Title
题目
DDoCT: Morphology preserved dual-domain joint optimization for fast sparse-view low-dose CT imaging
DDoCT:形态保持的双域联合优化用于快速稀疏视角低剂量CT成像
01
文献速递介绍
计算机断层扫描(CT)是当今广泛使用的医学成像技术。 作为一种非侵入性诊断工具,CT为临床应用提供了重要的解剖学信息,在现代医学的发展中起着至关重要的作用。其广泛的临床应用涵盖了多个重要领域。在临床诊断中,CT在识别各种疾病(如肿瘤和中风)的特征方面表现出强大的能力(Ginat和Gupta,2014)。在临床治疗中,尤其是在肿瘤放疗的背景下,CT图像能够精确定位肿瘤并引导放疗射束,从而确保治疗计划的准确性并优化治疗效果。此外,CT还为外科医生提供了高分辨率的内部解剖图像,有助于术前计划。
在临床实践中,为了获得具有诊断意义的CT图像,通常需要遵循“尽可能低的合理剂量”(ALARA)原则。尽管CT扫描(总计4.03亿次)仅占全球年度放射学和核医学检查或程序总数的9.6%,但其贡献了62%的年度集体有效剂量(Mahesh等,2022),且某些类型的CT检查可能需要患者接受多次成像序列(例如,对比剂注射前后的成像)。这可能导致过量的辐射(Kachelrieß和Rehani,2020),从而引发癌症和遗传损伤等疾病。过量辐射对患者还会产生不可逆的影响,降低其生活质量(Goldman,2007)。因此,这一问题引起了广泛的公众关注(Brenner和Hall,2007;Pearce等,2012)。
低剂量CT(LDCT)是一种有效的降低患者辐射剂量的措施(Team,2011)。在临床实践中,为了获取低剂量CT图像,通常通过减少管电流来降低产生X射线光子的电子束通量,和/或减少CT扫描过程中投影的数量。虽然这些措施在一定程度上缓解了辐射剂量的问题,但它们可能会降低X射线的信噪比和图像质量,从而降低CT图像的对比分辨率,并可能增加噪声和伪影。如果这些问题不能有效解决,将会显著影响低剂量CT在各种临床场景中的应用。因此,如何通过低剂量扫描协议获得与常规剂量CT(NDCT)图像相当的高质量CT图像并满足临床需求,已成为CT成像领域的一个长期存在且具有实际意义的问题。
为了解决这一问题,提出了多种低剂量CT成像算法,这些算法大致可分为以下三类(Zhang等,2021a;Yang,2017;Zhang等,2013):基于正弦图的预处理、迭代重建和图像后处理。
基于正弦图的预处理
正弦图预处理是在使用低剂量X射线束获得的CT原始数据上进行的。由于这种方法直接作用于数据采集阶段,它能够有效结合物理特性与光子统计特性。典型方法包括双边滤波(Manduca等,2009)、结构自适应滤波(Balda等,2012)和加权最小二乘法(Wang等,2006)。这些去噪方法有效结合了物理特性和光子统计特性,使其成为正弦图预处理中的热门选择。尽管如此,正弦图预处理也存在一些局限性。首先,这种方法过于依赖高质量的原始数据。例如,对于低剂量投影数据,随着信号减弱,重建结果的质量显著下降。这使得在信号中恢复缺失信息变得困难,从而影响性能。其次,正弦图预处理可能会导致空间分辨率降低。
迭代重建:迭代重建方法通常通过迭代优化目标函数来重建图像。此方法通常在投影域和图像域之间交替进行前向和后向投影,直到目标函数根据收敛标准被最小化。目标函数通常通过整合已知对象的信息来建模,以保持边缘结构并减少噪声(Xu等,2012;Zhang等,2016;Bian等,2013;Chen等,2014)。然而,这种方法通常需要访问原始数据并且计算成本较高。此外,图像重建的质量很大程度上依赖于目标函数和超参数的精确设置。这些限制阻碍了迭代重建方法在临床实践中的应用。
图像后处理:图像后处理方法主要集中在图像域中减少噪声和伪影。其主要优势是它不依赖于CT厂商提供的原始投影数据,这意味着它可以轻松集成到临床CT成像工作流程中。典型方法包括非局部均值滤波算法(Li等,2014)、块匹配算法(Kang等,2013)和低秩稀疏编码(Lei等,2018)。然而,基于图像域的算法通过根据特定噪声模型估计噪声分布作为噪声减少过程的一部分,这会降低其性能。
尽管现有方法在一定程度上缓解了低剂量CT中的噪声和伪影问题,但它们的局限性阻碍了其在实际临床中的广泛应用。因此,开发高效的低剂量CT成像算法仍是一个重要的研究方向。
Aastract
摘要
Computed tomography (CT) is continuously becoming a valuable diagnostic technique in clinical practice.However, the radiation dose exposure in the CT scanning process is a public health concern. Within medicaldiagnoses, mitigating the radiation risk to patients can be achieved by reducing the radiation dose throughadjustments in tube current and/or the number of projections. Nevertheless, dose reduction introducesadditional noise and artifacts, which have extremely detrimental effects on clinical diagnosis and subsequentanalysis. In recent years, the feasibility of applying deep learning methods to low-dose CT (LDCT) imaging hasbeen demonstrated, leading to significant achievements. This article proposes a dual-domain joint optimizationLDCT imaging framework (termed DDoCT) which uses noisy sparse-view projection to reconstruct highperformance CT images with joint optimization in projection and image domains. The proposed method notonly addresses the noise introduced by reducing tube current, but also pays special attention to issues suchas streak artifacts caused by a reduction in the number of projections, enhancing the applicability of DDoCTin practical fast LDCT imaging environments. Experimental results have demonstrated that DDoCT has madesignificant progress in reducing noise and streak artifacts and enhancing the contrast and clarity of the images.
计算机断层扫描(CT)在临床实践中正逐渐成为一种重要的诊断技术。然而,在CT扫描过程中辐射剂量的暴露引发了公众的健康关注。在医学诊断中,通过调整管电流和/或投影数量来减少辐射剂量,是降低患者辐射风险的一种有效方法。然而,剂量的降低会引入额外的噪声和伪影,这对临床诊断和后续分析具有极大的不利影响。
近年来,低剂量CT(LDCT)成像中应用深度学习方法的可行性已被验证,并取得了显著的成果。本文提出了一种双域联合优化的低剂量CT成像框架(称为DDoCT),该框架利用带噪的稀疏视角投影,通过投影域和图像域的联合优化重建高性能CT图像。所提出的方法不仅解决了因降低管电流引入的噪声问题,还特别关注因投影数量减少而引起的条纹伪影等问题,从而增强了DDoCT在实际快速低剂量CT成像环境中的适用性。
实验结果表明,DDoCT在降低噪声和条纹伪影、增强图像对比度和清晰度方面取得了显著进展。
Method
方法
In this paper, we propose DDoCT, a novel deep-learning framework for dual-domain joint optimization designed for noisy sparse-viewLDCT imaging. It provides a new definition for noisy sparse-view LDCTimaging by integrating precisely designed projection domain superresolution with image domain wavelet high-frequency feature fusiontechnology. Fig. 1 illustrates this framework. The framework is dividedinto two key processing stages: projection domain processing and imagedomain processing. By combining the RFDN-sino and WHF-DN networks, DDoCT provides innovative solutions in practical LDCT imagingenvironments.During the projection domain stage, the network takes noisy sparseview sinograms 𝑆𝑖 as input. The RFDN-sino network is employed topredict a low-noise dense sinograms 𝑆𝑝 from the input. Subsequently,the classical FBP algorithm is used to map the sinogram from the projection domain to the image domain, obtaining the reconstructed image 𝐼**𝑖 .The design of this stage mainly aims to address the streak artifacts andpseudo-structures introduced by the incomplete projections, therebyimproving the quality of 𝐼**𝑖 and simultaneously reducing noise levels.During the image domain processing stage, in order to address thesecondary artifacts and the residual noise, the 𝐼𝑖 is passed through theWHF-DN in the image domain and ultimately aims to generate a highquality image 𝐼𝑝 that can be as consistent as possible with the NDCTimages.Through this design, the entire framework is able to comprehensively handle various noises and artifacts introduced in the practical LDCT imaging environment, yielding more accurate and high performance CT images.
在本文中,我们提出了一种新颖的深度学习框架DDoCT,用于噪声稀疏视角低剂量CT(LDCT)成像的双域联合优化。通过结合精确设计的投影域超分辨率和图像域小波高频特征融合技术,DDoCT为噪声稀疏视角LDCT成像提供了新的定义。图1展示了该框架的结构。整个框架分为两个关键处理阶段:投影域处理和图像域处理。通过结合RFDN-sino和WHF-DN网络,DDoCT在实际LDCT成像环境中提供了创新的解决方案。
在投影域阶段,网络将噪声稀疏视角的正弦图 𝑆𝑖 作为输入。RFDN-sino网络用于从输入中预测出低噪声的密集正弦图 𝑆𝑝 。随后,使用经典的滤波反投影(FBP)算法将正弦图从投影域映射到图像域,得到重建图像 𝐼𝑖 。这一阶段的设计主要旨在解决因投影不完整而引入的条纹伪影和伪结构,从而改善 𝐼**𝑖 的质量并同时降低噪声水平。
在图像域处理阶段,为了进一步处理二次伪影和残余噪声,𝐼𝑖 被传递到图像域的WHF-DN网络中,最终目标是生成一个与常规剂量CT(NDCT)图像尽可能一致的高质量图像 𝐼𝑝 。
通过这种设计,整个框架能够全面处理实际LDCT成像环境中引入的各种噪声和伪影,从而生成更精确且高性能的CT图像。
Conclusion
结论
This paper proposes a dual-domain joint optimization framework,DDoCT, specifically designed for noisy sparse-view LDCT imaging.DDoCT leverages the capabilities provided by deep neural networks forprojection domain super-resolution and image domain wavelet highfrequency fusion to learn dual-domain mapping relationships, offering anew definition for LDCT imaging. In the projection domain, RFDN-sinolearns the transformation mapping from noisy sparse-view sinogramsto low-noise dense sinograms, providing clearer and less noisy inputimages for the image domain stage. In the image domain, WHF-DNis responsible for addressing secondary artifacts and residual noise.Particularly, by learning the fusion relationships of high-frequencyfeatures in the wavelet domain, the WHF-DN further refines imagedetails and improves the overall quality of the images.The design of DDoCT not only focuses on addressing the noiseintroduced by reducing tube current, but also solves issues such asstreak artifacts caused by a reduction in the number of projections. Thiscomprehensive design enhances the applicability of DDoCT in practicalLDCT imaging environments. Experimental results have demonstratedthat our proposed DDoCT can comprehensively handle various noisesand artifacts in practical LDCT imaging environments, producing moreaccurate and high-performance CT images. It has the potential to beapplied in clinical workflows.However, there are also some limitations in this study. The performance of the trained model may be influenced by the complexityof artifact patterns in certain scenarios. For instance, artifacts arisingfrom extremely sparse projection sampling, metal artifacts due to theimplantation of dense objects, and truncation artifacts resulting froman inadequate field of view all pose significant challenges. While all ofthese cases lead to degradation in model performance, they are alsochallenging scenarios for classical image reconstruction algorithms.To address these issues, future work will focus on optimizing themodel design further and introducing physics constraints to improve itsrobustness and adaptability to such edge cases. Additionally, we planto explore techniques for enhancing inference efficiency to enable moreeffective application of DDoCT in diverse clinical settings.
本文提出了一种专门针对噪声稀疏视角低剂量CT(LDCT)成像设计的双域联合优化框架——DDoCT。DDoCT利用深度神经网络在投影域超分辨率和图像域小波高频融合方面的能力,学习双域映射关系,为LDCT成像提供了新的定义。在投影域中,RFDN-sino学习从噪声稀疏视角正弦图到低噪声密集正弦图的转换映射,为图像域阶段提供更清晰且噪声更低的输入图像。在图像域中,WHF-DN负责处理二次伪影和残余噪声。特别是通过学习小波域高频特征的融合关系,WHF-DN进一步优化了图像细节,提高了图像的整体质量。
DDoCT的设计不仅专注于解决因降低管电流引入的噪声问题,还解决了因投影数量减少而导致的条纹伪影等问题。这种综合设计增强了DDoCT在实际LDCT成像环境中的适用性。实验结果表明,DDoCT能够全面处理实际LDCT成像环境中的各种噪声和伪影,生成更准确且性能更高的CT图像,并具有潜在的临床工作流程应用价值。
然而,本研究也存在一些局限性。训练模型的性能可能受到某些场景中伪影模式复杂性的影响。例如,由极稀疏投影采样引起的伪影、由于密集物体植入导致的金属伪影,以及由于视野不足导致的截断伪影,这些都构成了显著挑战。尽管这些情况会导致模型性能下降,但它们对于经典图像重建算法同样是具有挑战性的场景。
为了解决这些问题,未来的工作将进一步优化模型设计,并引入物理约束以提高其在此类极端情况中的鲁棒性和适应性。此外,我们还计划探索提升推理效率的技术,以便更有效地将DDoCT应用于多样化的临床场景中。
Results
结果
In this work, we used a publicly released patient dataset for the2016 NIH-AAPM-Mayo Clinic Low-Dose CT Grand Challenge. Thedataset contains abdominal NDCT images from 10 patients with a slicethickness of 1 mm. The quarter-dose LDCT images were generatedby inserting Poisson noise into the projection data to mimic a noiselevel thatcorresponded to 25% of the full dose. In this study, wefurther generate noisy sparse-view sinograms and low-noise dense viewsinograms by using the Mayo dataset. Specifically, by performing 240parallel-beam projections around 360 degrees on the original LDCTimages, we simulated noisy sparse-view sinograms using this sparsesampling approach, denoted as 𝑆𝑖 . By performing 720 parallel-beamprojections around 360 degrees on the original NDCT images, wesimulated low-noise dense sinograms, denoted as 𝑆𝐺𝑇 . We used datafrom 9 patients as the training dataset, resulting in a total of 5410 pairs,and data from the remaining 1 patient as the test dataset, resulting ina total of 526 pairs.We also used in-house real low- and high-dose head phantom datafor experimental validation. Specifically, an anthropomorphic headphantom was scanned using a cone beam CT on-board imager (TrueBeam System, Varian Medical Systems, Palo Alto, CA). The phantomdata comprises pairs of CT images acquired using low-dose parameters (80 kV, 100 mA) and high-dose parameters (80 kV, 400 mA),with the low-dose settings representing one-quarter of the radiationexposure of the high-dose configurations. We applied the same preprocessing method used for the Mayo dataset to the phantom data,generating corresponding noisy sparse-view sinograms. The data directly reflect the noise and artifact characteristics under real low- andnormal dose conditions in daily CBCT for patient setup in image-guidedradiotherapy.
在本研究中,我们使用了公开发布的2016 NIH-AAPM-Mayo Clinic低剂量CT大赛数据集。该数据集包含来自10位患者的腹部常规剂量CT(NDCT)图像,切片厚度为1毫米。四分之一剂量的低剂量CT(LDCT)图像是通过在投影数据中插入泊松噪声生成的,以模拟相当于全剂量25%的噪声水平。在本研究中,我们进一步利用Mayo数据集生成了噪声稀疏视角正弦图和低噪声密集视角正弦图。具体而言,通过对原始LDCT图像在360度范围内执行240次平行束投影,我们采用稀疏采样方法模拟了噪声稀疏视角正弦图,记为 𝑆**𝑖 。通过对原始NDCT图像在360度范围内执行720次平行束投影,我们模拟了低噪声密集正弦图,记为 𝑆**𝐺𝑇 。我们使用来自9位患者的数据作为训练数据集,总计5410对样本,并使用剩余1位患者的数据作为测试数据集,总计526对样本。
我们还使用了内部真实低剂量和高剂量头部模体数据进行实验验证。具体而言,使用锥束CT(TrueBeam System, Varian Medical Systems, Palo Alto, CA)对仿人头部模体进行扫描。模体数据包括使用低剂量参数(80 kV, 100 mA)和高剂量参数(80 kV, 400 mA)获取的CT图像对,其中低剂量设置代表高剂量配置辐射暴露的四分之一。我们对模体数据应用了与Mayo数据集相同的预处理方法,生成了相应的噪声稀疏视角正弦图。这些数据直接反映了在图像引导放疗中患者摆位的日常CBCT低剂量和常规剂量条件下的噪声和伪影特性。
Figure
图

Fig. 1. DDoCT: A deep learning dual-domain joint optimization framework for noisy sparse-view CT imaging. The framework leverages the capabilities of projection domain superresolution and image domain wavelet high-frequency fusion provided by deep neural networks. FP and FBP refer to forward projection and filtered back projection, respectively.RFDN-sino and WHF-DN refer to two sub-networks applied in the projection domain stage and image domain stage, respectively
图1. DDoCT: 一种用于噪声稀疏视角CT成像的深度学习双域联合优化框架。该框架利用深度神经网络在投影域超分辨率和图像域小波高频融合中的能力。FP 和 FBP 分别表示前向投影和滤波反投影。RFDN-sino 和 WHF-DN 分别是应用于投影域阶段和图像域阶段的两个子网络。

Fig. 2. The detailed structure of the dual-domain joint optimization framework DDoCT projection domain stage network RFDN-sino and its key modules. (a) Projection domainstage network RFDN-sino in DDoCT. (b) The network structure of EFDB module in RFDN-sino. © DCR: Network structure of dense residual connection block. (d) ESA: Networkstructure of enhanced spatial attention module.
图2. 双域联合优化框架DDoCT中投影域阶段网络RFDN-sino及其关键模块的详细结构。 (a) DDoCT中的投影域阶段网络RFDN-sino。 (b) RFDN-sino中的EFDB模块网络结构。 © DCR:密集残差连接块的网络结构。 (d) ESA:增强空间注意模块的网络结构。

Fig. 3. The detailed structure of the dual-domain joint optimization framework DDoCT image domain stage network WHF-DN and its Spatial module and FEN module. (a) Imagedomain stage network WHF-DN in DDoCT. DWT and IDWT refer to the first-level wavelet transformation and inverse wavelet transformation, respectively. L, H, D, and V representthe low-frequency component, horizontal high-frequency component, diagonal high-frequency component, and vertical high-frequency component, respectively, after the first-levelwavelet transformation. (b) The network structure of the Spatial module in WHF-DN. © The network structure of the FEN module in WHF-DN.
图3. 双域联合优化框架DDoCT中图像域阶段网络WHF-DN的详细结构,以及其空间模块(Spatial module)和特征增强模块(FEN module)。 (a) DDoCT中的图像域阶段网络WHF-DN。DWT和IDWT分别表示一级小波变换和逆小波变换。L、H、D和V分别代表一级小波变换后的低频分量、水平高频分量、对角高频分量和垂直高频分量。 (b) WHF-DN中空间模块(Spatial module)的网络结构。 © WHF-DN中特征增强模块(FEN module)的网络结构。

Fig. 4. The network structure of the wavelet domain feature learning network (WFLN) in WHF-DN
图4. WHF-DN中小波域特征学习网络(WFLN)的网络结构。

Fig. 5. Comparison of visual (together with quantitative results of PSNR and SSIM)and difference images of the Mayo testing dataset. The set range of the display windowis a window level of 40 HU and a window width of 400 HU (i.e., a range from −160HU to 240 HU). As for the difference images of the latter, the set range of the displaywindow is a window level of 0 HU and a window width of 200 HU (i.e., a range from−100 HU to 100 HU).
图5. Mayo测试数据集中视觉效果(以及PSNR和SSIM的定量结果)和差异图像的对比。显示窗口的设置范围为窗位40 HU,窗宽400 HU(即范围为−160 HU到240 HU)。对于后者的差异图像,显示窗口的设置范围为窗位0 HU,窗宽200 HU(即范围为−100 HU到100 HU)。
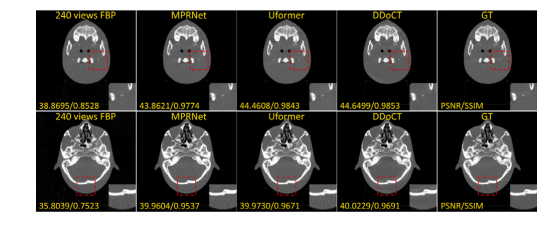
Fig. 6. Comparison of visual (together with quantitative results of PSNR and SSIM)images of the anthropomorphic head phantom dataset, which comprises pairs of CTimages acquired using on-board CBCT scanner with low-dose (80 kV, 100 mA) andhigh-dose (80 kV, 400 mA) settings, respectively. The set range of the display windowis a window level of 500 HU and a window width of 3000 HU (i.e., a range from−1000 HU to 2000 HU)
图6. 仿人头部模体数据集图像的视觉效果对比(包括PSNR和SSIM的定量结果)。该数据集包含使用机载CBCT扫描仪分别在低剂量(80 kV,100 mA)和高剂量(80 kV,400 mA)设置下获取的CT图像对。显示窗口的设置范围为窗位500 HU,窗宽3000 HU(即范围为−1000 HU到2000 HU)。

Fig. 7. The prediction results of different ablation models (together with quantitativeresults of PSNR and SSIM). The set range of the display window is a window levelof 40 HU and a window width of 400 HU (i.e., a range from −160 HU to 240 HU).A1: Learn mapping in the projection domain, directly reconstruct CT with FBP, noimage domain optimization. A2: Mapping learned only in the image domain. Inputis FBP-reconstructed image from noisy sparse-view sinograms 𝑆𝑖 . A3: Main networkbut without forward projection feedback loss and bicubic interpolation loss. A4: Mainnetwork with enhanced pixel-level L2 loss. A5: Main network but without perceptualloss. M: Our full model.
图7. 不同消融模型的预测结果(包括PSNR和SSIM的定量结果)。显示窗口的设置范围为窗位40 HU,窗宽400 HU(即范围为−160 HU到240 HU)。A1:仅在投影域中学习映射,直接通过FBP重建CT图像,无图像域优化。A2:仅在图像域中学习映射,输入为从噪声稀疏视角正弦图 𝑆𝑖 通过FBP重建的图像。A3:主网络,但没有前向投影反馈损失和双三次插值损失。A4:主网络,增强了像素级的L2损失。A5:主网络,但没有感知损失。M:我们的完整模型。
Table
表

Table 1The average PSNR, SSIM, RMSE and VIF results of all 526 simulated noisy sparse-viewsinograms for test patient ‘‘L506’’ in the Mayo dataset
表1 Mayo数据集中测试患者“L506”的所有526个模拟噪声稀疏视角正弦图的平均PSNR、SSIM、RMSE和VIF结果。

Table 2The average PSNR, SSIM, RMSE, and VIF results of the real dose head phantom data.
表2 真实剂量头部模体数据的平均PSNR、SSIM、RMSE和VIF结果。

Table 3Quantitative comparison of different ablation experiments on test patient ‘‘L506’’ in theMayo dataset.
表3 Mayo数据集中测试患者“L506”在不同消融实验中的定量比较结果。