现,误差线表示±1个标准误差

Fig. 13. t-SNE projections of embeddings from 16,000 randomly sampled test images from mammography encoders trained with SimCLR, SimCLR+ and CF-SimCLR. Encoders trained with SimCLR and SimCLR+ exhibit domain clustering. CF-SimCLR embeddings are substantially less domain-separated and the only disjoint cluster exclusively contains breasts with implants, semantically different. Thumbnails show a randomly sampled image from each ‘implant’ cluster.
图13. 从采用SimCLR、SimCLR+和CF-SimCLR训练的乳房X线摄影编码器中随机抽取的16,000张测试图像嵌入的t-SNE投影。采用SimCLR和SimCLR+训练的编码器呈现出域聚类现象。CF-SimCLR的嵌入在域上的分离度显著降低,且唯一的离散聚类仅包含有植入物的乳房图像,这在语义上是不同的。缩略图展示了每个“植入物”聚类中随机抽取的一张图像。

Fig. 14. Effectiveness comparison for the three counterfactual models considered in this ablation study, by intervention. Computed on 8304 validation set samples.
图14. 本消融研究中所考虑的三种反事实模型在不同干预下的效果比较。基于8304个验证集样本计算得出。

Fig. 15. Qualitative of comparison of the three counterfactual generation models, HVAE-, HVAE and HVAE+FT compared in the ablation study. For each model we show generated counterfactuals as well as direct effect maps. Direct effects give a visual depiction of the increase in effectiveness across the three models from top to bottom. We also observe that all models preserve semantic identity very well, a key aspect in positive pair creation contrastive learning.
图15. 消融研究中三种反事实生成模型(HVAE-、HVAE和HVAE+FT)的定性比较。对于每个模型,我们展示了生成的反事实图像以及直接效应图。直接效应直观地呈现了从顶部到底部这三种模型在效果上的提升。我们还观察到,所有模型都能很好地保留语义一致性,这是对比学习中创建正样本对的关键要素。

Fig. 16. Effect of counterfactual quality on downstream performance. Results are reported as average macro ROC-AUC difference compared to the baseline (SimCLR) over 3 seeds for linear probing, error bars denote ± one standard error. We compare running CF-SimCLR with (i) HVAE- a counterfactual generation model of lesser effectiveness, (ii) HVAE the generation model used in the rest of this study, (iii) HVAE+FT a counterfactual generation model with higher effectiveness.
图16. 反事实质量对下游任务性能的影响。结果以3次随机种子实验中线性探测相对于基线(SimCLR)的平均宏ROC-AUC差异呈现,误差线表示±1个标准误差。我们比较了使用以下三种模型运行CF-SimCLR的效果:(i)HVAE-——一种效果较差的反事实生成模型;(ii)HVAE——本研究其余部分所使用的生成模型;(iii)HVAE+FT——一种效果更优的反事实生成模型。

Fig. 17. Improving sub-group performance with counterfactual contrastive learning. Pneumonia detection results with linear probing for encoders trained with SimCLR and SexCF-SimCLR. In SexCF-SimCLR, we generate sex counterfactuals instead of domain counterfactuals for positive pair generation to improve robustness to subgroup shift and, ultimately, performance on under-represented subgroups. Top row: performance for the male (solid line) and female (dashed line) subgroups, reported as average ROC-AUC over 3 seeds, shaded areas denote ± standard error. Bottom row: performance disparities across the two subgroups, reported as average ROC-AUC difference between the male and female subgroups, over 3 seeds. Sex CF-SimCLR reduces sub-group disparities for all datasets, substantially increasing performance on the female sub-group when limited amounts of labels are available, both on ID and OOD datasets.
图17. 利用反事实对比学习改善亚组性能。采用SimCLR和SexCF-SimCLR训练的编码器在肺炎检测任务中的线性探测结果。在SexCF-SimCLR中,我们生成性别反事实图像而非域反事实图像来创建正样本对,以提高对亚组偏移的鲁棒性,并最终提升代表性不足亚组的性能。上排:男性(实线)和女性(虚线)亚组的性能,以3次随机种子实验的平均ROC-AUC值呈现,阴影区域表示±标准误差。下排:两个亚组间的性能差异,以3次随机种子实验中男性和女性亚组的平均ROC-AUC差值呈现。SexCF-SimCLR减少了所有数据集上的亚组差异,在标注数据有限的情况下,大幅提升了女性亚组在分布内(ID)和分布外(OOD)数据集上的性能。
Table
表

Table 1 Datasets splits and inclusion criteria. Splits are created at the patient level.
表1 数据集划分及纳入标准。划分以患者为单位进行。

Table 2 Axiomatic soundness metrics (Monteiro et al., 2022) for the three models considered in this ablation study. Computed on the 8304 validation set samples.
表2 本消融研究中所考虑的三个模型的公理合理性指标(Monteiro等人,2022年)。基于8304个验证集样本计算得出。