Title
题目
Outlier detection in cardiac diffusion tensor imaging: Shot rejection or robust fitting?
心脏扩散张量成像中的异常值检测:是剔除异常测量值还是采用稳健拟合方法?
01
文献速递介绍
心脏扩散张量成像(cDTI)是一种无创、无需造影剂且无电离辐射的方法,用于描绘心肌的微观结构,其基于水分子的(各向异性)随机运动(里斯等人,1995年;斯科兰等人,1998年)。扩散模型可以适配通过对不同方向和幅度的扩散进行敏感化处理后获得的图像。通常会为每个体素拟合一个扩散张量模型(巴塞尔等人,1994年),从中可以得到诸如平均扩散率(MD)和分数各向异性(FA)等参数(巴塞尔和皮尔保利,1996年),以及各种表征组织方向和结构的生物标志物,比如以“薄片”角度E2A为特征的心肌细胞主方向和层状聚集体方向(孔等人,2011年;费雷拉等人,2014年;尼耶尔斯 - 瓦莱斯平等人,2017年)。这些指标已被证明在不同的病理状态和健康状态下会有所不同,因此有助于深入了解心肌疾病对组织结构和构造的影响(费雷拉等人,2014年;阿卜杜拉等人,2014年;冯・多伊斯特等人,2016年;哈利克等人,2018年;有贺等人,2019年;戈奇等人,2020年;尼耶尔斯 - 瓦莱斯平等人,2020年;达斯等人,2021年;拉赫曼等人,2022年;埃德尔等人,2022年;达斯等人,2023年;乔伊等人,2023年)。与其他器官的扩散张量成像相比,心脏扩散张量成像更具挑战性,主要原因是心脏和呼吸运动的幅度比水分子扩散产生的运动大几个数量级。序列设计和定制的运动补偿方案已取得了显著进展(斯托克等人,2016年),但在心脏扩散张量成像中,通常会对相同对比度的图像进行重复成像,以提供数据冗余并弥补相对较低的信噪比(SNR)。呼吸运动通常在后期处理中通过图像配准来校正。然而,除了热噪声之外,在名义上具有相同对比度的图像之间通常还存在额外的结构化变化。心脏相位以及心脏相对于成像平面的位置通常会有细微变化。此外,运动预计会通过组织相对于扩散梯度的差异(利曼斯和琼斯,2009年)、B0场不均匀性(里德等人,1998年;维尔马和科恩 - 阿达德,2014年)、线圈灵敏度(法拉吉 - 达纳等人,2016年)以及图像配准的插值效应(维什涅夫斯基等人,2015年)来调节图像强度。这些变化没有被专门建模,有时被称为“生理噪声”,以区别于“热噪声”。图像损坏也是心脏扩散张量成像中常见的问题:由于磁化率差异导致的信号丢失很常见,图像配准可能失败,而且生理噪声可能过于严重。在心脏扩散张量成像中,这些“异常值”图像通常在拟合扩散模型之前通过人工检查来识别并去除,尽管也有一些将这一过程自动化的尝试(费雷拉等人,2020年;科文尼等人,2023年)。然而,在利用稳健拟合和识别损坏图像来处理脑部扩散磁共振成像中的异常数据方面,已有大量文献。但这些方法在心脏扩散张量成像中并不常用。因此,我们简要回顾一下处理异常值的各种方法。**单个体素异常值检测**(SVOD)方法使用迭代拟合来实现一个对异常数据不敏感的稳健估计器(芒然等人,2002年),通常随后会去除异常值,并用非稳健估计器重新拟合,例如在RESTORE/iRESTORE算法中(张等人,2005年,2012年)。每个体素都是独立处理的。稳健估计器有多种选择(马克西莫夫等人,2011年),并且已经为扩散张量成像(DTI)的线性化公式(将模型拟合到对数信号)(科利尔等人,2015年)和扩散峰度建模(DKI)(塔克斯等人,2015年)开发出了稳健估计器。也已经开发出了针对DTI信号的“无模型”异常值校正方法(尼斯哈默等人,2007年)。在每次迭代中都使用了不带稳健估计器的迭代拟合来进行异常值检测(潘内克等人,2012年)。RESTORE已被应用于处理大脑中的生理噪声(沃克等人,2011年)。多体素异常值检测(MVOD)利用来自多个体素的信息来检测异常值,然后在拟合之前将其丢弃。连续切片之间图像的相关性(刘等人,2010年)、每个图像与参考图像之间的相关性(李等人,2014年;费雷拉等人,2020年)以及自动分割掩码之间的相似性(费雷拉等人,2022年)都可用于检测异常值。纹理特征(周等人,2011年)、强度直方图(斯塞尔福等人,2012年)和主方向的球形直方图(法尔津法尔等人,2013年)也已被用于异常值检测。我们之前曾使用观测图像与模型预测图像之间的均方误差来识别**心脏**DTI中的异常值(科文尼等人,2023年)。也可以将图像质量的度量纳入拟合权重中,以考虑图像质量的差异。在兹维尔斯(2010年)的研究中,权重基于每个图像上模型拟合的平均误差的平方。在李等人(2013年)的研究中,权重既取决于体素残差,也取决于“切片间强度不连续性”。图像的强度方差已被用于加权和“逐切片异常值检测”(赛拉宁等人,2018年)。在心脏扩散张量成像中,在拟合模型之前,通常会将被伪影严重损坏的图像从数据集中完全去除。这通常被称为“剔除异常测量值”(SR)。此外,(相关)文献表明,稳健拟合方法在心脏扩散张量成像中极少(如果有的话)被使用。人工识别损坏图像虽然常见,但具有主观性且耗时,而且由于生理噪声的存在,将图像完美地分为好图像和坏图像的模式可能存在缺陷。我们当前的这项研究工作的动机源于这样一个观察结果:在明显损坏的图像中,许多“错误”信号(例如心脏相位的巨大差异;图像配准的完全失败等)无法被单个体素异常值检测(SVOD)方法识别为异常值。图1(a)展示了一些“坏图像”(已剔除)的示例,旁边是具有相同扩散加权的等效“好图像”(参考图像)。在这种情况下,我们的剔除异常测量值(SR)方法(见附录A)识别出了这些需要去除的图像,而且这些损坏在视觉上很明显。尽管如此,本文后面介绍的单个体素异常值检测(SVOD)和多体素异常值检测(MVOD)算法(分别见第2.2节和第2.3节)给出了这些“坏图像”的稳健信号(即非异常值信号)图。单个体素异常值检测(SVOD)考虑所有图像的数据,但对每个体素独立处理,它未能将许多错误信号分类为异常值,而本文提出的多体素异常值检测(MVOD)方法则将所有信号都分类为异常值。图1(b)情况类似,不同之处在于第二列展示的是未被标记为需剔除异常测量值(SR)的图像,而且我们认为通过视觉检查不会发现有剔除异常测量值(SR)的必要(可能最后一行图像除外,在这种情况下,为了处理局部损坏,需要去除整幅图像)。第一行展示的是几乎相同的重复图像,单个体素异常值检测(SVOD)和多体素异常值检测(MVOD)都未检测到非稳健信号。然而,对于第二行和第三行的图像,尽管这些图像未被剔除异常测量值(SR)方法剔除,单个体素异常值检测(SVOD)却检测到了非稳健信号。多体素异常值检测(MVOD)检测到了更多的非稳健信号,并且在最后一行中显然覆盖了更多的伪影区域。在此展示图1是为了说明当前研究的动机。重要的是,单个体素异常值检测(SVOD)(甚至是多体素异常值检测(MVOD))未能识别所有“错误信号”对于当前所面临的问题(即扩散张量模型参数的稳健估计)是否真的重要,这一点并不明显。在稳健拟合算法中识别异常值只是一个附带目标:如果一个错误信号即使在使用稳健拟合的情况下也无法在统计上被识别为异常值,那么它可能对参数估计没有不利影响。然而,据我们所知,尽管图像损坏是心脏扩散张量成像中的一个基本且常见的问题,但从未对这个问题进行过系统的研究。在本文中,我们提出了使用稳健M估计器权重的迭代加权最小二乘法(IRLS),并结合单个体素异常值检测(SVOD)和多体素异常值检测(MVOD)技术。这些方法的公式与文献中的先前算法类似,并且可以应用于拟合问题的非线性版本(即拟合信号)和线性化版本(即拟合对数信号)。我们将这些方法,以及有剔除异常测量值(SR)和无剔除异常测量值(SR)的非稳健拟合方法,应用于健康志愿者(HV)和肥厚型心肌病(HCM)患者的数据集(达斯等人,2022年)。我们还使用人工损坏的数据集进行了模拟实验,以比较单个体素异常值检测(SVOD)和多体素异常值检测(MVOD)。我们的结果表明,稳健拟合方法优于剔除异常测量值(SR)方法,产生了更大且更具统计学意义的组间差异。对于平均扩散率(MD)和分数各向异性(FA),多体素异常值检测(MVOD)产生的组间差异比单个体素异常值检测(SVOD)更大,并且模拟实验表明,与单个体素异常值检测(SVOD)相比,多体素异常值检测(MVOD)能够更好地从损坏数据中恢复扩散指标。尽管如此,多体素异常值检测(MVOD)相对于单个体素异常值检测(SVOD)(应用于原始数据集时)的优势似乎较小,这表明单个体素异常值检测(SVOD)在识别所有错误信号方面的缺陷在实际中可能并不重要。因此,使用单个体素异常值检测(SVOD)或多体素异常值检测(MVOD)的稳健估计应该能够完全取代心脏扩散张量成像中的剔除异常测量值(SR)方法。
Abatract
摘要
Cardiac diffusion tensor imaging (cDTI) is highly prone to image corruption, yet robust-fitting methods arerarely used. Single voxel outlier detection (SVOD) can overlook corruptions that are visually obvious, perhapscausing reluctance to replace whole-image shot-rejection (SR) despite its own deficiencies. SVOD’s deficienciesmay be relatively unimportant: corrupted signals that are not statistical outliers may not be detrimental.Multiple voxel outlier detection (MVOD), using a local myocardial neighbourhood, may overcome the shareddeficiencies of SR and SVOD for cDTI while keeping the benefits of both. Here, robust fitting methods usingM-estimators are derived for both non-linear least squares and weighted least squares fitting, and outlierdetection is applied using (i) SVOD; and (ii) SVOD and MVOD. These methods, along with non-robust fittingwith/without SR, are applied to cDTI datasets from healthy volunteers and hypertrophic cardiomyopathypatients. Robust fitting methods produce larger group differences with more statistical significance for MD,FA, and E2A, versus non-robust methods, with MVOD giving the largest group differences for MD and FA.Visual analysis demonstrates the superiority of robust-fitting methods over SR, especially when it is difficultto partition the images into good and bad sets. Synthetic experiments confirm that MVOD gives lowerroot-mean-square-error than SVOD.
心脏扩散张量成像(cDTI)极易出现图像损坏的情况,但稳健拟合方法却很少被使用。单个体素异常值检测(SVOD)可能会忽略那些在视觉上明显的图像损坏情况,这或许就是尽管全图像异常点剔除(SR)自身存在缺陷,但人们仍不愿意用其他方法来取代它的原因。单个体素异常值检测(SVOD)的缺陷可能相对来说没那么重要:那些并非统计意义上异常值的损坏信号可能并无大碍。利用局部心肌邻域的多体素异常值检测(MVOD),或许能够克服全图像异常点剔除(SR)和单体素异常值检测(SVOD)在心脏扩散张量成像(cDTI)中的共同缺陷,同时保留两者的优点。在此,针对非线性最小二乘拟合和加权最小二乘拟合,推导出了使用M估计量的稳健拟合方法,并分别通过(i)单个体素异常值检测(SVOD);以及(ii)单个体素异常值检测(SVOD)和多体素异常值检测(MVOD)来进行异常值检测。这些方法,连同有无全图像异常点剔除(SR)的非稳健拟合方法,都被应用于来自健康志愿者和肥厚型心肌病患者的心脏扩散张量成像(cDTI)数据集。与非稳健拟合方法相比,稳健拟合方法在平均扩散率(MD)、分数各向异性(FA)和第二特征值与各向异性比值(E2A)方面产生了更大且更具统计学意义的组间差异,其中多体素异常值检测(MVOD)在平均扩散率(MD)和分数各向异性(FA)方面给出了最大的组间差异。视觉分析表明,稳健拟合方法优于全图像异常点剔除
Method
方法
DTI data are a series of 𝑛 images 𝑖 = 1 …𝑛 obtained with diffusionweightings 𝑏𝑖 and directions (unit vectors) 𝐠𝐢 = (𝑔𝑖,𝑥, 𝑔𝑖,𝑦, 𝑔𝑖,𝑧). Considering a single voxel, the noisy signal 𝑦𝑖 observed in image 𝑖 can be relatedto the signal model 𝑓(𝜽, 𝑏𝑖 , 𝐠𝐢 ), with parameters 𝜽 and the error 𝜖𝑖 as:𝑦𝑖 = 𝑓(𝜽, 𝑏𝑖 , 𝐠𝐢 ) + 𝜖𝑖(1)We focus on the diffusion tensor model of the signal:𝑓(𝜽, 𝑏𝑖 , 𝐠𝐢 ) = 𝑆0 exp ( −𝑏𝑖 𝐠𝐢 𝐃 𝐠 𝑇 𝐢 ) = exp ( 𝐱𝑖𝜽 𝑇 )(2)where 𝐱𝑖 = ( 1,−𝑏𝑖 𝑔𝑖,𝑥 2 ,−2𝑏𝑖 𝑔𝑖,𝑥𝑔𝑖,𝑦,−2𝑏𝑖 𝑔𝑖,𝑥𝑔𝑖,𝑧,−𝑏𝑖 𝑔𝑖,𝑦 2 ,−2𝑏𝑖 𝑔𝑖,𝑦𝑔𝑖,𝑧,−𝑏𝑖 𝑔𝑖,𝑧 2 ) , and model parameters 𝜃 = ( log(𝑆0 ), 𝐷𝑥𝑥, 𝐷𝑥𝑦, 𝐷𝑥𝑧, 𝐷𝑦𝑦,𝐷𝑦𝑧, 𝐷𝑧𝑧* ) . The methods presented here can apply to other models, suchas the diffusion kurtosis imaging (DKI) model. We denote the standarddeviation of the Gaussian noise in the original complex images as 𝜎.We consider magnitude images, for which the noise distribution can becomplicated (St-Jean et al., 2020); we assume Rician distributed errorfor simplicity (Cárdenas-Blanco et al., 2008), and note that 𝜖𝑖 resultsfrom both the Gaussian noise in the complex images and the magnitudeoperation.
扩散张量成像(DTI)数据是一系列(n)幅图像,其中(i = 1\ldots n),这些图像是通过扩散加权值(b_i)和方向(单位向量)(\mathbf{g}i=(g{i,x},g{i,y},g{i,z}))获取的。考虑单个体素时,在图像(i)中观测到的含噪信号(y_i),与信号模型(f(\boldsymbol{\theta},b_i,\mathbf{g}i))相关,其中参数为(\boldsymbol{\theta}),误差为(\epsilon_i),具体关系为: (y_i = f(\boldsymbol{\theta},b_i,\mathbf{g}i)+\epsilon_i) (1)我们关注信号的扩散张量模型: (f(\boldsymbol{\theta},b_i,\mathbf{g}i) = S_0 \exp(-b_i\mathbf{g}i\mathbf{D}\mathbf{g}iT)=\exp(\mathbf{x}i\boldsymbol{\theta}T)) (2)其中(\mathbf{x}i=(1, -b_i g{i,x}2, -2b_i g{i,x}g{i,y}, -2b_i g{i,x}g{i,z}, -b_i g{i,y}2, -2b_i g{i,y}g{i,z}, -b_i g{i,z}2)),并且模型参数(\theta = (\log(S_0), D{xx}, D{xy}, D{xz}, D{yy}, D{yz}, D{zz}))。这里提出的方法可以应用于其他模型,例如扩散峰度成像(DKI)模型。我们将原始复图像中高斯噪声的标准差记为(\sigma)。我们考虑幅度图像,其噪声分布可能很复杂(圣让等人,2020年);为简单起见,我们假设误差服从瑞利分布(卡德纳斯 - 布兰科等人,2008年),并注意到(\epsilon_i)是由复图像中的高斯噪声和幅度运算共同产生的。
Conclusion
结论
In this work, we have attempted to answer the question of whetherrobust-estimation can replace shot-rejection in cardiac diffusion tensorimaging, and whether the deficiencies of single voxel outlier detection are important for recovering correct diffusion tensor metrics. Wehave presented robust fitting with M-estimators followed by singlevoxel-outlier-detection and multiple-voxel-outlier-detection. Our results demonstrate that MVOD is more robust than SVOD, particularlyfor large numbers of corrupted images and low SNR. Nonetheless, theimprovement of MVOD over SVOD seems relatively minor for cardiacDTI, even as SVOD gives large improvements over shot-rejection,suggesting that researchers need not worry that SVOD misses signalsthat would be identified by shot-rejection, even if MVOD could identifythese signals. We recommend cDTI to start using robust-estimation inplace of shot-rejection.
在这项研究工作中,我们试图回答这样的问题:在心脏扩散张量成像中,稳健估计是否能够取代剔除异常测量值的方法,以及单个体素异常值检测方法的缺陷对于恢复正确的扩散张量指标是否重要。我们提出了先使用M估计量进行稳健拟合,随后进行单个体素异常值检测和多体素异常值检测的方法。我们的研究结果表明,多体素异常值检测(MVOD)比单个体素异常值检测(SVOD)更为稳健,尤其是在存在大量损坏图像且信噪比低的情况下。尽管如此,对于心脏扩散张量成像而言,多体素异常值检测(MVOD)相较于单个体素异常值检测(SVOD)的改进似乎相对较小,即便单个体素异常值检测(SVOD)相较于剔除异常测量值的方法已有显著改进。这表明研究人员无需担心单个体素异常值检测(SVOD)会遗漏那些通过剔除异常测量值方法能够识别的信号,即使多体素异常值检测(MVOD)能够识别这些信号。我们建议心脏扩散张量成像开始使用稳健估计来取代剔除异常测量值的方法。
Results
结果
3.1. Application to datasets
Fig. 2 shows global MD, FA, and absolute E2A, as fit to the originaldatasets, for the methods explained in Section 2.4. Table 1 showsthe group differences of the mean and median, and the 𝑝-value, forthe methods in Fig. 2. Table 1 shows that the group differences between Volunteers and HCM Patients was largest for MVOD methodsfor both MD and FA, and the significance was also higher (the 𝑝-valuewas lower). The SVOD methods showed the second largest differencebetween the groups for MD and FA, except for RWLS where shotrejection (WLS_SR) showed a slightly larger difference for mean MD(although the values are nearly identical) — note that difference ofmedians was nontheless much bigger for RWLS MD than for WLS_SRMD, and RWLS had nearly 6 times decrease in 𝑝-value compared toWLS_SR. It is visually clear that robust-fitting methods seem to reducethe spread of metric values in the healthy volunteers, especially for WLSmethods. Importantly for WLS, the 𝑝-value for MD does not pass thestandard significance test of 𝑝 < 0.05 at least without shot rejection,and the robust-fitting methods are much more significant still. For E2A,either SVOD or MVOD gave the largest group differences — there areseveral ties in the 𝑝-value due to the nature of the Wilcoxon signedrank test. Care should be taken to interpret the box-plots (dependingon whether points are classed as ‘fliers’, the box and whiskers will bedrawn differently, which can lead to discontinuous changes in the boxsizes). For WLS and WLS_SR methods, the box plot for volunteer E2Aseems narrower than for the robust methods, but in fact this is becausethe robust methods do not produce as many flier (out-lying) values ofE2A, so in this respect the ‘spread’ is reduced for robust methods.Figs. 3 and 4 show MD, FA, E2A and HA (helix angle) maps foran example volunteer and HCM patient respectively. These exampleswere the subjects with the largest MD values for the non-robust WLSmethods. Furthermore, even attempts at manual shot-rejection wereextremely difficult in these cases, since it was difficult to separate goodfrom bad images: even the better images appeared to contain large shotto-shot variations and corruptions at the sub-image level. Note that,we have shown all the myocardium in Figs. 3 and 4, although regionsof distortion and isolated artefacts were excluded from global metriccalculations, as explained in Appendix B.Fig. 3 shows a marked decrease in MD across the myocardium forrobust fitting compared to non-robust fitting (with or without shotrejection), especially around the septum. This decrease is slightly largerfor MVOD than SVOD, especially in the basal slice. The effects on FA areequivalent but in the opposite direction (an increase). The transmuralvariation of HA from right-handed (red) to left-handed (blue) is alsosuperior in MVOD, with the blue fibres in the bottom left of the midslice only convincingly recovered with MVOD. Additionally, SVOD andMVOD both show significantly more convincing transmural variationfrom red (right-handed) to green (circumferential) to blue (left-handed)in the septum of the basal slice, where the non-robust (with or withoutSR) methods show an extended region of red in the same area.Fig. 4 shows a strong increase in (magnitude of) E2A in the septumfor robust methods, particularly in the apical and basal slices. Thesechanges are also accompanied by a complete recovery of HA by robustfitting methods, whereas there are obvious corruptions of HA in bothnon-robust methods (including shot-rejection). Especially important isthe recovery of right-handed (red) HA in the septum of the basal slice,for both robust methods, whereas these right-handed fibres appearto be missing for not-robust methods. SVOD and MVOD appear todecrease MD substantially, moreso for MVOD than for SVOD.We reviewed differences in fitting methods for every subject byeye. Overall, the visual differences in diffusion measure maps betweenSVOD and MVOD seemed quite minor for most subjects. This seemsconsistent with Fig. 2 and Table 1: while MVOD modifies the results further in the ‘same direction’ in which SVOD improves uponshot-rejection, the improvement upon SVOD would appear relativelyminor in comparison to the improvement that SVOD makes over shotrejection.
3.1. 数据集应用 图2展示了按照第2.4节所解释的方法,对原始数据集进行拟合得到的整体平均扩散率(MD)、分数各向异性(FA)以及E2A的绝对值。表1显示了图2中各方法对应的组间均值差、中位数差以及(p)值。表1表明,对于平均扩散率(MD)和分数各向异性(FA)而言,在多体素异常值检测(MVOD)方法下,健康志愿者组和肥厚型心肌病(HCM)患者组之间的组间差异是最大的,并且其显著性也更高((p)值更低)。对于平均扩散率(MD)和分数各向异性(FA),单个体素异常值检测(SVOD)方法显示出的组间差异排在第二,不过对于稳健加权最小二乘法(RWLS)来说是个例外,在这种情况下,剔除异常测量值(WLS_SR)方法在平均扩散率(MD)均值上显示出稍大一点的差异(尽管这些数值几乎相同)—— 请注意,对于稳健加权最小二乘法(RWLS)下的平均扩散率(MD),其组间中位数差要比加权最小二乘法且剔除异常测量值(WLS_SR)下的大得多,并且与加权最小二乘法且剔除异常测量值(WLS_SR)相比,稳健加权最小二乘法(RWLS)的(p)值几乎降低到了六分之一。从视觉上明显可以看出,稳健拟合方法似乎减少了健康志愿者中指标值的离散程度,尤其是对于加权最小二乘法(WLS)而言。对于加权最小二乘法(WLS)来说重要的是,至少在不进行剔除异常测量值的情况下,平均扩散率(MD)的(p)值未通过(p < 0.05)的标准显著性检验,而稳健拟合方法的显著性仍然要高得多。对于E2A,单个体素异常值检测(SVOD)或多体素异常值检测(MVOD)都给出了最大的组间差异 —— 由于威尔科克森符号秩检验的性质,在(p)值方面存在一些相同的情况。在解释箱线图时应谨慎(根据点是否被归类为“离群值”,箱和须的绘制方式会有所不同,这可能会导致箱的大小出现不连续的变化)。对于加权最小二乘法(WLS)和加权最小二乘法且剔除异常测量值(WLS_SR)方法,健康志愿者E2A的箱线图看起来比稳健方法的要窄,但实际上这是因为稳健方法产生的E2A离群值(异常值)没有那么多,所以从这个方面来看,稳健方法减少了数据的“离散程度”。 图3和图4分别展示了一名健康志愿者和一名肥厚型心肌病(HCM)患者示例的平均扩散率(MD)、分数各向异性(FA)、E2A以及螺旋角(HA)图。这些示例是在非稳健加权最小二乘法(WLS)下平均扩散率(MD)值最大的受试者。此外,在这些情况下,即使尝试进行人工剔除异常测量值也极其困难,因为很难区分好图像和坏图像:即使是较好的图像似乎在子图像层面也存在较大的图像间差异和损坏。请注意,如图3和图4所示,我们展示了整个心肌区域,不过正如附录B中所解释的,在计算整体指标时,已将失真区域和孤立的伪影区域排除在外。 图3显示,与非稳健拟合(无论是否进行剔除异常测量值)相比,稳健拟合下整个心肌区域的平均扩散率(MD)显著降低,尤其是在室间隔周围。多体素异常值检测(MVOD)方法下的这种降低幅度比单个体素异常值检测(SVOD)方法稍大,尤其是在基底切片处。对分数各向异性(FA)的影响是类似的,但方向相反(增加)。在多体素异常值检测(MVOD)方法下,螺旋角(HA)从右手螺旋(红色)到左手螺旋(蓝色)的透壁变化也更优,只有在多体素异常值检测(MVOD)方法下,中间切片左下角的蓝色纤维才能令人信服地恢复。此外,在基底切片的室间隔处,单个体素异常值检测(SVOD)和多体素异常值检测(MVOD)都显示出从红色(右手螺旋)到绿色(圆周方向)再到蓝色(左手螺旋)的更令人信服的透壁变化,而在相同区域,非稳健方法(无论是否进行剔除异常测量值(SR))都显示出一片延伸的红色区域。 图4显示,对于稳健方法,室间隔处E2A(的绝对值)大幅增加,尤其是在心尖和基底切片处。这些变化还伴随着稳健拟合方法对螺旋角(HA)的完全恢复,而两种非稳健方法(包括剔除异常测量值)下的螺旋角(HA)都存在明显的损坏。特别重要的是,对于两种稳健方法,基底切片室间隔处右手螺旋(红色)的螺旋角(HA)都得到了恢复,而对于非稳健方法,这些右手螺旋纤维似乎缺失了。单个体素异常值检测(SVOD)和多体素异常值检测(MVOD)似乎都大幅降低了平均扩散率(MD),并且多体素异常值检测(MVOD)的降低幅度比单个体素异常值检测(SVOD)更大。 我们通过肉眼观察了每个受试者在拟合方法上的差异。总体而言,对于大多数受试者来说,单个体素异常值检测(SVOD)和多体素异常值检测(MVOD)在扩散指标图上的视觉差异似乎相当小。这似乎与图2和表1是一致的:虽然多体素异常值检测(MVOD)在单个体素异常值检测(SVOD)相对于剔除异常测量值有所改进的“相同方向”上进一步修改了结果,但与单个体素异常值检测(SVOD)相对于剔除异常测量值的改进相比,多体素异常值检测(MVOD)相对于单个体素异常值检测(SVOD)的改进似乎相对较小。
Figure
图

Fig. 1. Examples from 6 datasets (1 per row in each sub-figure): (a) examples where shot-rejection has (correctly) identified a corrupted image, but SVOD has not identified allmyocardial voxels in the corrupted image; (b) examples where shot-rejection has not identified a corrupted image. The ‘reference’ image shows a typical ‘good image’, while the‘accepted’ or ‘rejected’ image columns show a different image with the same diffusion weighting for the same subject. The myocardial segmentation is also shown. For SVOD andMVOD columns, black/white voxels indicate outlier/non-outlier signals respectively
图1:来自6个数据集的示例(每个子图中每行1个示例):(a)剔除异常测量值(SR)方法已(正确地)识别出损坏图像,但单个体素异常值检测(SVOD)方法未能识别出该损坏图像中所有心肌体素的示例;(b)剔除异常测量值(SR)方法未识别出损坏图像的示例。“参考” 图像展示了一幅典型的 “好图像”,而 “接受” 或 “拒绝” 图像列展示了同一受试者具有相同扩散加权的不同图像。同时还展示了心肌分割结果。对于单个体素异常值检测(SVOD)和多体素异常值检测(MVOD)列,黑色/白色体素分别表示异常值/非异常值信号。

Fig. 2. Diffusion measures MD (×10−3 mm2/s), FA, and absolute E2A (degrees) for volunteers and HCM patients for different fitting methods.
图2:不同拟合方法下,志愿者和肥厚型心肌病(HCM)患者的扩散指标:平均扩散率(MD,单位:×10⁻³ mm²/s)、分数各向异性(FA)以及E2A的绝对值(单位:度)。
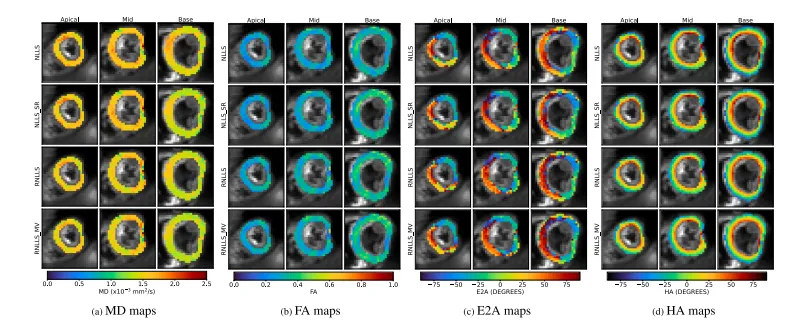
Fig. 3. Example healthy volunteer (highest MD from non-robust WLS fitting in the HV group of Fig. 2). First row: non-robust NLLS; Second row: non-robust NLLS after shot-rejection;Third row: robust NLLS with SVOD; Fourth row: robust NLLS with SVOD and MVOD (10 voxel neighbourhood).
图3:健康志愿者示例(在图2的健康志愿者(HV)组中,来自非稳健加权最小二乘法(WLS)拟合且平均扩散率(MD)值最高的情况)。第一行:非稳健非线性最小二乘法(NLLS);第二行:剔除异常测量值(SR)后的非稳健非线性最小二乘法(NLLS);第三行:采用单个体素异常值检测(SVOD)的稳健非线性最小二乘法(NLLS);第四行:采用单个体素异常值检测(SVOD)和多体素异常值检测(MVOD,10个体素邻域)的稳健非线性最小二乘法(NLLS)。
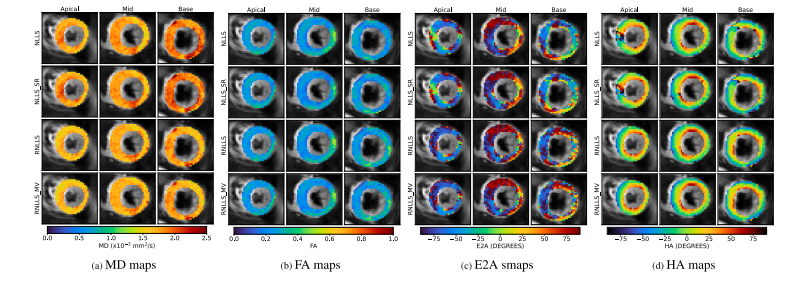
Fig. 4. Example HCM patient (highest MD from non-robust WLS fitting in the HCM group of Fig. 2). First row: non-robust NLLS; Second row: non-robust NLLS after shot-rejection;Third row: robust NLLS with SVOD; Fourth row: robust NLLS with SVOD and MVOD (10 voxel neighbourhood).
图4:肥厚型心肌病(HCM)患者示例(在图2的HCM组中,来自非稳健加权最小二乘法(WLS)拟合且平均扩散率(MD)值最高的情况)。第一行:非稳健非线性最小二乘法(NLLS);第二行:剔除异常测量值(SR)后的非稳健非线性最小二乘法(NLLS);第三行:采用单个体素异常值检测(SVOD)的稳健非线性最小二乘法(NLLS);第四行:采用单个体素异常值检测(SVOD)和多体素异常值检测(MVOD,10个体素邻域)的稳健非线性最小二乘法(NLLS)。

Fig. 5. RMSE of fitting residuals, excluding identified outliers or excluded images (asapplied). RMSE is lower and more uniform for robust fitting methods, being lower forMVOD than SVOD, with remaining high RMSE regions seeming to indicate patches ofpersistent artefact across the image series.
图5:拟合残差的均方根误差(RMSE),已排除已识别的异常值或已排除的图像(按实际应用情况)。对于稳健拟合方法而言,均方根误差更低且更为均匀,多体素异常值检测(MVOD)方法所得的均方根误差比单个体素异常值检测(SVOD)方法的要低,而剩余的均方根误差较高的区域似乎表明在整个图像序列中存在持续的伪影区域。

Fig. 6. Global diffusion measures MD (×10−3 mm2/s), FA, and absolute E2A (degrees) for synthetically corrupted data. Each sub-plot corresponds to a different corruption type.Different percentages of images have been corrupted, and different SNRs have been used to generate Rician error. The dotted line extending across each plot is the ‘‘syntheticground truth’’ from which synthetic data (with noise and corruptions) was generated, whereas the darker solid lines are the mean of non-robust fits excluding the images thatwere artificially corrupted. The box-and-whisker plots represent 10 synthetic datasets per corruption configuration (for narrow box-plots, the median line has been removed forclarity). Different colours correspond to different fitting methods, shown in the legend. For each corruption configuration, NLLS and WLS methods are shown to the left and rightagainst a differently shaded background
图6:人工损坏数据的整体扩散指标,包括平均扩散率(MD,单位:×10⁻³ mm²/s)、分数各向异性(FA)以及E2A的绝对值(单位:度)。每个子图对应一种不同的损坏类型。已对不同百分比的图像进行了损坏处理,并使用了不同的信噪比(SNR)来生成瑞利误差。贯穿每个子图的虚线是生成人工数据(包含噪声和损坏)所依据的 “人工合成的真实值”,而较深的实线是排除了人工损坏图像后的非稳健拟合的平均值。箱线图表示每种损坏配置下的10个人工合成数据集(对于较窄的箱线图,为清晰起见已去除了中位数线)。不同颜色对应不同的拟合方法,如图例所示。对于每种损坏配置,非线性最小二乘法(NLLS)和加权最小二乘法(WLS)分别显示在背景颜色不同的左右两侧。

Fig. 7. RMSE of global diffusion measures of MD (×10−3 mm2/s), FA, and absolute E2A (degrees) for synthetically corrupted data. Each sub-plot corresponds to a different corruptiontype. Different percentages of images have been corrupted, and different SNRs have been used to generate Rician error. The RMSE is calculated against the mean of non-robustfits excluding the images that were artificially corrupted. The box-and-whisker plots represent the RMSE scores of all subjects (for narrow box-plots, the median line has beenremoved for clarity). Different colours correspond to different fitting methods, shown in the legend. For each corruption configuration, NLLS and WLS methods are shown to theleft and right against a differently shaded background.
图7:人工损坏数据的整体扩散指标(平均扩散率(MD,单位:×10⁻³ mm²/s)、分数各向异性(FA)以及E2A绝对值(单位:度))的均方根误差(RMSE)。每个子图对应一种不同的损坏类型。不同百分比的图像已被损坏,并且使用了不同的信噪比(SNR)来生成瑞利误差。均方根误差是相对于排除了人工损坏图像后的非稳健拟合的平均值计算得出的。箱线图表示所有对象的均方根误差得分(对于较窄的箱线图,为清晰起见已移除了中位数线)。不同颜色对应不同的拟合方法,如图例所示。对于每种损坏配置,非线性最小二乘法(NLLS)和加权最小二乘法(WLS)方法分别在背景颜色不同的左侧和右侧展示。
Table
表

Table 1Table of difference of group means, medians, and p-values, for MD, FA, absolute E2A, for several tested methods. Within each methodcategory (either NLLS or WLS) the largest difference of means and medians are shown in red, and the lowest 𝑝-value is shown in blue.
表1:针对几种测试方法,关于平均扩散率(MD)、分数各向异性(FA)、E2A绝对值的组间均值差、中位数差以及(p)值的表格。在每个方法类别(无论是非线性最小二乘法(NLLS)还是加权最小二乘法(WLS))中,均值差和中位数差的最大值以红色显示,最小的(p)值以蓝色显示。