Title
题目
Improving cross-domain generalizability of medical image segmentationusing uncertainty and shape-aware continual test-time domain adaptation
利用不确定性与形状感知的持续测试时域自适应提升医学图像分割的跨域泛化能力
01
文献速递介绍
深度神经网络在诸多领域取得了前所未有的进展。图像处理和计算机视觉应用,例如医疗方面的应用图像分析,在过去几年里(Litjens 等人,2017 年)。在部分特别是,诸如卷积神经网络(CNN)之类的模型已经展示了强大的表示学习能力,实现了最先进的性能,甚至超越人类专家的表现在各种视觉任务中,当以监督学习的方式进行训练时(Yann)(参见 et al., 2015)。然而,监督模型需要大量的用于训练的带注释数据有限,这限制了它们在医疗领域的应用。由于生成像素级标注的成本高昂,成像任务受到影响。此外,在部署时,监督模型常常会面临新的测试情况。来自分布情况与其训练数据不同的领域的样本数据,导致推理期间性能降低。这里,“领域”指的是由特定的一组集合所定义的数据分布。协议和上下文。在医学成像领域,不同的领域包含传递不同模态的数据(图 1(a,d))或来自同一模态的数据模态相同但采集于不同部位或采用不同采集方式的数据参数。显著的分布差异和不同影响。不同领域之间的数据常常存在年龄外观上的差异。例如,T1 加权成像和 mDixon 磁共振成像扫描具有不同的对比度对于相同的解剖结构(图 1(g,j))。这种偏差在训练域和测试域之间的差异,即所谓的域偏移,在实际应用中很常见。医学成像任务(本 - 大卫等人,2010 年)并阻碍(训练)模型共享需要在不同数据集上重新训练,这造成了限制。在预算和时间受限的情况下使用深度神经网络。解决缺乏跨学科合作这一问题的一个特别有前景的方法是深度模型的领域泛化能力即领域自适应(DA)。领域自适应(DA)旨在对在有标注的源领域训练好的模型进行调整。以最小的性能损失迁移到看不见的目标领域(贝特森)(参见 Zeng 等人,2022a)。领域自适应方法包括领域对抗训练。(例如,Yang 等人,2019 年),领域翻译(Yang 等人,2019 年)以及自训练这些方法需要获取到(Zou 等人,2018 年)。这些方法需要访问到在适应阶段的源域,而训练数据由于诸如等因素,来自源域的数据常常无法获取。隐私问题和计算限制。对此,一些方法通过利用先验知识或解剖学知识,无需访问源数据。已提出了相关信息(贝特森等人,2019 年,2021 年)。然而,这些方法在灵活性方面存在局限性。解剖信息建模。无源域适应(国家食品药品监督管理总局)因此最近开发了一些方法来避免此类情况。然而,SFDA 方法存在诸多限制(Kundu 等人,2020 年;Liu 等人,2021 年)。需要来自目标领域的训练集和测试集,这些并非总是能够获得(Bateson 等人,2022b)。最近,诸如测试时域适应(TTA)(王)等新方法(梁等人,2021a),持续测试时域适应(CTTA)(梁)(例如,2023 年)以及领域泛化(DG)(周等人,2023 年)已经已被提出以解决现有方法的局限性。TTA这些方法通过直接调整预训练模型来提高实用性。针对目标测试集,无需目标训练集即可实现。另一方面,CTTA 方法与 TTA 方法类似。但要专注于增强其在长期持续运行中的稳健性适应性。DG 方法通过旨在生成一种结果而发挥着不同的作用。从一个或多个源领域中获得更具泛化能力的模型,而无需在推理过程中更新参数。CTTA 可用于分割在不同条件下获取的医学图像。纵向研究的时间点,但只有在适应可行的情况下源模型,通常通过经验风险最小化进行训练(ERM)(叶等,2021 年;瓦尔萨夫斯基等,2020 年;王等,2021a;(He 等人,2021 年;Pei 等人,2023 年;Hoyer 等人,2022 年)已经表明作为起点,在目标领域表现出合理的性能(图 1(a-f))ERM 模型可能难以提供足够的在严重领域偏移情况下进一步适应的性能(图 1(g - l))。领域知识可用于设计预处理程序。这缩小了领域差距(Kim 和 Chai,2021 年),并使 ERM 成为可能。然而,要使模型在目标领域表现良好。当需要设计预处理程序时,所付出的努力会显著增加。一个预训练模型被分享给多个终端用户以考虑不同的测试时间数据分布为了解决这些问题,我们提出了一种通用的 CTTA 框架。用于医学图像的跨域分割。我们首先整合将形状感知特征学习融入现有模型,并在这些模型上进行训练利用 DG 技术对源域进行处理。这消除了对经过精心预处理的目标领域数据,并允许源模型无论严重程度如何,在大多数目标领域都能表现得较为合理关于领域偏移。然后,我们使用不确定性加权的多任务均值教师网络进行适应,生成具有提高了精度并优化了轮廓。我们还引入了一种新颖的多层级跨任务正则化方案以增强一致性在形状表示与相应的分割之间由学生模型生成的地图,从而利用几何形状为在充满挑战的本地和全环境中提升性能而施加的限制条件缩放。为了实现持续的适应性,模型的一小部分权重会随机重置为其使用 DG 技术训练的初始状态。在每次适应步骤中,提取技术和领域不变特征。该过程为模型提供了一个不错的初始性能作为基础。开启它,使其能够持续适应不断涌入的新测试流。在不因过度拟合样本而损害其性能的情况下整体的通用性。我们表明所提出的框架是可行的。ERM 和 DG 训练的源模型以及(1)优于多个状态在具有挑战性的跨域分割任务中采用最先进的方法(1)使用五个不同的多站点或多模态数据集,(2)效果更佳在各种场景下,它都比同类产品更适合 CTTA。本文基于我们之前的研究成果,该成果已在 2023 年国际医学影像会议上被提前录用年龄计算与计算机辅助干预(MICCAI)(朱)(et al., 2023)。我们在以下方面对会议论文进行了改进方面:(1)我们的方法经过改进,已纳入不确定性因素。多层级跨任务一致性排序,从而进一步提升(1)对性能进行了改进,以及(2)我们已经进行了实验。另外两个跨域分割任务,并且包含更深入的内容实验分析以证明我们方法的广泛适用性提议的框架。
Aastract
摘要
Continual test-time adaptation (CTTA) aims to continuously adapt a source-trained model to a target domainwith minimal performance loss while assuming no access to the source data. Typically, source models aretrained with empirical risk minimization (ERM) and assumed to perform reasonably on the target domain toallow for further adaptation. However, ERM-trained models often fail to perform adequately on a severelydrifted target domain, resulting in unsatisfactory adaptation results. To tackle this issue, we propose ageneralizable CTTA framework. First, we incorporate domain-invariant shape modeling into the model andtrain it using domain-generalization (DG) techniques, promoting target-domain adaptability regardless of theseverity of the domain shift. Then, an uncertainty and shape-aware mean teacher network performs adaptationwith uncertainty-weighted pseudo-labels and shape information. As part of this process, a novel uncertaintyranked cross-task regularization scheme is proposed to impose consistency between segmentation maps andtheir corresponding shape representations, both produced by the student model, at the patch and global levelsto enhance performance further. Lastly, small portions of the model’s weights are stochastically reset to theinitial domain-generalized state at each adaptation step, preventing the model from ‘diving too deep’ into anyspecific test samples. The proposed method demonstrates strong continual adaptability and outperforms itspeers on five cross-domain segmentation tasks, showcasing its effectiveness and generalizability
持续测试时适应(CTTA)旨在在假设无法访问源数据的情况下,将源训练模型持续适应到目标域,同时将性能损失降至最低。通常,源模型通过经验风险最小化(ERM)进行训练,并假定其在目标域上表现合理,以便进一步适应。然而,通过 ERM 训练的模型在严重漂移的目标域上往往表现不佳,导致适应结果不理想。为了解决这个问题,我们提出了一种通用的 CTTA 框架。首先,我们将域不变形状建模纳入模型,并使用域泛化(DG)技术对其进行训练,以促进目标域适应性,无论域偏移的严重程度如何。然后,一个不确定性与形状感知的均值教师网络使用不确定性加权伪标签和形状信息进行适应。作为此过程的一部分,我们提出了一种新颖的不确定性排序跨任务正则化方案,以在补丁和全局级别上强加分割图与其相应形状表示之间的一致性,从而进一步提高性能。最后,在每次适应步骤中,模型权重的小部分会被随机重置为初始的领域泛化状态,防止模型过度深入任何特定的测试样本。所提出的方法展示了强大的持续适应能力,并在五个跨领域分割任务中优于同类方法,证明了其有效性和泛化能力。
Method
方法
The proposed framework is a synergy of four components (Fig. 2)🙁1) shape-aware model training, (2) shape and uncertainty-aware meanteacher network, (3) multi-level cross-task consistency regularizationwith uncertainty ranking, and (4) domain-generalized stochastic weightrestoration for continual adaptation. Component (1) is used for modeltraining in the source domain, while (2) - (4) are used simultaneouslyfor CTTA. We describe each component in detail below.
所提出的框架是四个组件的协同组合(图2):(1)形状感知模型训练;(2)形状与不确定性感知的平均教师网络;(3)带有不确定性排序的多级跨任务一致性正则化;(4)用于持续自适应的领域泛化随机权重恢复。组件(1)用于源领域的模型训练,而组件(2) - (4)则同时用于持续测试时间自适应(CTTA)。
Conclusion
结论
In this study, we presented a generalizable continual test-time adaptation framework for cross-domain segmentation of medical images.Our framework first trains a model on the source domain with domaininvariant shape features before adapting it to the target domain withuncertainty-weighted pseudo-labels and SDF maps. In addition, a novelmulti-level uncertainty-ranked cross-task consistency loss was proposedto further improve the performance of the student model. Our methodcan work with ERM or DG-trained source models and outperformedits peers on five cross-site/cross-domain segmentation tasks withoutshowing performance degradation as the adaptation progressed. Ourframework can continuously adapt the source model to unknown testdata online for the segmentation task, significantly reducing the costand bias associated with manual labeling.
在本研究中,我们提出了一种可泛化的持续测试时适应框架,用于医学图像的跨域分割。该框架首先在源域上训练具有域不变形状特征的模型,继而通过不确定性加权的伪标签和SDF图实现目标域适应。此外,我们提出了新型的多级不确定性排序跨任务一致性损失函数,以进一步提升学生模型的性能。本方法兼容ERM或DG训练的源模型,在五项跨站点/跨域分割任务中表现优于同类方法,且在适应过程中未出现性能衰减。该框架能够在线持续适应未知测试数据的分割任务,显著降低了人工标注的成本与偏差。
Results
结果
We evaluated our method and other benchmarking methods onfive datasets of different types of medical images. Each dataset has aunique distribution due to images collected from multiple sites and/ormodalities. We describe each dataset in paragraphs below.The first dataset is a cross-site binary prostate segmentation datasetfrom T2 -weighted MRI scans collected from six different sites where12–30 scans were available for each site (Bloch et al., 2015; Lemaîtreet al., 2015; Litjens et al., 2014).The second dataset is a cross-site and cross-modality multi-class(liver, left and right kidneys, and spleen) abdominal segmentationdataset between 30 CT and 20 MRI T2 -SPIR scans (Landman et al.,2015; Kavur et al., 2021).The third dataset is a same-site cross-modality muscle segmentationdataset with 13 lower-leg muscles and bones between 30 MRI T1 andmDixon scans (Zhu et al., 2021).The fourth dataset is a cross-site and cross-modality whole braintumor segmentation dataset(Menze et al., 2015) from over 100 MRI T2FLAIR and T2 -weighted scans. The dataset was collected by two centers.The last dataset is a cross-site and cross-modality heart segmentation dataset of four substructures (left ventricle, myocardium, leftatrium, and ascending aorta) from 20 MRI balanced steady-state freeprecession (b-SSFP) and CT scans (Wu and Zhuang, 2020).All scans were normalized to zero mean and unit variance beforebeing reformatted to 2D.Following other studies (Ouyang et al., 2023;Zhu et al., 2022; Wu and Zhuang, 2020), the prostate, brain tumor,and abdominal scans were resized to 192 × 192 pixels while the heartsubstructure and the muscle scans were center-cropped to 256 × 256and resized to 128 × 128 pixels, respectively. Lastly, a window of[−275, 125] in Houndsfield units was applied to CT scans and the top0.5% of the histogram of MRI scans was clipped.For the first dataset, we treated each site as the source domainand adapted to all other sites. The adaptation was performed in bothalphabetic and randomized orders. For example, the source model wasfirst trained on site A, then adapted to sites B, C, D, E, and F (alphabetic)and also adapted to sites F, E, D, B, and C (randomized). For otherdatasets, we first performed adaptation from modality A to B, then fromB to A. All experiments were performed in an online and continuousmanner: each test scan arrived randomly and was broken down intomultiple batches if needed. The model adapted itself to each batchbefore making a prediction. U-Net with an EfficientNet-b2 backbonewas used as the source model for all our experiments. We trained thesource model with ERM to provide a baseline model susceptible todomain shifts, and also with CiDG to produce another baseline thatis domain-generalized (i.e., resilient to domain shifts). Both baselinemodels were used by all the benchmarked adaptation methods toevaluate their efficacy in improving a baseline model’s target-domainperformance in various conditions. The Adam optimizer (Kingma andBa, 2015) was used with a learning rate of 0.001 and a batch sizeof 32. 𝛼 was set to 0.5 to achieve a balance between the local andglobal cross-task consistency terms, and 𝛽 was set to 1 to fully utilizethe self-regularization of the student model. 𝜅 was set to −1500 toapproximate the inverse transformation from the segmentation labelsto SDF maps, and 𝑝 to 0.01 to restore roughly 1% of model parametersback to their initial state with each gradient update.
我们在五种不同类型的医学图像数据集上评估了我们的方法和其他基准方法。由于图像是从多个站点和(或)采用多种成像方式收集而来,每个数据集都有独特的数据分布。我们在下面的段落中对每个数据集进行描述。 第一个数据集是一个跨站点的前列腺二分类分割数据集,数据来源于六个不同站点的T2加权磁共振成像(MRI)扫描,每个站点有12 - 30次扫描数据(布洛赫等人,2015年;勒梅特等人,2015年;利琴斯等人,2014年)。 第二个数据集是一个跨站点、跨成像方式的腹部多分类分割数据集,用于分割肝脏、左右肾脏和脾脏,包含30次计算机断层扫描(CT)和20次MRI T2 - 脂肪抑制快速成像(T2 - SPIR)扫描的数据(兰德曼等人,2015年;卡武尔等人,2021年)。 第三个数据集是一个同站点、跨成像方式的肌肉分割数据集,用于分割13块小腿肌肉和骨骼,包含30次MRI T1扫描和磁共振 Dixon 成像(mDixon)扫描的数据(朱等人,2021年)。 第四个数据集是一个跨站点、跨成像方式的全脑肿瘤分割数据集(门策等人,2015年),数据来自100多次MRI T2液体衰减反转恢复序列(T2 FLAIR)和T2加权扫描,由两个研究中心收集。 最后一个数据集是一个跨站点、跨成像方式的心脏分割数据集,用于分割四个子结构,即左心室、心肌、左心房和升主动脉,包含20次MRI平衡稳态自由进动序列(b - SSFP)和CT扫描的数据(吴和庄,2020年)。 所有扫描数据在重新格式化为二维图像之前都被归一化为零均值和单位方差。
参考其他研究(欧阳等人,2023年;朱等人,2022年;吴和庄,2020年),将前列腺、脑肿瘤和腹部扫描图像的尺寸调整为192×192像素,而心脏亚结构和肌肉扫描图像则先进行中心裁剪至256×256像素,再分别调整为128×128像素。最后,对CT扫描图像应用[-275, 125]亨氏单位的窗宽,对MRI扫描图像直方图的前0.5%进行裁剪。 对于第一个数据集,我们将每个站点视为源域,并对所有其他站点进行适配。适配过程按照字母顺序和随机顺序分别进行。例如,源模型先在站点A上进行训练,然后按照字母顺序适配到站点B、C、D、E和F,也按照随机顺序适配到站点F、E、D、B和C。对于其他数据集,我们先从模态A适配到模态B,再从模态B适配到模态A。 所有实验均以在线和连续的方式进行:每个测试扫描图像随机到达,如有需要会被拆分为多个批次。模型在进行预测之前会针对每个批次进行自我适配。在所有实验中,我们使用带有EfficientNet - b2主干网络的U型网络作为源模型。我们使用经验风险最小化(ERM)方法训练源模型,以提供一个易受域偏移影响的基线模型,同时使用跨域不变判别式生成(CiDG)方法训练源模型,以生成另一个具有域泛化能力(即对域偏移具有鲁棒性)的基线模型。所有参与基准测试的适配方法都使用这两个基线模型,以评估它们在各种条件下提升基线模型目标域性能的有效性。 我们使用Adam优化器(金马和巴,2015年),学习率设置为0.001,批量大小设置为32。将α设置为0.5,以实现局部和全局跨任务一致性项之间的平衡;将β设置为1,以充分利用学生模型的自正则化。将κ设置为 - 1500,以近似从分割标签到有符号距离函数(SDF)图的逆变换;将p设置为0.01,以便在每次梯度更新时将大约1%的模型参数恢复到其初始状态。
Figure
图

Fig. 1. Demonstrations of different severities of domain shifts. Example 1: panels (a) and (d) are CT and MRI T2 scans containing the same abdominal structures, © and (f) aretheir segmentation ground truth labels, and (b) and (e) are cross-domain predictions for (a) and (d) by an ERM model trained on (d) and (a), respectively. Example 2: panels (g)and (j) are MRI T1 and mDixon scans containing the same musculoskeletal structures, (i) and (l) are their segmentation ground truth labels, and (h) and (k) are labels predictedfor (g) and (j) by an ERM model trained on (j) and (g), respectively. Arrows of the same color indicate the same anatomical structures across different domains.
图1. 不同域偏移严重程度的示例演示。示例1:图(a)和(d)为包含相同腹部结构的CT与MRI T2扫描图像,(c)和(f)是它们的分割真实标签,(b)和(e)分别是基于(d)和(a)训练的ERM模型对(a)和(d)的跨域预测结果。示例2:图(g)和(j)为包含相同肌肉骨骼结构的MRI T1与mDixon扫描图像,(i)和(l)是它们的分割真实标签,(h)和(k)分别是基于(j)和(g)训练的ERM模型对(g)和(j)的预测结果。同色箭头表示不同域中相同的解剖结构。
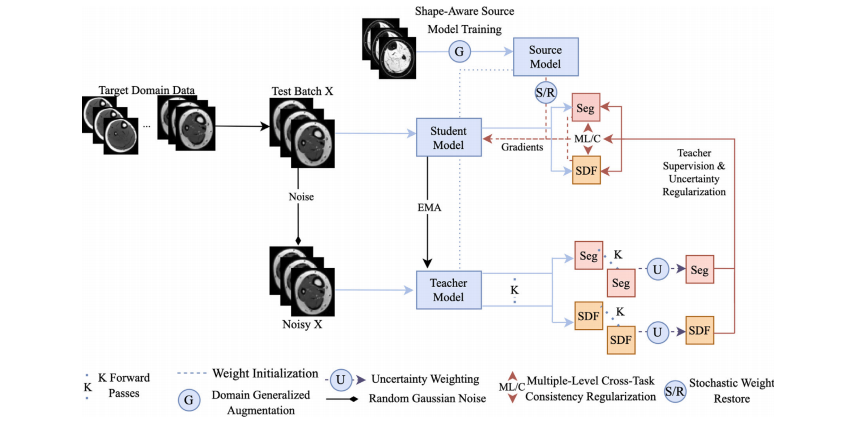
Fig. 2. Schematic of the proposed CTTA framework. The model is first trained on the source domain with shape-aware DG techniques for generalizable and adaptable baselineperformance. Then, a multi-task uncertainty-weighted mean teacher network adapts the student model to an unseen and unlabeled target domain via uncertainty-weighted pseudopredictions produced by the teacher model. Meanwhile, the student model is regularized via an uncertainty-ranked multi-level loss to ensure the cross-task consistency betweenits SDF and segmentation predictions at various scales. Small portions of the model are also reset to their initial shape-aware state at each step to counter catastrophic forgettingand improve the robustness of continual adaptation
图2. 所提出的CTTA框架示意图。模型首先在源域上通过形状感知的领域泛化(DG)技术进行训练,以获得可泛化且适应性强的基线性能。随后,一个多任务不确定性加权均值教师网络通过教师模型生成的不确定性加权伪预测,将学生模型适配到未见且无标注的目标域。同时,学生模型通过不确定性排序的多层次损失进行正则化,以确保其符号距离函数(SDF)与多尺度分割预测间的跨任务一致性。模型的小部分参数在每一步均被重置至初始形状感知状态,以抵御灾难性遗忘并提升持续适应鲁棒性。

Fig. 3. Qualitative evaluation of benchmarked methods on the task of (a) cross-site MRI T2 prostate segmentation, (b) MRI mDixon → T1 muscle segmentation, © MRI T2 → CTabdominal segmentation, (d) MRI b-SSFP → CT heart substructure segmentation, and (e) MRI T2 → FLAIR brain tumor segmentation. Best viewed when zoomed in
图3. 各基准方法在以下分割任务中的定性评估:(a) 跨站点MRI T2前列腺分割,(b) MRI mDixon → T1肌肉分割,© MRI T2 → CT腹部分割,(d) MRI b-SSFP → CT心脏亚结构分割,(e) MRI T2 → FLAIR脑肿瘤分割。建议放大后查看细节。
Table
表

Table 1Quantitative evaluation of all methods with CiDG-trained source model on the cross-site prostate, cross-modality abdomen, and muscle segmentation tasks. The target domain ‘Rest’in prostate segmentation means the adaptation was performed in alphabetical order as per the site’s name (e.g., source model trained on site A and adapted to target domains inorder of B, C, D, E, and F). The same source model (CiDG) was used by all adaptation methods. Results are shown as Dice (%)/ASSD (mm). The second row shows source/targetdomains. Source, general, and medical methods are placed into their respective groups. † denotes statistical significance between the Dice/ASSD score of a method and that of ourmethod (𝑝 < 0.05). Best results in bold
表1:基于CiDG训练的源模型在跨站点前列腺分割、跨模态腹部分割及肌肉分割任务中对所有方法的定量评估。在前列腺分割任务中,目标域"Rest"表示按照站点名称字母顺序进行领域自适应(例如,源模型在站点A训练后,依次对目标域B、C、D、E、F进行适应)。所有自适应方法均使用相同的源模型(CiDG)。结果以Dice系数(%)/ASSD(mm)形式呈现。第二行列出了源域/目标域信息。方法分为源方法、通用方法及医学方法三组。†符号表示该方法与本文方法在Dice/ASSD得分上具有统计学显著性差异(𝑝 < 0.05)。最佳结果以加粗显示。

Table 2Quantitative evaluation of all methods with CiDG-trained source model on the cross-site prostate task. The adaptation was performed with randomized orders (e.g., A/E, F, D, B, Cmeans the source model was trained on site A and adapted to target domains in order of E, F, D, B, and C, and so on). The same source model (CiDG) was used by all adaptationmethods. Results are shown as Dice (%)/ASSD (mm). The second row shows source/target domains. Source, general, and medical methods are placed into their respective groups.† denotes statistical significance between the Dice/ASSD score of a method and that of our method (𝑝 < 0.05). Best results in bold
表2在跨站点前列腺任务中,使用在CiDG上训练的源模型对所有方法进行定量评估。适配过程以随机顺序进行(例如,A/E、F、D、B、C 表示源模型在站点A上训练,并按E、F、D、B和C的顺序适配到目标域,依此类推)。所有适配方法均使用相同的源模型(CiDG)。结果以骰子系数(%)/平均对称表面距离(mm)表示。第二行显示源域/目标域。源方法、通用方法和医学方法分别归为各自的类别。† 表示某一方法的骰子系数/平均对称表面距离得分与我们的方法得分之间存在统计学显著性差异(p < 0.05)。最佳结果以粗体显示。

Table 3Quantitative evaluation of benchmarked methods (with CiDG source model) on thebrain tumor and heart substructure segmentation tasks. The same source model (CiDG)was used by all benchmarked methods. Results are shown in form of Dice (%)/ASSD(mm). † denotes statistical significance between the Dice/ASSD score of a methodand that of our method (𝑝 < 0.05). Source and target domains were presented assource/target in the second row. Best results are in bold.
表3 在脑肿瘤和心脏子结构分割任务上对基准方法(使用CiDG源模型)的定量评估。所有基准方法都使用了相同的源模型(CiDG)。结果以骰子系数(%)/平均对称表面距离(毫米)的形式呈现。† 表示某一方法的骰子系数/平均对称表面距离得分与我们的方法得分之间存在统计学显著性差异(p < 0.05)。第二行中源域和目标域表示为源域/目标域。最佳结果以粗体显示。

Table 4Quantitative evaluation of benchmarked methods (with ERM source model) on the prostate, abdominal, brain tumor, and heart substructure segmentation tasks. The same sourcemodel was used by all methods. Muscle segmentation was skipped due to the poor performance of the ERM-trained source model (Dice < 8%, ASSD NaN). Results were shownin form of Dice (%)/ASSD (mm). Source and target domains were presented as source/target in the second row. † denotes statistical significance between the Dice/ASSD score ofa method and that of our method (𝑝 < 0.05). Best results were in bold
表4 基于ERM源模型的基准方法在前列腺、腹部、脑肿瘤及心脏子结构分割任务上的定量评估。所有方法均使用同一源模型。由于ERM训练源模型性能极差(Dice系数<8%,ASSD为NaN),肌肉分割任务被跳过。结果以Dice(%)/ASSD(毫米)形式呈现,第二行列出的"源/目标"表示源域与目标域。†标记表示某方法的Dice/ASSD分数与本文方法存在统计学显著性差异(𝑝 <0.05)。最佳结果以粗体标出。

Table 5Comparison of the continual test-time adaptability of each model (with CiDG source model). The same source model was used by all benchmarked methods. ATTA was excludedfrom the comparison as it was designed for episodic test-time adaptation. Each cell presented each model’s running/final Dice scores (in %) for each scenario. Equal (in italics)or higher final Dice scores (in bold) indicate a model’s suitability for continual test-time adaptation.
表5 各模型持续测试时适应能力的对比(使用CiDG源模型)。所有基准方法均采用相同的源模型。ATTA方法因其专为间歇式测试时适应设计而被排除在比较之外。表格单元格中展示了各模型在不同场景下的运行期间/最终Dice分数(%)。斜体标注的相等或加粗标注的更高最终Dice分数,表明该模型对持续测试时适应的适用性。

Table 6Ablation study of the proposed method with both ERM and DG-trained source models on representative datasets. Each component is graduallyadded to demonstrate its contribution. Here, MT denotes mean teacher, SDF refers to the signed distance field, UMT stands for uncertainty-awaremean teacher, MLCC indicates multi-level cross-task consistency, and R is short for weight reset. † denotes statistical significance between theDice/ASSD score of an ablated and that of the proposed method (𝑝 < 0.05). Best results marked in bold.
表6 在具有代表性的数据集上,针对同时采用经验风险最小化(ERM)和域泛化(DG)训练的源模型,对所提出方法进行的消融研究。逐步添加每个组件以展示其贡献。在此,MT表示平均教师,SDF指有符号距离场,UMT代表不确定性感知平均教师,MLCC表示多级跨任务一致性,R是权重重置的缩写。† 表示消融后的Dice/平均表面对称距离(ASSD)得分与所提出方法的相应得分之间存在统计学显著性差异(p < 0.05)。最佳结果以粗体标记。

Table 7Quantitative evaluation of benchmarked methods (with CiDG source model) on themuscle segmentation with single-image and continuous adaptation. Results are shown asDices /Dicec , where Dices denotes the Dice score achieved with single image adaptationand Dicec is the Dice score achieved with continuous adaptation.
表7 基于CiDG源模型的基准方法在单图像适应和连续适应下的肌肉分割定量评估。结果以Dices/Dicec形式呈现,其中Dices表示通过单图像适应获得的Dice分数,Dicec表示通过连续适应获得的Dice分数。 注:相关评估指标参考了肌肉分割中常用的定量方法,Dice系数被广泛用于衡量分割结果与真实标注的重合度。

Table 8Comparison of batch-wise inference time of benchmarked adaptation methods on theabdominal segmentation task
表8 腹部分割任务中基准适应方法的批量推理时间对比