Title
题目
MoMA: Momentum contrastive learning with multi-head attention-based knowledge distillation for histopathology image analysis
MoMA:用于组织病理学图像分析的基于多头注意力知识蒸馏的动量对比学习方法
01
文献速递介绍
计算病理学是一门新兴学科,最近它在提高传统病理学的准确性和稳健性方面展现出了巨大的潜力,进而提升了患者护理、治疗和管理的质量(崔和张,2021年)。由于先进的人工智能(AI)和机器学习(ML)技术的发展,以及高质量、高分辨率数据集的可得性,计算病理学方法已成功应用于传统病理学日常工作流程的各个方面,从细胞核检测(格雷厄姆等人,2019年)、组织分类(马里尼等人,2021年)、疾病分层(春杜鲁等人,2022年)到生存分析(黄等人,2021年;李等人,2023年)。 然而,最近的研究指出,计算病理学工具的泛化性问题仍然没有得到解决(斯塔克等人,2020年;奥布雷维尔等人,2023年)。 为了构建准确可靠的计算病理学工具,不仅需要先进的人工智能模型,还需要大量的高质量数据。在计算病理学领域,近年来人工智能和机器学习技术的学习能力以及可用的病理学数据集的数量都在不断增加。然而,公开可用的数据集数量远远少于自然语言处理(NLP)(戈尔巴尼等人,2022年)和计算机视觉(翟等人,2022年;德赫加尼等人,2023年)等其他学科中的数据集数量。部分原因在于病理学数据集的特性,其中包含数十亿像素的全切片图像(WSIs),因此很难在全球范围内透明地共享这些数据,同时也因为患者数据存在隐私和伦理问题。此外,病理学数据集的多样性也受到限制。例如,Kather19(卡瑟等人,2019a)包含10万个属于9种不同结直肠组织类型的图像块。这10万个图像块最初仅来自86张图像。GLySAC(多安等人,2022年)包含来自59个胃图像块的3种不同细胞类型的30875个细胞核。这些是从使用单个数字切片扫描仪数字化的8张全切片图像中制备的。数据集中扫描仪的多样性不足也阻碍了计算病理学中人工智能模型的泛化性(斯塔克等人,2020年)。实际上,已经有人努力提供大量多样的病理学数据集。例如,PANDA(布尔顿等人,2022年)是一个用于前列腺癌格里森分级的数据集,其中包括来自6个机构的12625张全切片图像,这些图像是使用3种不同的数字切片扫描仪扫描得到的。然而,当涉及到特定的计算病理学任务时,获取或访问足够数量的多样数据集仍然具有挑战性。 无论以何种方式收集此类数据集都既耗时又耗力。因此,计算病理学在开发针对特定任务的模型和工具方面存在尚未满足的需求。 迁移学习是最广泛使用的学习方法之一,它通过重新利用或迁移从一个问题/任务中获得的知识到其他问题/任务,来克服数据集不足的问题。尽管迁移学习在病理学图像分析和其他学科中已取得成功并被广泛采用,但之前的大多数研究使用的是从自然图像(如ImageNet或JFT)中预训练的权重(侯赛因扎德·塔赫尔等人,2021年;多索维茨基等人,2021年)。最近的一项研究表明,从这些自然图像中学习到的现成特征对计算病理学任务是有用的,但可迁移知识的量,即迁移学习的有效性在很大程度上取决于病理学图像的复杂性/类型,这很可能是由于图像内容和统计数据的差异(李和普拉塔尼奥蒂斯,2020年)。随着公开可用的病理学图像数据集数量的增加,来自此类病理学图像数据集的预训练权重可能会用于迁移学习;然而,目前尚不清楚这些数据集的数量是否足够大,或者多样性是否足够丰富。 人们普遍认为,病理学图像之间存在很大的内部和相互差异。因此,迁移学习的有效性可能仍然会因数据集的特征而有所不同。 此外,由辛顿等人(2015年)提出的知识蒸馏(KD)是另一种可以克服合适数据集不足问题的方法。它不仅将现有模型用作预训练权重(类似于迁移学习),而且还迫使目标(学生)模型直接从现有(教师)模型中学习,也就是说,学生模型在整个训练过程中试图模仿教师模型的输出。知识蒸馏的各种变体已成功应用于各种任务,例如模型压缩(田等人,2020年)、跨模态知识迁移(袁等人,2022年;艾哈迈德等人,2022年;赵等人,2020年)或集成蒸馏(杜等人,2020年;林等人,2020年;艾伦 - 朱和李,2023年)。然而,它在模型之间转移知识方面,尤其是在病理学图像分析中,尚未得到充分探索。 在此,我们试图解决如何克服计算病理学领域中数据和注释有限的挑战这一问题,最终目标是构建能够准确且稳健地应用于未知数据的计算病理学工具。为了实现这一目标,我们提出了一个高效且有效的学习框架,该框架可以利用基于高质量源数据集构建的现有模型,并在相对较小的数据集上学习一个目标模型。所提出的方法,即所谓的基于多头注意力知识蒸馏的动量对比学习(MoMA),遵循知识蒸馏的框架,用于从现有模型中转移相关知识,并采用动量对比学习和注意力机制来获得一致、可靠且具有上下文感知的特征表示。我们在不同设置下的多组织病理学数据集上评估MoMA,以模拟计算病理学工具研发中的实际场景。与其他方法相比,MoMA在为特定任务学习目标模型方面表现出卓越的能力。此外,实验结果为更好地将知识从预训练模型转移到在有限目标数据集上训练的学生模型提供了指导。 我们的主要贡献总结如下: - 我们开发了一个高效且有效的学习框架,即MoMA,它可以利用现有模型,在高质量数据集上进行训练,并有助于在有限数据集上构建准确且稳健的计算病理学工具。 - 我们提议将基于注意力的动量对比学习用于知识蒸馏,以便以一致且可靠的方式将知识从现有模型转移到目标模型。 - 我们在多组织病理学数据集上评估了MoMA,并且在为特定任务学习目标模型方面优于其他相关研究。 - 我们在各种设置下研究和分析了MoMA以及其他相关研究,并在可用数据集有限的情况下,为计算病理学工具的开发提供了指导。
Aastract
摘要
There is no doubt that advanced artificial intelligence models and high quality data are the keys to success indeveloping computational pathology tools. Although the overall volume of pathology data keeps increasing,a lack of quality data is a common issue when it comes to a specific task due to several reasons includingprivacy and ethical issues with patient data. In this work, we propose to exploit knowledge distillation, i.e.,utilize the existing model to learn a new, target model, to overcome such issues in computational pathology.Specifically, we employ a student–teacher framework to learn a target model from a pre-trained, teachermodel without direct access to source data and distill relevant knowledge via momentum contrastive learningwith multi-head attention mechanism, which provides consistent and context-aware feature representations.This enables the target model to assimilate informative representations of the teacher model while seamlesslyadapting to the unique nuances of the target data. The proposed method is rigorously evaluated across differentscenarios where the teacher model was trained on the same, relevant, and irrelevant classification tasks withthe target model. Experimental results demonstrate the accuracy and robustness of our approach in transferringknowledge to different domains and tasks, outperforming other related methods. Moreover, the results providea guideline on the learning strategy for different types of tasks and scenarios in computational pathology
毫无疑问,先进的人工智能模型和高质量的数据是开发计算病理学工具取得成功的关键。尽管病理学数据的总体数量在不断增加,但由于包括患者数据的隐私和伦理问题等多种原因,在处理特定任务时,缺乏高质量数据仍是一个普遍存在的问题。 在这项工作中,我们提议利用知识蒸馏技术,即利用现有的模型来学习一个新的目标模型,以克服计算病理学中存在的此类问题。具体而言,我们采用师生框架,在不直接访问源数据的情况下,从一个预训练的教师模型中学习一个目标模型,并通过基于多头注意力机制的动量对比学习来提取相关知识,这种机制能够提供一致且具有上下文感知能力的特征表示。 这使得目标模型能够吸收教师模型中富含信息的特征表示,同时无缝地适应目标数据的独特细微差异。我们在不同的场景下对所提出的方法进行了严格评估,在这些场景中,教师模型针对与目标模型相同、相关或不相关的分类任务进行了训练。 实验结果证明了我们的方法在将知识迁移到不同领域和任务时的准确性和鲁棒性,其性能优于其他相关方法。此外,这些结果为计算病理学中不同类型的任务和场景的学习策略提供了指导。
Method
方法
3.1. Problem formulation
The overview of the proposed MoMA is shown in Fig. 1 and Alg. 1in Appendix A. Let 𝐷𝑆𝐶 = {(𝐱𝑖 , 𝐲𝑖 )}𝑁 𝑖=1 𝑆𝐶 be a source/teacher dataset and𝐷𝑇 𝐺 = {(𝐱𝑖 , 𝐲𝑖 )}𝑁 𝑖=1 𝑇 𝐺 be a target/student dataset where 𝐱𝑖 and 𝐲𝑖 represent the 𝑖th pathology image and its ground truth label, respectively,and 𝑁𝑆𝐶 and 𝑁𝑇 𝐺 represent the number of source and target samples(𝑁𝑆𝐶 ≫ 𝑁𝑇 𝐺), respectively. The source/teacher dataset refers to thedataset that is utilized to train a teacher model and the target/studentdataset denotes the dataset that is employed to learn a target/studentmodel. Let 𝑇 be a teacher model and 𝑆 be a student model. 𝑇consists of a teacher encoder 𝑓 𝑇 and a teacher classifier 𝑔 𝑇 . 𝑆 includesa student encoder 𝑓 𝑆 and a student classifier 𝑔 𝑆. In addition to 𝑇 and 𝑆, MoMA includes a teacher projection head (𝑝 𝑇 ), a teacher attentionhead (ℎ 𝑇 ), a student projection head (𝑝 𝑆), and a student attentionhead (ℎ 𝑆). Given an input image 𝐱𝑖 , 𝑓 𝑇 and 𝑓 𝑆 extracts initial featurerepresentations, each of which is subsequently processed by a series ofa projection head and an attention head, i.e., 𝑝 𝑇 followed by ℎ 𝑇 or ?followed by ℎ 𝑆, to improve its representation power. 𝑔 𝑇 and 𝑔 𝑆 receivethe initial feature representations and conduct image classification. 𝑔 𝑇is only utilized during the training of 𝑇 .
3.1. 问题公式化表述
所提出的MoMA方法概述如图1以及附录A中的算法1所示。设(\mathcal{D}{SC} = {(\mathbf{x}i, \mathbf{y}i)}{i = 1}^{N{SC}})为源数据集(教师数据集),(\mathcal{D}{TG} = {(\mathbf{x}i, \mathbf{y}i)}{i = 1}^{N{TG}})为目标数据集(学生数据集),其中(\mathbf{x}i)和(\mathbf{y}i)分别表示第(i)张病理学图像及其真实标签,(N{SC})和(N{TG})分别表示源样本数量和目标样本数量((N{SC} \gg N{TG}))。源数据集(教师数据集)是指用于训练教师模型的数据集,而目标数据集(学生数据集)是指用于学习目标模型(学生模型)的数据集。 设(\mathcal{F}T)为教师模型,(\mathcal{F}S)为学生模型。(\mathcal{F}T)由教师编码器(f_T)和教师分类器(g_T)组成。(\mathcal{F}S)包括学生编码器(f_S)和学生分类器(g_S)。除了(\mathcal{F}T)和(\mathcal{F}S)之外,MoMA还包括一个教师投影头((p_T))、一个教师注意力头((h_T))、一个学生投影头((p_S))和一个学生注意力头((h_S))。 给定一张输入图像(\mathbf{x}i),(f_T)和(f_S)会提取初始特征表示,随后每个初始特征表示都会经过一系列的投影头和注意力头的处理,即先经过(p_T)再经过(h_T),或者先经过(p_S)再经过(h_S),以提升其特征表示能力。(g_T)和(g_S)接收初始特征表示并进行图像分类。(g_T)仅在(\mathcal{F}T)的训练过程中使用。
Conclusion
结论
Herein, we propose an efficient and effective learning frameworkcalled MoMA to build an accurate and robust classification modelin pathology images. Exploiting the KD framework, momentum contrastive learning, and SA, MoMA was able to transfer knowledge froma source domain to a target domain and to learn a robust classificationmodel for five different tasks. Moreover, the experimental results ofMoMA suggest an adequate learning strategy for different distillationtasks and scenarios. We anticipate that this will be a great help indeveloping computational pathology tools for various tasks. Futurestudies will entail the further investigation of the efficient KD methodand extended validation and application of MoMA to other types ofdatasets and tasks in computational pathology.
在此,我们提出了一个高效且有效的学习框架,名为MoMA,用于在病理学图像中构建准确且稳健的分类模型。通过利用知识蒸馏(KD)框架、动量对比学习以及自注意力机制(SA),MoMA能够将知识从源领域转移到目标领域,并针对五种不同的任务学习到一个稳健的分类模型。 此外,MoMA的实验结果为不同的蒸馏任务和场景提供了合适的学习策略。我们预计,这将对开发适用于各种任务的计算病理学工具提供极大的帮助。 未来的研究将包括进一步探究高效的知识蒸馏方法,以及将MoMA在计算病理学领域中扩展到其他类型的数据集和任务上进行验证和应用。
Results
结果
5.1. Same task distillation: prostate cancer classification
Table 1 and Fig. 3 (and Figs. C.1 and C.2 in Appendix C) show theresults of MoMA and its competitors on the two TMA prostate datasets(Prostate USZ and Prostate UBC). On Prostate USZ, the teacher modelTC𝑃 𝐴𝑁𝐷𝐴, which was trained on PANDA only, achieved 63.4% ACC,0.526 F1, and 0.531 𝜅𝑤*, which is substantially lower to other studentmodels with 𝑇 𝐿, 𝐿𝐷, and 𝐹𝐷. Among the student models with 𝑇 𝐿, thestudent model with no pre-trained weights (FT𝑁𝑜𝑛𝑒) was inferior to theother two student models; the student model pre-trained on PANDA(FT𝑃 𝐴𝑁𝐷𝐴) outperformed the student model pre-trained on ImageNet(FT𝐼𝑚𝑎𝑔𝑒𝑁𝑒𝑡). These indicate the importance of pre-trained weights andfine-tuning on the target dataset, i.e., Prostate USZ. As for the KDapproaches, MoMA𝑃 𝐴𝑁𝐷𝐴, pre-trained on PANDA, outperformed allother KD methods, achieving ACC of 73.6%, which is 0.9% higher thanFT𝑃 𝐴𝑁𝐷𝐴, and F1 of 0.687 and 𝜅**𝑤 of 0.670, which are comparable tothose of FT𝑃 𝐴𝑁𝐷𝐴.
On the independent test set, Prostate UBC, it is remarkable thatTC𝑃 𝐴𝑁𝐷𝐴 achieved 78.2% ACC and 0.680 𝜅**𝑤, which are superior tothose of all the student models with 𝑇 𝐿, likely suggesting that thecharacteristic of PANDA is more similar to Prostate UBC than ProstateUSZ. The performance of the student models with 𝑇 𝐿 and 𝐹𝐷 wassimilar to each other between Prostate USZ and Prostate UBC; forinstance, MoMA𝑃 𝐴𝑁𝐷𝐴 obtained higher ACC but lower F1 and 𝜅**𝑤 onProstate UBC than on Prostate USZ. As MoMA and other student modelswith 𝐹𝐷 adopt vanilla KD by setting 𝛾 to 1 in , i.e., mimicking theoutput logits of the teacher model, there was, in general, a substantialincrease in the performance on Prostate UBC. MoMA𝑃 𝐴𝑁𝐷𝐴, in particular, achieved the highest ACC of 83.3% and 𝜅𝑤 of 0.763 overall modelsunder consideration, which are 11.1% and 0.145 higher than those onProstate USZ in ACC and 𝜅𝑤, respectively.
By randomly sampling 25% and 50% of the training set, we repeatedthe above experiments using MoMA and other competing models toassess the effect of the size of the training set. The results of the sametask distillation using 25% and 50% of the training set are availablein Appendix B (Tables B.1 and B.2). The experimental results were moreor less the same as those using the entire training set. MoMA𝑃 𝐴𝑁𝐷𝐴 wascomparable to FT𝑃 𝐴𝑁𝐷𝐴 on Prostate USZ. KL+MoMA𝑃 𝐴𝑁𝐷𝐴 outperformed the competing models on Prostate UBC. These results validatethe effectiveness of MoMA on the extremely small target dataset.
5.1 相同任务蒸馏:前列腺癌分类 表1和图3(以及附录C中的图C.1和图C.2)展示了MoMA模型及其竞争模型在两个组织微阵列(TMA)前列腺数据集(瑞士苏黎世大学前列腺数据集Prostate USZ和英属哥伦比亚大学前列腺数据集Prostate UBC)上的实验结果。在Prostate USZ数据集上,仅在PANDA数据集上训练的教师模型TCPANDA,达到了63.4%的准确率(ACC)、0.526的F1值和0.531的加权卡帕系数((\kappa_w)),这明显低于其他采用了迁移学习((TL))、标签蒸馏((LD))和特征蒸馏((FD))的学生模型。在采用了迁移学习((TL))的学生模型中,没有预训练权重的学生模型(FTNone)比另外两个学生模型表现差;在PANDA数据集上预训练的学生模型(FTPANDA)优于在ImageNet数据集上预训练的学生模型(FTImageNet)。这些结果表明了预训练权重以及在目标数据集(即Prostate USZ数据集)上进行微调的重要性。至于知识蒸馏(KD)方法,在PANDA数据集上预训练的MoMAPANDA模型优于所有其他知识蒸馏方法,达到了73.6%的准确率,比FTPANDA模型高出0.9%,F1值为0.687,加权卡帕系数(\kappa_w)为0.670,与FTPANDA模型的相应值相当。 在独立测试集Prostate UBC上,值得注意的是,TCPANDA模型达到了78.2%的准确率和0.680的加权卡帕系数(\kappa_w),优于所有采用迁移学习((TL))的学生模型,这很可能表明PANDA数据集的特征与Prostate UBC数据集的相似度要高于与Prostate USZ数据集的相似度。采用了迁移学习((TL))和特征蒸馏((FD))的学生模型在Prostate USZ数据集和Prostate UBC数据集上的表现相似;例如,MoMAPANDA模型在Prostate UBC数据集上的准确率比在Prostate USZ数据集上更高,但F1值和加权卡帕系数(\kappa_w)更低。由于MoMA模型和其他采用特征蒸馏((FD))的学生模型通过在损失函数(\mathcal{L})中设置(\gamma = 1)来采用普通的知识蒸馏方法,即模仿教师模型的输出对数几率(logits),所以在Prostate UBC数据集上的性能总体上有了显著提升。特别是MoMAPANDA模型,在所有考虑的模型中达到了最高的83.3%的准确率和0.763的加权卡帕系数(\kappa_w),分别比在Prostate USZ数据集上的准确率和加权卡帕系数(\kappa_w)高出11.1%和0.145。 通过随机抽取训练集的25%和50%,我们使用MoMA模型和其他竞争模型重复了上述实验,以评估训练集规模的影响。使用训练集的25%和50%进行相同任务蒸馏的结果见附录B(表B.1和表B.2)。实验结果与使用整个训练集的结果大致相同。在Prostate USZ数据集上,MoMAPANDA模型与FTPANDA模型表现相当。在Prostate UBC数据集上,KL+MoMAPANDA模型优于其他竞争模型。这些结果验证了MoMA模型在极小的目标数据集上的有效性。
Figure
图
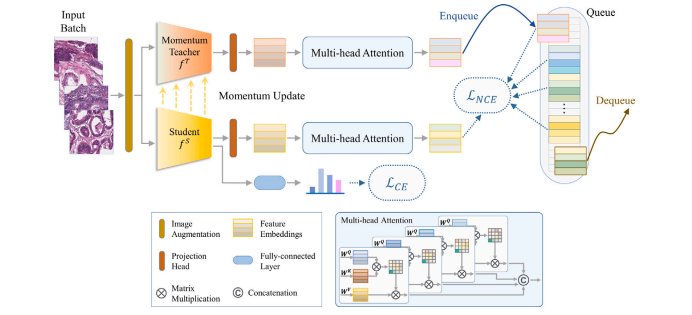
Fig. 1. Overview of the MoMA: Attention-augmented momentum contrast knowledge distillation framework. A batch of input images is encoded by the student encoder (𝑓 𝑆 ), andthe momentum teacher (𝑓 𝑇 ), and each feature representation is re-weighted with regard to other images in the batch as the context. A classifier is added on top of the studentencoder. The student model is jointly optimized by contrastive loss and cross-entropy loss
图1:MoMA概述:注意力增强的动量对比知识蒸馏框架。一批输入图像由学生编码器(𝑓 𝑆 )和动量教师编码器(𝑓 𝑇 )进行编码,并且每个特征表示都根据批次中的其他图像作为上下文重新赋予权重。在学生编码器的顶部添加了一个分类器。学生模型通过对比损失和交叉熵损失进行联合优化。
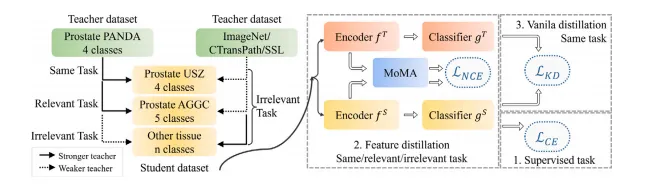
Fig. 2. Overview of distillation flow across different tasks and datasets. (1) Supervised task is always conducted, (2) Feature distillation is applied if a well-trained teacher modelis available, and (3) Vanilla 𝐿𝐾𝐷 is employed if teacher and student models conduct the same task. SSL stands for self-supervised learning
图2:不同任务和数据集之间的蒸馏流程概述。(1)监督学习任务始终会进行;(2)如果有一个训练良好的教师模型可用,就会应用特征蒸馏;(3)如果教师模型和学生模型执行相同的任务,就会采用普通的知识蒸馏损失(𝐿𝐾𝐷)。SSL代表自监督学习。
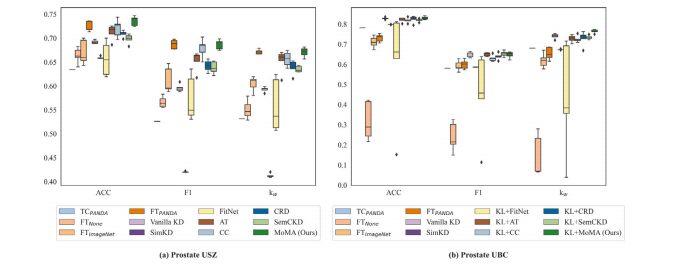
Fig. 3. Box plots for same task distillation: All the KD models utilize the pre-trained weights from PANDA.
图3:相同任务蒸馏的箱线图:所有的知识蒸馏(KD)模型均使用了来自PANDA数据集的预训练权重。
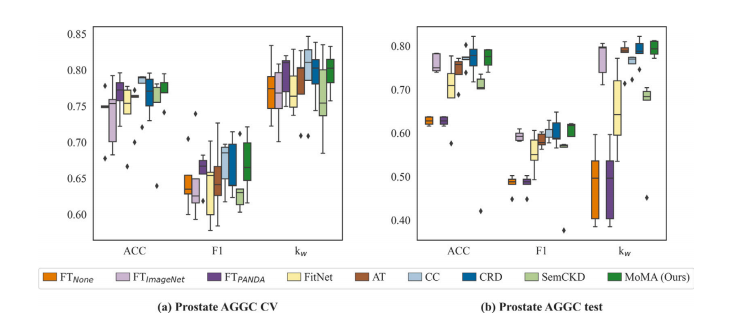
Fig. 4. Box plots for relevant task distillation. All the KD models utilize the pre-trained weights from PANDA.
图4:相关任务知识蒸馏的箱线图。所有的知识蒸馏(KD)模型都使用了来自PANDA数据集的预训练权重。
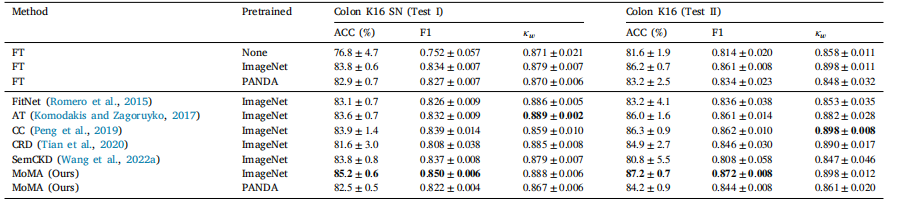
Fig. 5. Bar plots for irrelevant task distillation. All the KD models utilize the pre-trained weights from ImageNet
图5:不相关任务知识蒸馏的柱状图。所有的知识蒸馏(KD)模型都使用了来自ImageNet的预训练权重。
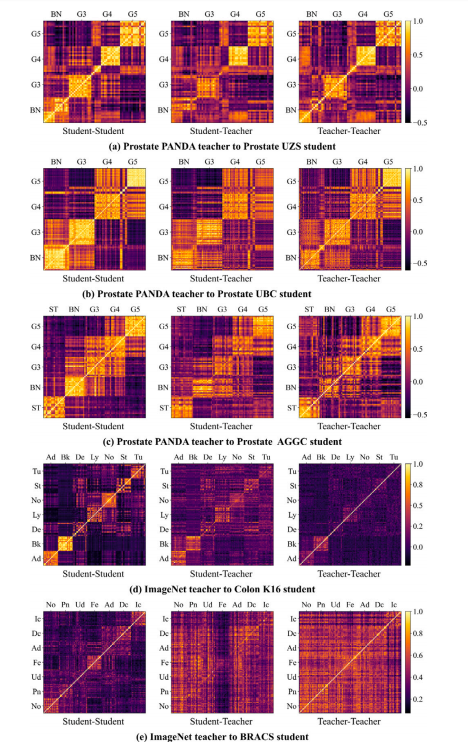
Fig. 6. The correlation coefficient matrix between feature presentations of a teachernetwork and student network.
图6:教师网络与学生网络的特征表示之间的相关系数矩阵。
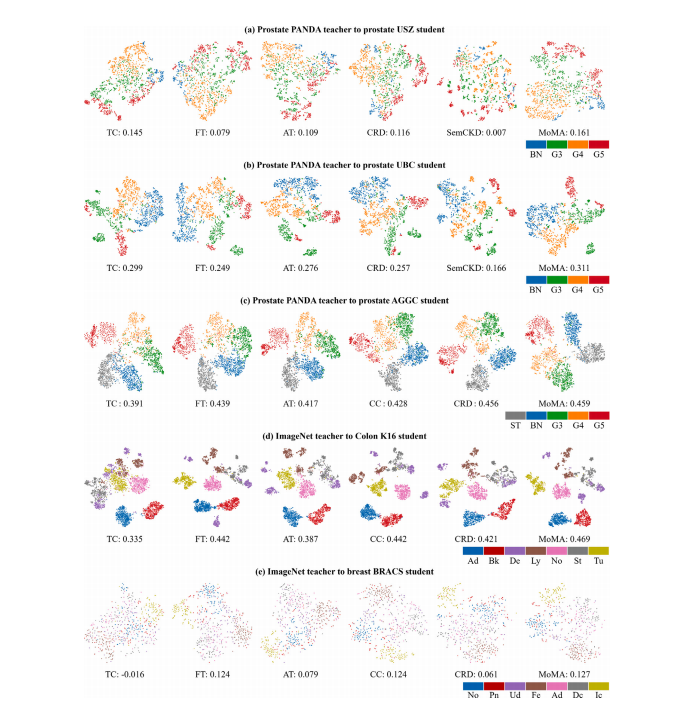
Fig. 7. t-SNE visualization of feature representations with silhouette scores for ImageNet and PANDA teacher models and 5 student datasets: (a) Prostate USZ, (b) Prostate UBC,© Prostate AGGC, (d) Colon K16, (e) Breast BRACS
图7:针对ImageNet和PANDA教师模型以及5个学生数据集的特征表示的t-SNE可视化(带轮廓系数):(a) 前列腺USZ数据集,(b) 前列腺UBC数据集,© 前列腺AGGC数据集,(d) 结肠K16数据集,(e) 乳腺癌BRACS数据集 。
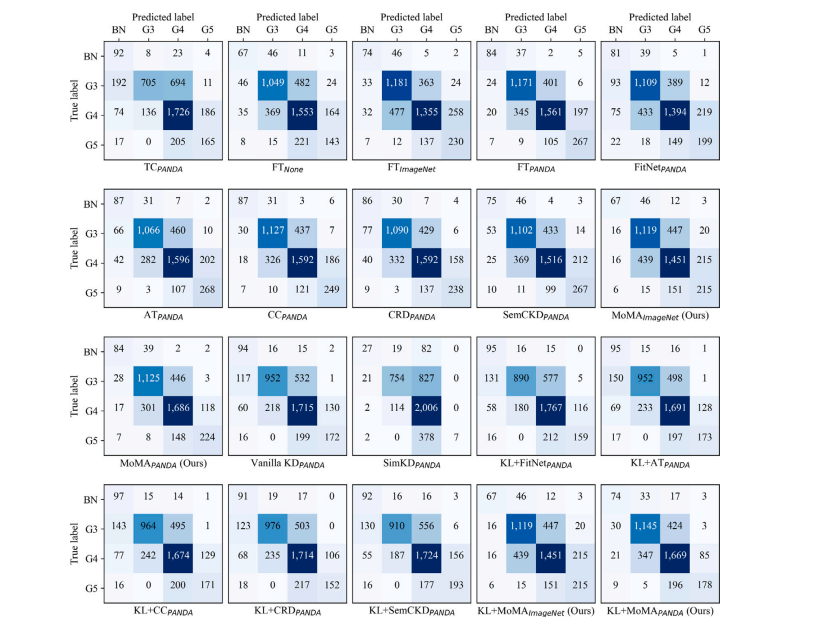
Fig. C.1. Confusion matrices on Prostate USZ (Test I). Each confusion matrix represents the average across 5 runs.
图C.1:前列腺USZ数据集(测试I)上的混淆矩阵。每个混淆矩阵表示5次运行的平均值。
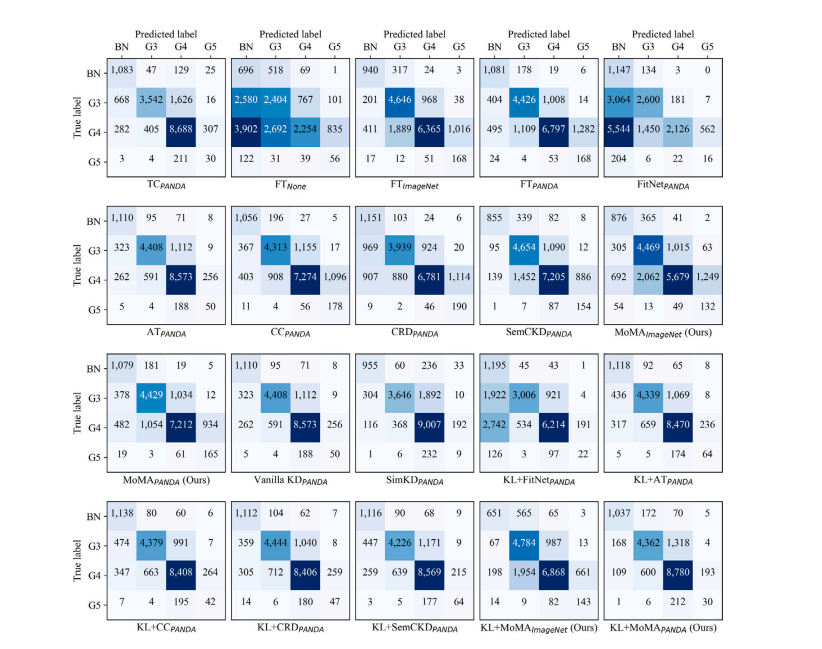
Fig. C.2. Confusion matrices on Prostate UBC (Test II). Each confusion matrix represents the average across 5 runs.
图C.2:前列腺UBC数据集(测试II)上的混淆矩阵。每个混淆矩阵代表五次运行结果的平均值。
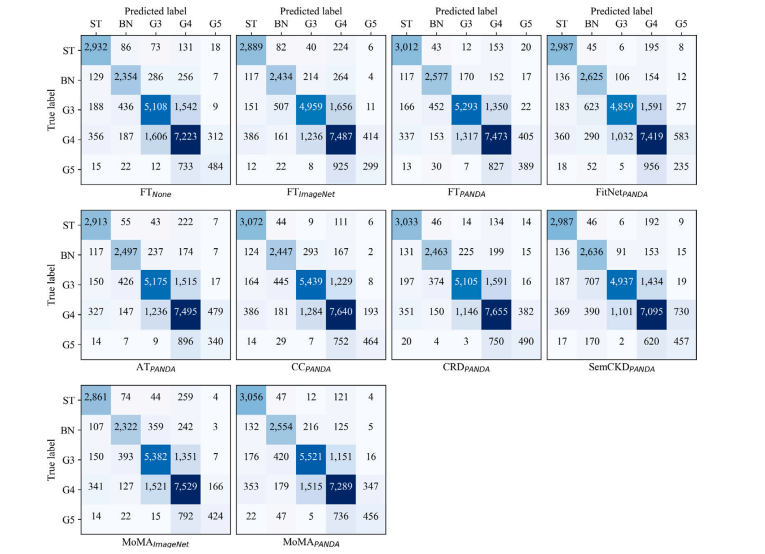
Fig. C.3. Confusion matrices on Prostate AGGC CV (Test I). Each confusion matrix represents the average across 5-fold cross-validation experiments.
图C.3:前列腺AGGC数据集(采用交叉验证,测试I)上的混淆矩阵。每个混淆矩阵表示五折交叉验证实验的平均值。
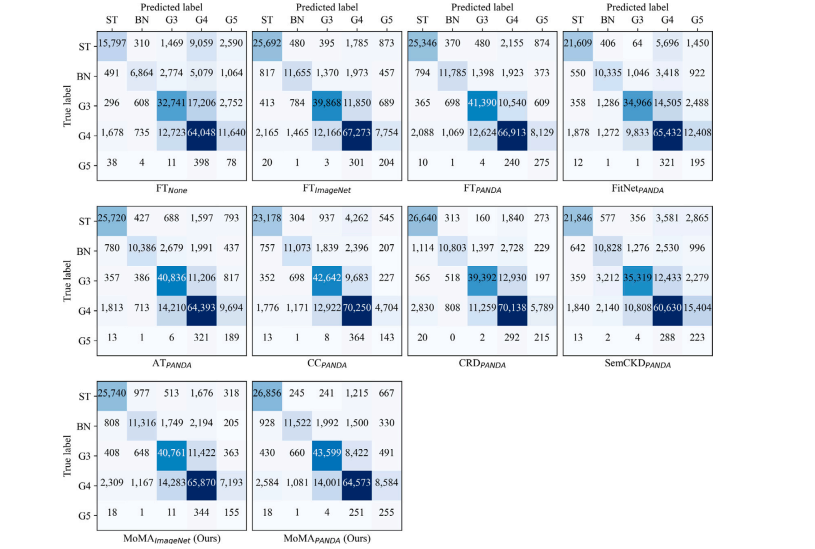
Fig. C.4. Confusion matrices on Prostate AGGC test (Test II). Each confusion matrix represents the average across 5-fold cross-validation experiments
图C.4:前列腺AGGC测试集(测试II)上的混淆矩阵。每个混淆矩阵表示五折交叉验证实验的平均值。
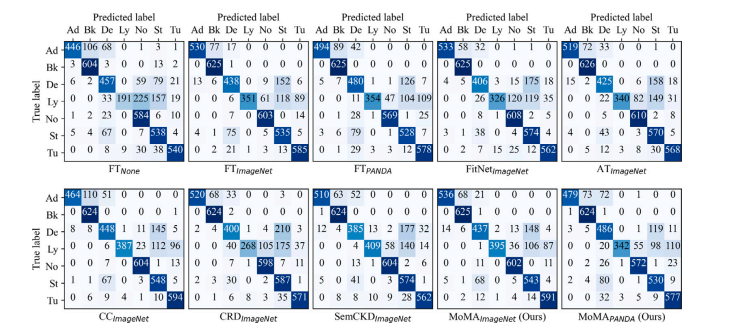
Fig. C.5. Confusion matrices on Colon K16 SN (Test I). Each confusion matrix represents the average across 5 runs.
图C.5:结肠K16数据集(使用留一法,测试I)上的混淆矩阵。每个混淆矩阵表示5次运行的平均值。 (这里SN推测为留一法“Leave-one-out”类似的某种抽样方式,具体含义可根据上下文再确认)
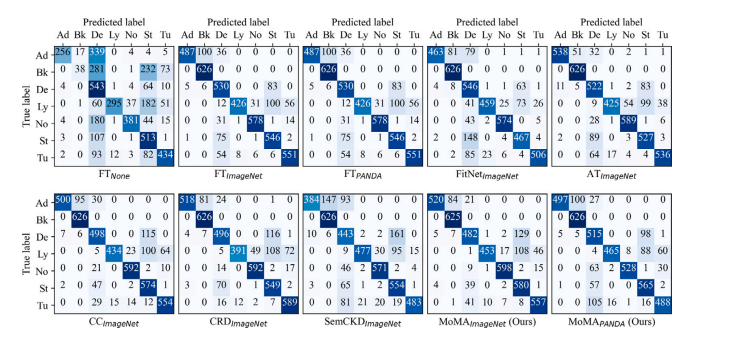
Fig. C.6. Confusion matrices on Colon K16 (Test II). Each confusion matrix represents the average across 5 runs.
图C.6:结肠K16数据集(测试II)上的混淆矩阵。每个混淆矩阵表示五次运行结果的平均值。
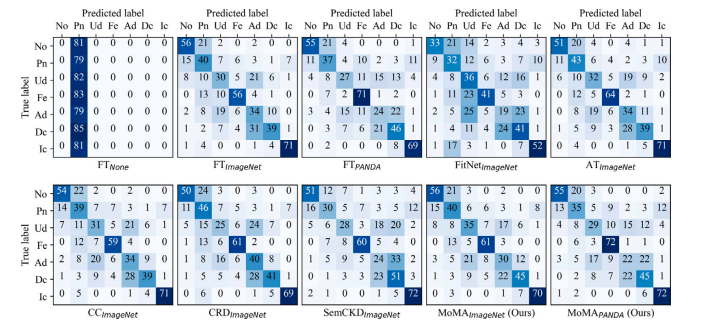
Fig. C.7. Confusion matrices on irrelevant task distillation: breast carcinoma sub-type classification. Each confusion matrix represents the average across 5 runs.
图C.7:不相关任务知识蒸馏中的混淆矩阵:乳腺癌亚型分类。每个混淆矩阵表示五次运行的平均值
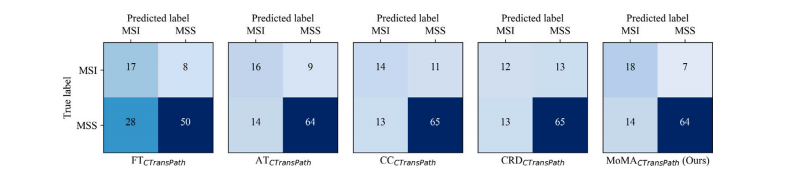
Fig. C.8.Confusion matrices on irrelevant task distillation: gastric microsatellite instability prediction. Each confusion matrix represents the average across 5-fold cross-validation experiments
图C.8:不相关任务知识蒸馏的混淆矩阵:胃微卫星不稳定性预测。每个混淆矩阵表示五折交叉验证实验的平均值。
Table
表
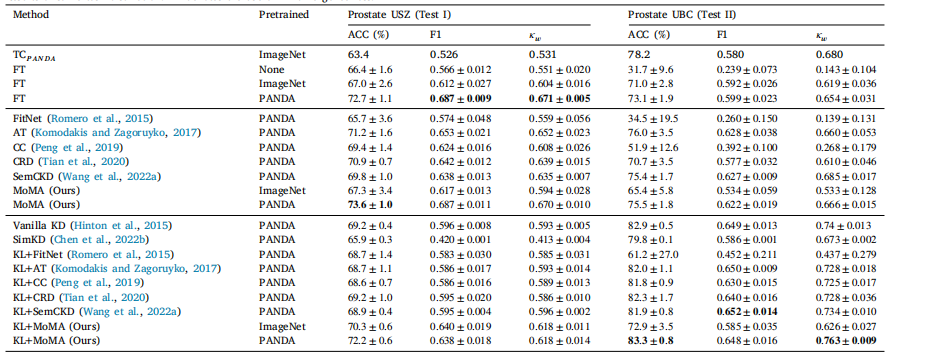
Table 1Results of same task distillation. KL denotes the use of KL divergence loss.
表1 相同任务知识蒸馏的结果。KL表示使用了KL散度损失。
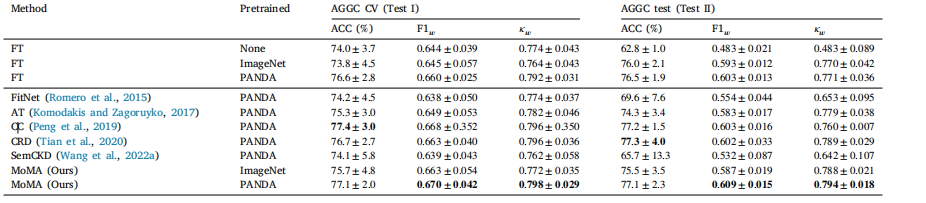
Table 2Results of relevant task distillation.
表2 相关任务知识蒸馏的结果。
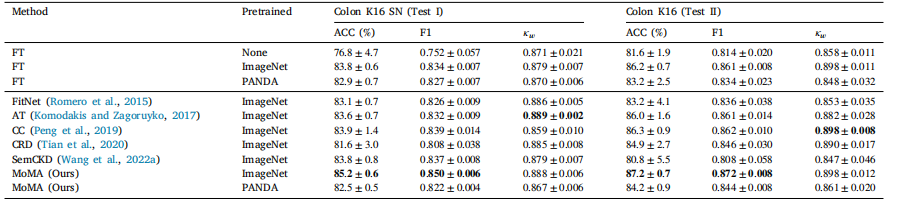
Table 3Results of irrelevant task distillation: colon tissue type classification
表3 不相关任务知识蒸馏的结果:结肠组织类型分类
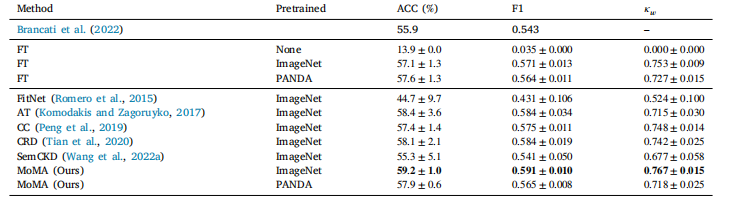
Table 4Results of irrelevant task distillation: breast carcinoma sub-type classification.
表4 不相关任务知识蒸馏的结果:乳腺癌亚型分类。
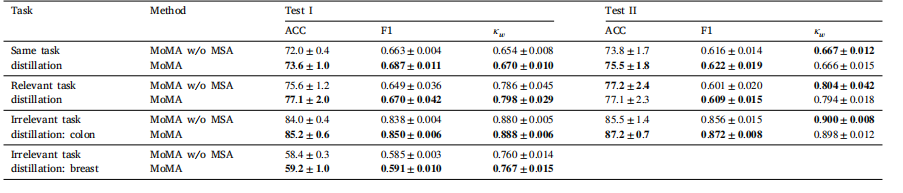
Table 5Ablation results of MoMA with and without Multi-head Attention on the three distillation tasks.
表5:在三项蒸馏任务中,有和没有使用多头注意力机制的MoMA方法的消融实验结果。
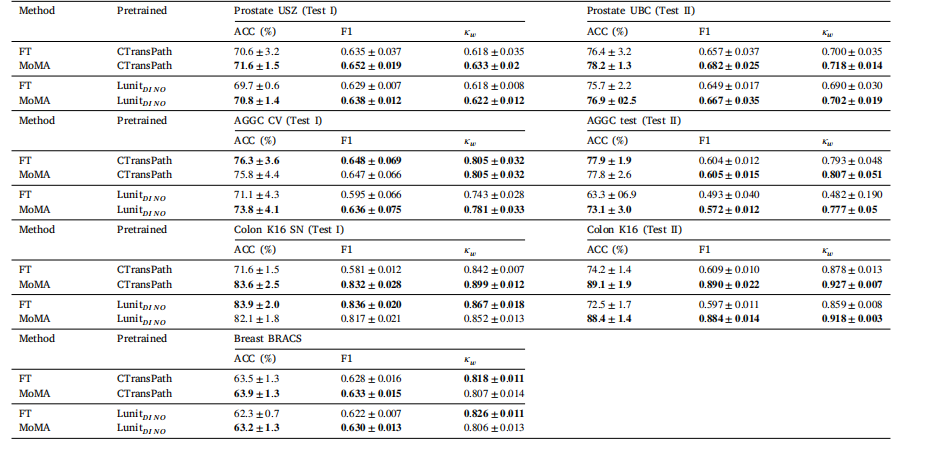
Table 6Results of three distillation tasks with MoMA and self-supervised learning.
表6 使用MoMA方法和自监督学习进行三项蒸馏任务的结果。

Table 7Results of irrelevant task distillation: gastric microsatellite instability prediction.
表7 不相关任务知识蒸馏的结果:胃微卫星不稳定性预测。
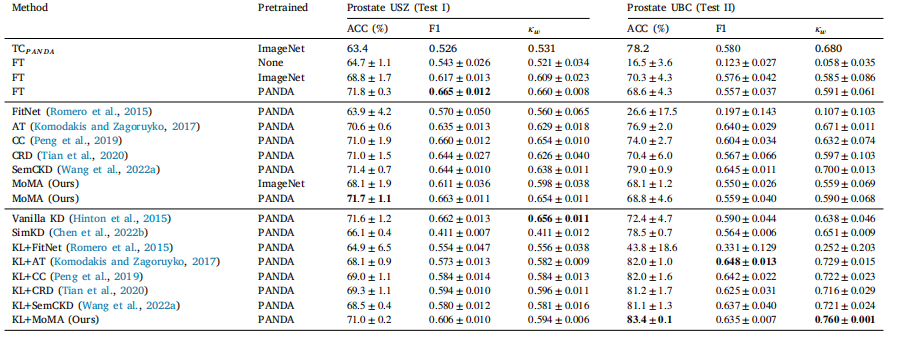
Table B.1Results of same task distillation on 50% training data. KL denotes the use of KL divergence loss
表B.1 在50%训练数据上进行相同任务知识蒸馏的结果。KL表示使用了KL散度损失。
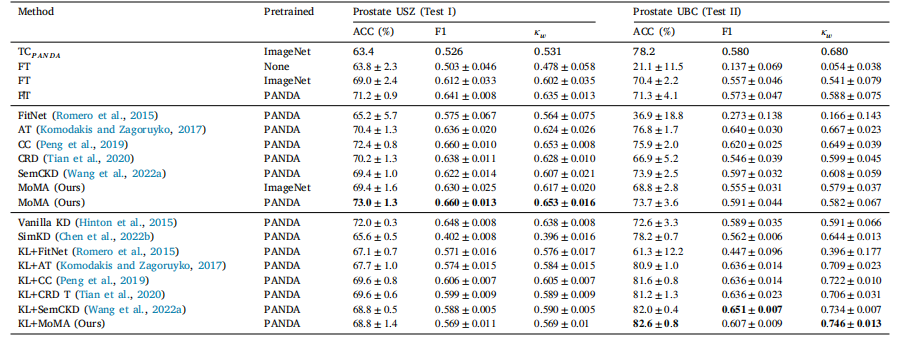
Table B.2Results of same task distillation on 25% training data. KL denotes the use of KL divergence loss.
表B.2 在25%的训练数据上进行相同任务知识蒸馏的结果。KL表示使用了KL散度损失。

Table B.3Results of irrelevant task distillation: prostate cancer classification
表B.3 不相关任务知识蒸馏的结果:前列腺癌分类