Title
题目
Real-time placental vessel segmentation in fetoscopic laser surgery for Twin-to-Twin Transfusion Syndrome
双胎输血综合征胎镜激光手术中的实时胎盘血管分割
01
文献速递介绍
双胎输血综合征(TTTS)是一个罕见但严重的并发症,影响约10%–15%的单卵双胎妊娠(Lewi等,2008)。当双胎之间的血流不平衡时,就会发生该病症,若未及时治疗,可能导致双胎的严重并发症甚至死亡(Haverkamp等,2001)。该病的发生是由于胎盘中存在异常的血管连接,称为动静脉吻合口,这些吻合口将两个胎儿的血液循环连接起来。在正常的单卵双胎妊娠中,胎盘没有这种吻合口,但在TTTS中几乎总是会出现。病理性的血流不平衡导致一个胎儿(“受体”)获得过多的血液,而另一个胎儿(“供体”)则获得过少的血液(Umur等,2002)。
胎镜激光光凝术(FLP)是一种治疗TTTS的外科手术。该手术通过超声引导将胎镜插入羊水囊,胎儿外科医生定位并用激光烧灼胎盘中异常的血管(动静脉吻合口),如图1所示。研究表明,这一手术能够实现双胎的70%生存率,且超过90%的病例至少有一个胎儿存活(Bamberg和Hecher,2019)。此外,外科医生还会在胎盘赤道沿线进行凝固,划分出供给每个胎儿的区域,这一技术称为Solomon技术(Ruano等,2013)。该技术可以最大限度地减少手术后发生双胎贫血多血症序列(TAPS)的风险(Bamberg和Hecher,2019),TAPS可能导致心力衰竭和大脑损伤等严重并发症。
准确检测和识别胎盘血管是FLP手术成功的关键,有助于减少TAPS或早产等手术并发症的风险(Chalouhi等,2011,Baschat等,2013)。然而,胎盘血管的可视性可能受到羊水囊内环境浑浊、纹理可视性差、图像分辨率低、非平面视角(尤其是前置胎盘)、胎儿和烧灼工具遮挡以及突出的高光影响,使得外科医生难以准确靶向异常血管。因此,改善胎盘血管的检测和识别可能会显著提高治疗的成功率。
先前的研究已涉及胎盘血管的分割,但这些研究大多依赖于体外图像,而经典的计算机视觉算法可能无法满足临床应用的要求(Almoussa等,2011,Chang等,2013)。近年来,深度学习算法作为一种有前景的胎盘血管分割方法逐渐受到关注。Sadda等(2019)提出了首个基于深度学习的解决方案,利用10例TTTS手术中的345帧体内视频图像,采用了U-Net网络架构。Bano等(2020)进一步探索了这一方法,通过测试不同版本的U-Net和不同的主干网络(VGG-16、ResNet-50和ResNet-101),通过使用更大的主干网络(ResNet-101)来改进分割效果,并在6例独立的TTTS手术中,使用483帧体内视频图像对算法的性能和鲁棒性进行了评估。
为促进该领域的研究,FetReg2021(Bano等,2021,Bano等,2023)数据集作为内窥镜视觉挑战的一部分发布。该数据集来自两个中心,包含24例TTTS手术中的2717帧体内视频图像,为开发鲁棒且具有广泛适用性的模型提供了宝贵的资源。因此,我们利用FetReg2021数据集,保持其原始分布,用于训练和测试我们的方法。然而,前述方法计算开销较大,这使得它们在实时应用中不太实际。此外,我们注意到公开数据集中存在标注不一致的情况(Bano等,2021,Bano等,2023)。这些不一致之处包括在视野边缘不准确的胎盘血管标注或遗漏的小血管。我们在本研究中由专家胎儿外科医生手动修正了这些标注,并调查了这些修正对胎盘血管分割性能的影响。
该领域的研究仍受到专家注释数据集的有限可用性限制,这些数据集需从多种手术环境中收集,以捕捉这种变异性。这一限制主要源于TTTS的发生频率较低,导致系统性数据收集困难,同时缺乏足够的具有临床准确标注经验的标注者。因此,前述方法的评估主要基于来自两个临床中心的小规模数据集。这种数据集缺乏多样性,可能限制了它们在新数据上的泛化能力和分割性能。为了解决这些问题,我们总结了以下贡献:受实时分析需求和计算效率与分割性能之间的最佳权衡的启发,我们改进了最先进的轻量级分割神经网络——DABNet和LMFFNet。我们在多尺度特征融合和注意力机制方面进行了修改,以增强FLP治疗TTTS过程中胎盘血管的可视性。多尺度方法使网络能够有效地捕捉血管的细粒度和粗粒度细节,同时保持计算效率,实现实时分析。此外,通道注意力机制使网络能够专注于图像中最重要的区域,从而进一步提高分割性能。为应对羊水囊内环境差和其他伪影问题,我们提出了新的数据增强方法,模拟了激光指示器效应、羊水颗粒、相机结构缺陷和纤维伪影等问题。
为促进该领域的研究,我们引入并发布了一个新的全面的专家注释数据集,该数据集包括来自欧洲四个胎儿医学中心的数据。该数据集包含18例TTTS手术中的1690帧体内视频图像。据我们所知,这是目前为止最具多样性的FLP治疗TTTS过程中的内窥镜视频帧数据集。我们使用公开可用的FetReg2021数据集(Bano等,2021,Bano等,2023)开发我们的方法。我们识别出该数据集中的标注不一致之处,并由专家胎儿外科医生进行修正。我们展示了在修正后的数据集上训练的模型在泛化能力方面的增强。最后,我们将这些改进后的标注发布给社区。本文的其余部分组织如下:第二部分介绍方法和实现细节,第三部分描述数据,第四和第五部分分别展示实验设计和结果,第六部分讨论结果,第七部分为总结。
Aastract
摘要
Twin-to-Twin Transfusion Syndrome (TTTS) is a rare condition that affects about 15% of monochorionicpregnancies, in which identical twins share a single placenta. Fetoscopic laser photocoagulation (FLP) is thestandard treatment for TTTS, which significantly improves the survival of fetuses. The aim of FLP is to identifyabnormal connections between blood vessels and to laser ablate them in order to equalize blood supply to bothfetuses. However, performing fetoscopic surgery is challenging due to limited visibility, a narrow field of view,and significant variability among patients and domains. In order to enhance the visualization of placentalvessels during surgery, we propose TTTSNet, a network architecture designed for real-time and accurateplacental vessel segmentation. Our network architecture incorporates a novel channel attention module andmulti-scale feature fusion module to precisely segment tiny placental vessels. To address the challenges posedby FLP-specific fiberscope and amniotic sac-based artifacts, we employed novel data augmentation techniques.These techniques simulate various artifacts, including laser pointer, amniotic sac particles, and structural andoptical fiber artifacts. By incorporating these simulated artifacts during training, our network architecturedemonstrated robust generalizability. We trained TTTSNet on a publicly available dataset of 2060 video framesfrom 18 independent fetoscopic procedures and evaluated it on a multi-center external dataset of 24 in-vivoprocedures with a total of 2348 video frames. Our method achieved significant performance improvementscompared to state-of-the-art methods, with a mean Intersection over Union of 78.26% for all placental vesselsand 73.35% for a subset of tiny placental vessels. Moreover, our method achieved 172 and 152 frames persecond on an A100 GPU, and Clara AGX, respectively. This potentially opens the door to real-time applicationduring surgical procedures.
双胎输血综合征 (TTTS) 是一种罕见的疾病,影响约 15% 的单绒毛膜妊娠(单卵双胞胎共享一个胎盘)。胎镜激光光凝术 (FLP) 是治疗 TTTS 的标准方法,显著提高了胎儿的存活率。FLP 的目标是识别血管之间的异常连接,并通过激光消融这些连接,从而平衡两个胎儿的血液供应。然而,由于可见度有限、视野狭窄,以及患者和手术领域的显著差异性,实施胎镜手术面临很大挑战。
为了增强手术过程中胎盘血管的可视化,我们提出了 TTTSNet,一种专为实时精确胎盘血管分割设计的网络架构。该网络架构结合了新颖的通道注意力模块和多尺度特征融合模块,可精准分割细小的胎盘血管。为应对 FLP 特有的纤维内窥镜及羊膜囊相关伪影所带来的挑战,我们采用了创新的数据增强技术。这些技术模拟了多种伪影,包括激光指示点、羊膜囊颗粒,以及结构性和光纤伪影。在训练过程中引入这些模拟伪影,使我们的网络架构展现出强大的泛化能力。我们在一个包含来自 18 次独立胎镜手术的 2060 帧视频的公开数据集上训练了 TTTSNet,并在一个多中心外部数据集上进行了评估,该数据集包含 24 次体内手术的 2348 帧视频。与现有的最先进方法相比,我们的方法实现了显著的性能提升,在所有胎盘血管上的平均交并比 (IoU) 达到 78.26%,在细小胎盘血管子集上的平均交并比达到 73.35%。此外,我们的方法在 A100 GPU 和 Clara AGX 上分别实现了每秒 172 帧和 152 帧的速度。这为手术过程中的实时应用提供了可能性。
Method
方法
This section presents our network architecture, TTTSNet, for realtime placental vessel segmentation for TTTS surgery. Our approach includes an asymmetric encoder–decoder neural network, feature fusionmodule, and channel-attention mechanism. Additionally, we introducenovel data augmentation approaches to increase the robustness andgeneralizability of the trained model against artifacts.
本节介绍了我们的网络架构 TTTSNet,用于 TTTS 手术中实时胎盘血管分割。我们的方法包括一个非对称的编码器–解码器神经网络、特征融合模块和通道注意力机制。此外,我们引入了新颖的数据增强方法,以提高训练模型对伪影的鲁棒性和泛化能力。
Conclusion
结论
We have proposed a network architecture for real-time placental vessel segmentation in videos obtained during FLP for TTTS. Toimprove performance, we have developed custom network and dataaugmentations specifically tailored for this task. Our experiments ona large and diverse test set have shown that TTTSNet is not onlyaccurate in terms of segmentation metric but also robust in terms ofgeneralizability to datasets from different institutions. Furthermore, ourmethod demonstrates superior performance compared to current stateof-the-art methods. In the future, the use of TTTSNet may aid surgeonsduring real-time fetoscopic fetal surgery to accurately identify criticalstructures and ultimately improve outcomes of TTTS treatments.
我们提出了一种网络架构,用于在 TTTS 胎镜激光光凝术(FLP)过程中获得的视频中实现实时胎盘血管分割。为提升性能,我们开发了专门针对这一任务的自定义网络架构和数据增强方法。
在一个规模大且多样化的测试集上的实验表明,TTTSNet 不仅在分割指标上表现出色,同时在对不同机构数据集的泛化能力方面也具有很强的鲁棒性。此外,与当前最先进的方法相比,我们的方法表现出更优越的性能。
未来,TTTSNet 的使用或将帮助外科医生在实时胎镜手术中准确识别关键结构,从而最终改善 TTTS 治疗的效果。
Results
结果
This section presents the results of two ablation studies conductedto demonstrate the impact of each key component in the proposedTTTSNet, along with the custom data augmentations, the results of placental vessel segmentation, and comparison with FetReg2021 challengesolutions.
本节展示了两项消融研究的结果,用于说明提出的 TTTSNet 中每个关键组件的影响,以及自定义数据增强的效果。同时,还包括胎盘血管分割的结果及其与 FetReg2021 挑战解决方案 的对比分析。
Figure
图
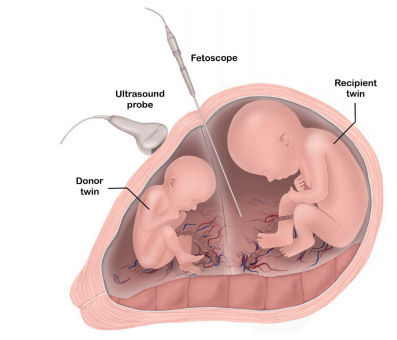
Fig. 1. An overview of FLP for TTTS. Twin fetuses, each within their own amnioticsac, are shown. The monochorionic twin pregnancy is characterized by a single sharedplacenta, typically with vascular connections that allow an exchange of blood betweentwins. A fetoscope is used to inspect the placental vessels and find pathologicalconnections which cause an imbalance in blood exchange. When such connections areidentified, they are coagulated using laser light. An ultrasound probe is typically usedto guide the insertion of the fetoscope.
图 1. TTTS 胎镜激光光凝术(FLP)概述图中展示了每个胎儿位于各自羊膜囊中的双胎妊娠。单绒毛膜双胎妊娠的特点是胎儿共享一个胎盘,通常伴有允许双胎之间血液交换的血管连接。胎镜用于检查胎盘血管并发现导致血液交换失衡的病理性连接。一旦发现此类连接,即通过激光进行凝固。超声探头通常用于引导胎镜的插入过程。
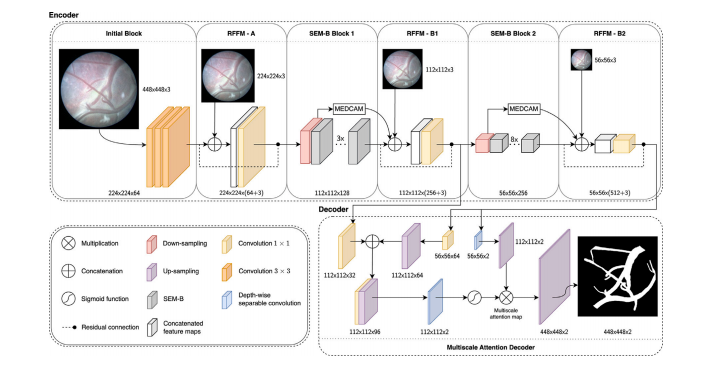
Fig. 2. An overview of the TTTSNet network architecture for real-time placental vessel segmentation during FLP for TTTS. The TTTSNet is designed as an asymmetric encoder–decoder neural network, taking a three-channel RGB input image and producing binary segmentation maps as output. In the encoder part, TTTSNet consists of the Initial Block,Residual Feature Fusion Module (RFFM) blocks, and Split-Extract-Merge Bottleneck (SEM-B) blocks, including a channel-attention mechanism called Max Pooled Channel-AttentionMechanism (MEDCAM). The encoder part allows the extraction of contextual features with low computational complexity, allowing efficient and fast processing with a few modelparameters. In RFFM modules, a ∙ preceded with the dashed line denotes residual connections, which aid the model in learning complex features without increasing the numberof model parameters In the decoder part, we use the lightweight Multi-scale Attention Decoder (MAD). The MAD, with its multi-scale attention mechanism, allows the decoder toeffectively recover spatial feature representation by using a minimal number of parameters
图 2. TTTSNet 网络架构概述:用于 TTTS 胎镜激光光凝术(FLP)过程中实时胎盘血管分割TTTSNet 被设计为非对称的编码器–解码器神经网络,接受三通道 RGB 输入图像并输出二值分割图。编码器部分 包括初始块(Initial Block)、残差特征融合模块(Residual Feature Fusion Module,RFFM)和分离-提取-合并瓶颈模块(Split-Extract-Merge Bottleneck,SEM-B),其中结合了一个通道注意力机制,称为最大池化通道注意力机制(Max Pooled Channel-Attention Mechanism,MEDCAM)。编码器部分通过低计算复杂度提取上下文特征,从而实现高效、快速的处理,同时保持较少的模型参数量。在 RFFM 模块中,带有虚线的“∙”表示残差连接,有助于模型学习复杂特征而不增加模型参数数量。解码器部分 使用轻量化多尺度注意力解码器(Multi-scale Attention Decoder,MAD)。MAD 的多尺度注意力机制使解码器能够以最少的参数数有效恢复空间特征表示。
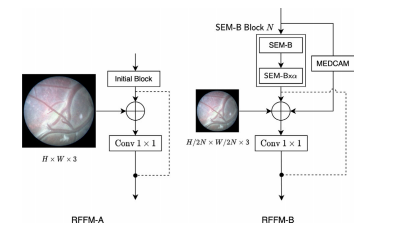
Fig. 3. Proposed RFFM preserves the identity function to aid the model in learningcomplex features without increasing the number of model parameters. In RFFM-A, weconcatenate an identity path of input block features and process with convolution 1 × 1concatenated features of the raw image and Initial Block. In RFFM-B, processed inputfeature maps are concatenated to the output of the SEM-Bs, down-sampled raw image,MEDCAM’s output, and residual connection of input feature maps. The SEM-B Block 𝑁bounded in the dashed box comprises (𝛼+ 1) SEM-Bs, where 𝑁 corresponds to block1 or 2
图 3. 提出的 RFFM 模块通过保留身份函数,帮助模型学习复杂特征而无需增加模型参数数量。在 RFFM-A 中,我们将输入块特征的身份路径与原始图像和初始块(Initial Block)的特征通过 1 × 1 卷积进行拼接处理。在 RFFM-B 中,处理后的输入特征图与 SEM-B 模块的输出、下采样的原始图像、MEDCAM 的输出以及输入特征图的残差连接进行拼接。虚线框内的 SEM-B Block𝑁 包括 (𝛼 + 1) 个 SEM-B,其中 𝑁 对应于块 1 或块 2。
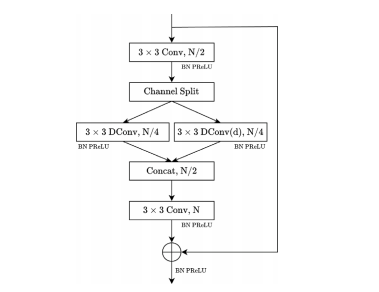
Fig. 4. Architecture of the SEM-B structure. The SEM-B starts with a 3 × 3 convolution(Conv) that is applied to extract feature maps and reduce the number of input channelsby half. The output of this convolution is then split into two branches, consisting of adepth-wise convolution (DConv) and a depth-wise dilated convolution (DConv(d)). Tofuse multi-scale feature maps, a 3 × 3 convolution is utilized. Batch Normalization (BN)and PReLU activation are applied after every convolutional operation. The module’soutput concatenates the last convolutional layer’s output and the identity of the inputfeature map. 𝑁, and ⊕ denote the number of feature channels and concatenation,respectively
图 4. SEM-B 结构的架构SEM-B 结构以一个 3 × 3 卷积(Conv)开始,用于提取特征图并将输入通道数减半。卷积的输出随后分为两个分支:深度卷积(Depth-wise Convolution,DConv)和深度扩张卷积(Depth-wise Dilated Convolution,DConv(d))。为了融合多尺度特征图,使用了一个 3 × 3 卷积。每次卷积操作后均应用批归一化(Batch Normalization, BN)和 PReLU 激活函数。模块的输出将最后一层卷积的输出与输入特征图的身份连接进行拼接。符号 𝑁 表示特征通道的数量,⊕ 表示拼接操作。
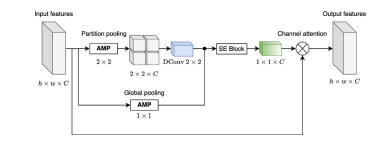
Fig. 5. The proposed MEDCAM module architecture. We utilize Adaptive Max Pooling(AMP) globally and on partitioned feature maps to leverage multi-scale features whilepreserving vessel details. The weighted sum is applied to the partition-pooled featurevector through learned depth-wise convolutional filters, focusing more on specificspatial partitions among channels. Squeeze Excitation (SE) Block allows for dynamicchannel-wise feature re-calibration, resulting in the meaningful channel attention vectorfinally being applied to input features. The MEDCAM utilizes a channel attentionmechanism to focus on specific feature channels and capture important informationabout tiny placenta vessels. ℎ, 𝑤, 𝐶, ⊗ denote feature map height, and width, numberof channels, and multiplication, respectively
图 5. 提出的 MEDCAM 模块架构我们在全局和分区特征图上使用自适应最大池化(Adaptive Max Pooling, AMP),以利用多尺度特征,同时保留血管细节。通过深度卷积滤波器的加权求和对分区池化特征向量进行处理,从而更关注通道之间特定空间分区的特征。压缩-激励(Squeeze Excitation, SE)块 实现动态的通道特征重新校准,生成有意义的通道注意力向量,最终应用于输入特征。MEDCAM 模块利用通道注意力机制,聚焦于特定特征通道,从而捕获关于细小胎盘血管的重要信息。符号 ℎ、𝑤、𝐶 和 ⊗ 分别表示特征图的高度、宽度、通道数和乘法操作。

Fig. 6. A summary of the custom data augmentations is presented. Four examples ofdifferent data augmentations are shown in each row, including laser pointer, amnioticsac particles, structural defects, and optical fiber artifacts. The images depict the inputimage on the left, the real artifact in the middle, and the artificial artifact on the right.
图 6. 自定义数据增强方法的汇总每行展示了不同数据增强的四个示例,包括激光指示点、羊膜囊颗粒、结构缺陷以及光纤伪影。图像从左到右依次为输入图像、真实伪影和人工生成的伪影。

Fig. 7. Examples of corrected annotations: The input (left), original annotation (middle), and corrected annotation (right). Dotted circles emphasize inaccurate annotations,and arrows pinpoint labeling inconsistencies such as annotations beyond the field ofview or not adhering to the edge. The first row illustrates an annotation that failedto fill in the gaps. In the second row, inaccurately delineated edges of the placentalvessel are emphasized. The third row demonstrates the discontinuous annotation ofvessels resulting from amniotic sac particle artifacts. The fourth row shows omitted bigplacental vessels. Lastly, the final row exhibits omitted small placental vessels.
图 7. 修正标注示例图中展示了输入图像(左)、原始标注(中)和修正后标注(右)。虚线圆圈标出不准确的标注,箭头指示了标注中的不一致性,例如标注超出视野范围或未遵循边缘规则。第一行:展示未填补标注空隙的情况;
第二行:强调胎盘血管边缘的不准确标注;第三行:显示因羊膜囊颗粒伪影导致的血管标注不连续;第四行:展示遗漏的大胎盘血管;最后一行:展示遗漏的小胎盘血管的情况。

Fig. 8. Representative video frames from the training set from Center A and Center B. Each row illustrates five consecutive data samples extracted from a single video. In total90 video frames from 18 independent in-vivo TTTS procedures are presented.
图 8. 来自训练集的代表性视频帧(中心 A 和中心 B)
每行展示了从单个视频中提取的五个连续数据样本。图中共展示了来自 18 次独立体内 TTTS 手术的 90 帧视频样本。

Fig. 9. Representative video frames from the test set from four centers – Center C, through Center F. Each row illustrates five consecutive data samples extracted from a singlevideo. In total 120 video frames from 24 independent in-vivo TTTS procedures are presented
图 9. 测试集中来自四个中心(中心 C 至中心 F)的代表性视频帧每行展示了从单个视频中提取的五个连续数据样本。图中共展示了来自 24 次独立体内 TTTS 手术的 120 帧视频样本。

Fig. 10. A qualitative comparison of the impact of the MEDCAM module on thesegmentation of placental vessels. Each row shows an example from the test set. Inputimage, ground truth, MEDCAM, and without attention module are presented from leftto right, respectively
图 10. MEDCAM 模块对胎盘血管分割影响的定性比较。 每行展示了测试集中的一个示例。从左至右依次为:输入图像、真实标注、含有 MEDCAM 模块的分割结果以及无注意力模块的分割结果。

Fig. 11. Examples of segmentation results obtained on the test set by our proposed TTTSNet model, compared with several state-of-the-art methods and two TTTSNet-basedconfigurations. Ground truth is abbreviated as GT. TTTSNet★ denotes TTTSNet trained on original pixel-wise annotations provided by the FetReg2021 challenge. The images arearranged in order of the best overall score, with the best results on the left. Each row corresponds to a different video, and each column shows the input image, ground truth,results of TTTSNet, and results of other state-of-the-art methods
图 11. 测试集中 TTTSNet 模型与多种先进方法及两种 TTTSNet 配置的分割结果对比示例图中展示了测试集中分割结果的对比,包括我们提出的 TTTSNet 模型、几种先进方法,以及两种基于 TTTSNet 的配置。Ground truth(GT) 表示真实标注,TTTSNet★ 表示在 FetReg2021 挑战提供的原始像素级标注上训练的 TTTSNet。 图像按照整体评分最佳的顺序排列,最佳结果位于最左侧。每行对应不同的视频,每列依次展示输入图像、真实标注、TTTSNet 的结果,以及其他先进方法的结果。
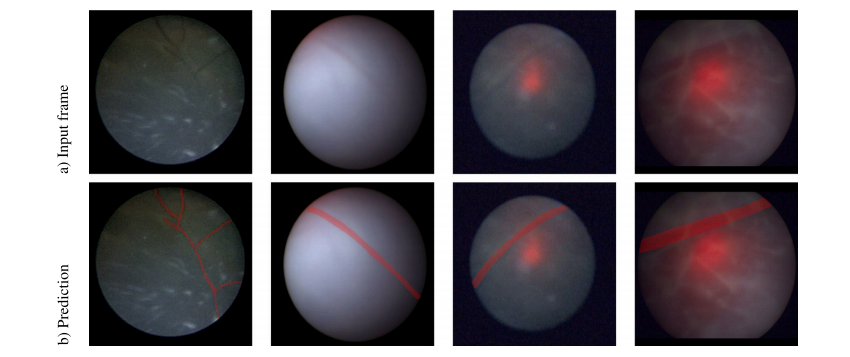
Fig. 12. Examples of poor visibility in video frames and their corresponding overlay prediction mask of placental vessels. The first row shows input video frames, and the secondrow shows the overlay prediction mask of placental vessels. Here, we demonstrate how a deep learning-based model may improve the visibility of placental vessels to assist fetalsurgeons during TTTS fetoscopic surgery
图 12. 视频帧中可见性较差的示例及其相应的胎盘血管预测覆盖图第一行展示了输入视频帧,第二行展示了胎盘血管的预测覆盖图。在此,我们展示了深度学习模型如何改善胎盘血管的可见性,从而在 TTTS 胎镜手术中为胎儿外科医生提供辅助

Fig. 13. Examples of video frames from two types of the placenta: (a) anterior, and (b) posterior placenta. We demonstrate that anterior placenta cases exhibit better visibility of placental vessels within the field of view compared to posterior cases, which impacts the segmentation performance of both types.
图 13. 两种胎盘类型的视频帧示例:(a) 前置胎盘,(b) 后置胎盘我们展示了前置胎盘病例在视野内胎盘血管的可见性优于后置胎盘病例,这种差异对两种类型的分割性能产生了影响。
Table
表

Table 1The total number of videos and video frames from each of the six centers usedfor training and testing.
表 1各中心用于训练和测试的视频及视频帧总数表中列出了来自六个中心的视频数量和视频帧数量,分别用于训练和测试的数据集。

Table 2Experimental results of ablation study with different approaches to each of keycomponents of TTTSNet. The results of the test set are presented. The first row isthe result of the baseline neural network as a part of TTTSNet, and the rest three rowsrefer to additional components added to the baseline.
表 2 TTTSNet 各关键组件不同方法的消融实验结果
表中展示了测试集上的实验结果:第一行为作为 TTTSNet 基线神经网络的结果;其余三行为在基线的基础上逐步添加额外组件后的结果。

Table 3Experimental results of ablation study with different approaches to custom data augmentation methods used forTTTSNet training. The results of the test set are presented. We listed five different approaches. The first row wasthe result of TTTSNet trained without any custom data augmentations as the baseline, and the other four rows referto progressively adding each type of data augmentation.
表 3 使用不同自定义数据增强方法训练 TTTSNet 的消融研究实验结果。本表展示了测试集的结果,共列出了五种不同的方法。第一行为未使用任何自定义数据增强的 TTTSNet 训练结果,作为基线;其余四行则表示逐步添加每种类型数据增强后的实验结果。

Table 4A summary of the number of parameters in millions, inference speed on both A100 GPU (GPU) and Clara AGX (Clara) hardware in FPS, and values of mIoU(%) for placental vessel segmentation obtained with different state-of-the-art methods computed using the test set. Each column shows the method, results perCenter, as well as overall results. All methods were compared with the same image size of 448 × 448 pixels. The 𝑝-value indicates the pairwise comparison ofthe significance between TTTSNet and each method. The results are in order of the segmentation performance. The best results are bolded.
表4 以百万为单位汇总了不同先进方法在A100 GPU(GPU)和Clara AGX(Clara)硬件上的推理速度(以FPS为单位)以及使用测试集计算的血管分割mIoU(%)。 每列显示了方法、每个中心的得分以及总体得分。 所有方法都以448×448像素的图像大小进行比较。 p-值表示TTTSNet与每种方法之间的成对比较的显著性。 结果按分割性能排列。 最佳结果加粗显示。

Table 5A summary of values of mIoU (%) for tiny placental vessel segmentation obtained with different state-of-the-art methodscomputed using the test set. Each column shows the method, results per Center, as well as overall results. All methods werecompared with the same image size of 448 × 448 pixels. The 𝑝-value indicates the pairwise comparison of the significancebetween TTTSNet and each method. The results are in order of the segmentation performance. The best results are bolded.
表 5 测试集中不同先进方法用于细小胎盘血管分割的 mIoU(%)汇总表中展示了使用测试集计算得到的 mIoU 值(%)。每列显示了具体方法、各中心的结果,以及总体结果。所有方法均基于相同的图像大小(448 × 448 像素)进行对比分析。𝑝-值表示 TTTSNet 与各方法之间显著性配对比较的结果。表中按分割性能排序,最佳结果以加粗显示。
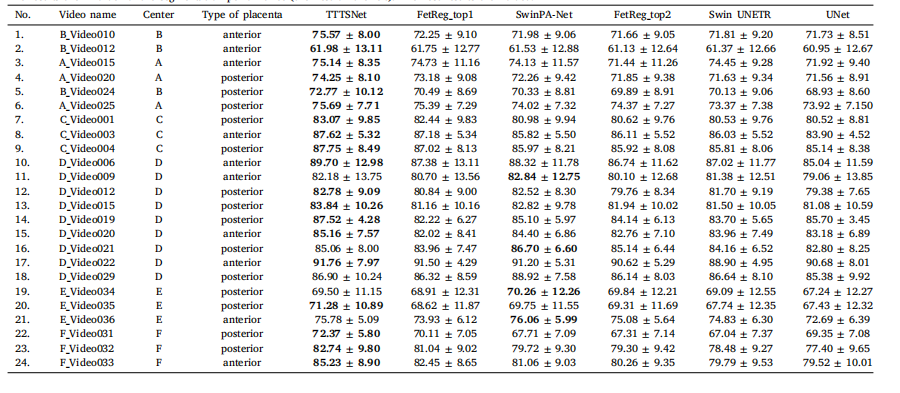
Table 6A summary of values of mIoU (%) ± standard deviation for TTTSNet and the next top 5 performing methods per each video from the test set. Each column shows the videoname, Center, type of placenta and method. All methods were compared with the same image size of 448 × 448 pixels and the same training settings, i.e. data augmentations.The results are in order of the segmentation performance (the best on the left). The best results are bolded
表 6 TTTSNet 与测试集中前 5 种最佳方法的每段视频 mIoU(%)± 标准差汇总表中列出了每段测试视频的 mIoU(%)及其标准差,分别针对 TTTSNet 和前 5 种性能最佳方法。每列展示了视频名称、中心、胎盘类型以及方法。所有方法均基于相同的图像大小(448 × 448 像素)和一致的训练设置(即相同的数据增强)进行比较。结果按分割性能排序,最佳结果位于最左侧并以加粗显示。
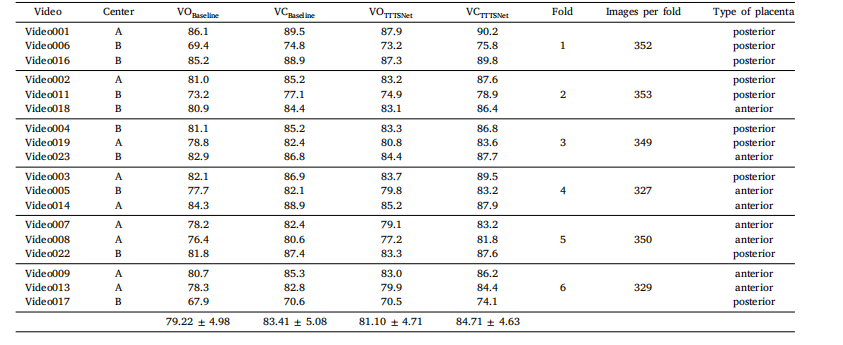
Table 7Results of six-fold cross-validation for both baseline and TTTSNet methods on original and corrected annotations. Vessel Original and Vessel Corrected classesare abbreviated as VO and VC, respectively.
表 7 基线方法与 TTTSNet 方法在原始标注和修正标注上的六折交叉验证结果表中展示了基线方法与 TTTSNet 方法在原始标注(VO,Vessel Original)和修正标注(VC,Vessel Corrected)类别上的六折交叉验证结果。

Table 8A summary of the values of mIoU (%) for TTTSNet and the top 5 performing methods from the FetReg2021 challenge. We provide placental vessel segmentation performancefor each Center, as well as overall results for both original and corrected annotations. All methods were compared using the same image size of 448 × 448 pixels and the sametraining settings, i.e., data augmentations. The results are ordered by segmentation performance, with the best results bolded
表 8 TTTSNet 与 FetReg2021 挑战中前 5 种最佳方法的 mIoU(%)汇总表中列出了胎盘血管分割性能的 mIoU 值,分别针对每个中心以及总体结果,并对比了原始标注和修正标注的结果。所有方法均基于相同的图像大小(448 × 448 像素)和一致的训练设置(即相同的数据增强)进行比较。结果按分割性能排序,最佳结果以加粗显示。